我不确定我是否100%理解了你的问题,但我猜测你有一个数据集中缺失一些名称,并且希望快速识别变量之间的关系(可能是线性关系),识别“主成分”?
这是一个非常棒的
交叉验证帖子,向您展示PCA和SVD的一些知识。
这里有一个非常简单的例子,向您展示如何使用
prcomp函数:
>library(ggplot2)
>data(mpg)
>data <- mpg[,c("displ", "year", "cyl", "cty", "hwy")]
>prcomp(data, scale=TRUE)
Standard deviations:
[1] 1.8758132 1.0069712 0.5971261 0.2658375 0.2002613
Rotation:
PC1 PC2 PC3 PC4 PC5
displ 0.49818034 -0.07540283 0.4897111 0.70386376 -0.10435326
year 0.06047629 -0.98055060 -0.1846807 -0.01604536 0.02233245
cyl 0.49820578 -0.04868461 0.5028416 -0.68062021 0.18255766
cty -0.50575849 -0.09911736 0.4348234 0.15195854 0.72264881
hwy -0.49412379 -0.14366800 0.5330619 -0.13410105 -0.65807527
以下是您如何解释结果:
(1)标准差,即奇异值分解时应用的中间对角矩阵。解释了每个“主成分”/层/透明度在矩阵的整体方差中解释了多少方差。
例如,
70 % = 1.8758132^2 / (1.8758132^2 + 1.0069712^2 + 0.5971261^2 + 0.2658375^2 + 0.2002613^2)
这意味着第一列本身已经解释了整个矩阵的70%变异性。
(2) 现在让我们看一下旋转矩阵/V中的第一列:
PC1
displ 0.49818034
year 0.06047629
cyl 0.49820578
cty -0.50575849
hwy -0.49412379
我们可以看到:
displ 与
cyl 呈正相关,与
cty 和
hwy 呈负相关。在这个主导层中,
year 并不是很明显。
更大的排量或气缸数可能会让您的汽车有更高的平均每加仑英里数(MPG),这是有道理的。
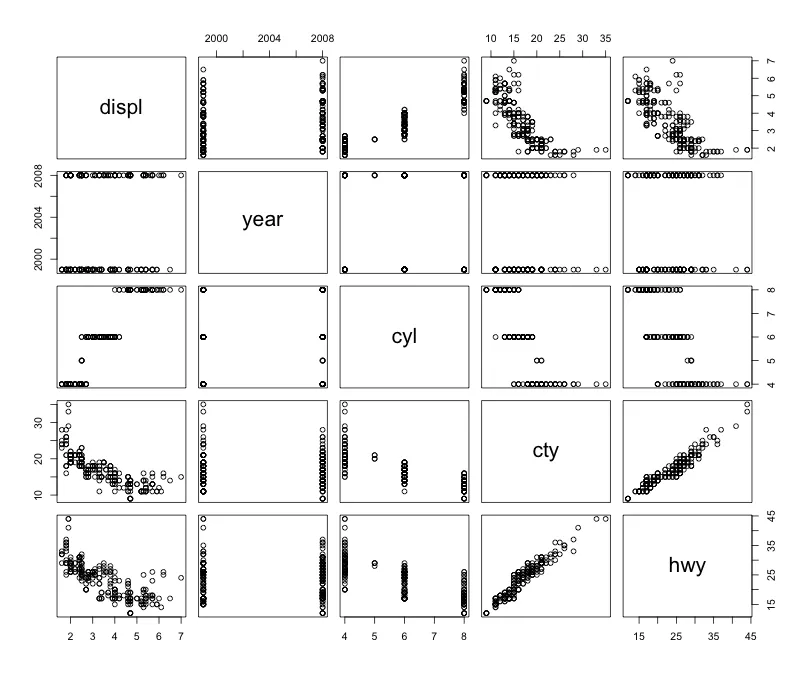
以下是变量之间的图表,供您参考。
pairs(data)