我关于Haswell微架构(Intel Xeon E5-2640-v3 CPU)有一个问题。从CPU规格和其他资源中,我发现有10个LFB和超级队列的大小为16。我有两个与LFB和SuperQueues相关的问题:
1) 系统能够提供的最大内存级别并行度是多少?10还是16(LFB或SQ)?
2) 根据一些来源,每个L1D缺失都记录在SQ中,然后SQ分配Line fill buffer,而在其他一些来源中,他们写道SQ和LFB可以独立工作。您能否简要解释一下SQ的工作原理?
这里是SQ和LFB的示例图(不适用于Haswell)。
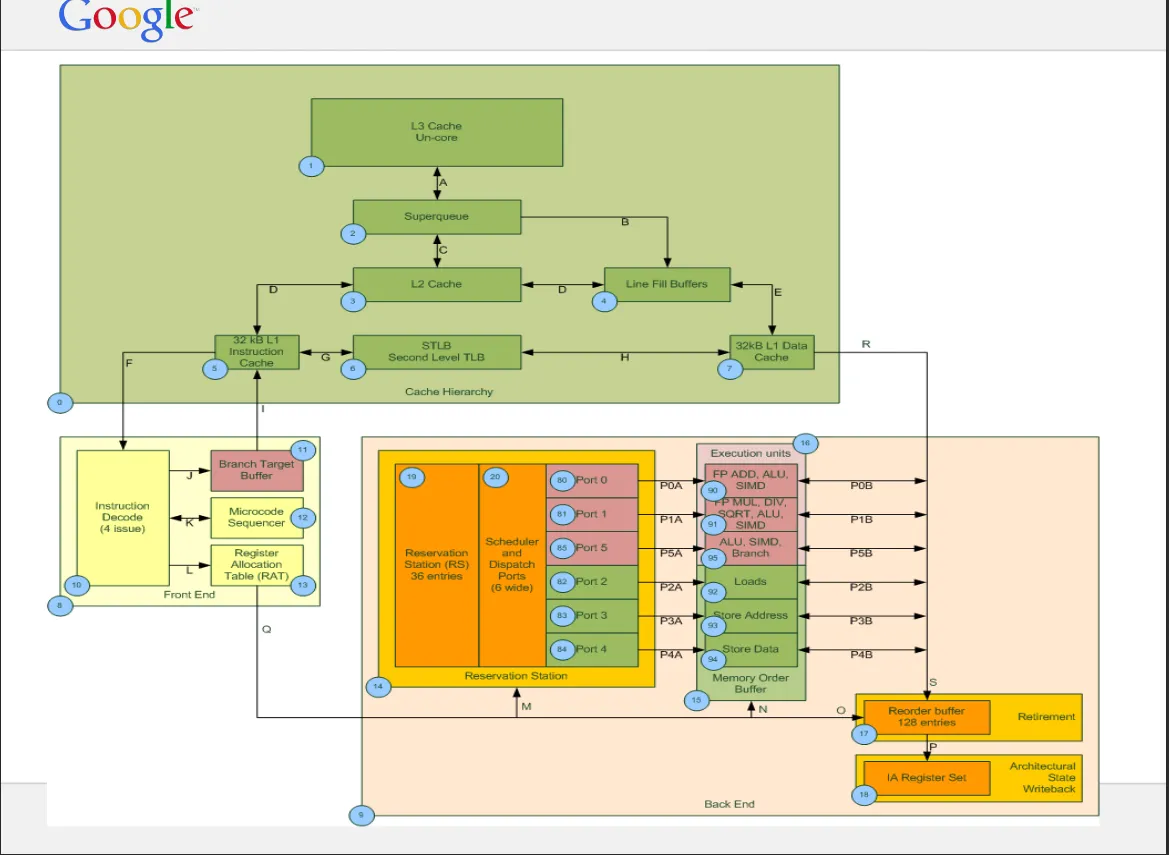 参考资料:
https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf
参考资料:
https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf