我们需要将一个遗留的POI数据库从MySQL迁移到PostgreSQL。目前,所有实体都有80-120+个属性,代表各自的属性。
我们被要求考虑灵活性以及新数据库的良好设计方法。但是新设计应该允许:
- 任何实体的属性/属性数量为,即任何实体的属性数量不固定,可能会经常更改。 - 允许内容管理员通过管理界面 "on the fly" 添加新属性到现有实体中,而不是一直更改数据库模式。
关于EAV的性能问题有很多讨论,但如果我们不使用混合-EAV,则会出现以下问题:
- 有大量空列(即使99%的数据没有这些属性,我们仍会添加新列) - 在属性不断变化时,花费更多时间维护数据库。 - 没有办法允许内容管理员向现有实体添加新属性
无论如何,这里是我们对新设计的想法(包括基本ERD):
- 对于每个实体都有单独的表,包含一些独有的基本信息,例如id、名称、地址、联系方式、创建日期等等。 - 有两个表,即属性类型和属性表,用于存储属性信息。 - 使用多对多关系将每个实体与属性相关联。 - 将地址存储在不同的表中,并使用外键链接到实体。
然而,这种设计会导致获取数据时连接数量增加。例如,为了显示给定体育场的所有“属性”,我们可能需要进行20多个连接查询以在单行中获取所有相关属性。
您对这种设计有什么想法?您有什么建议来改进它?
感谢您的阅读。
我们被要求考虑灵活性以及新数据库的良好设计方法。但是新设计应该允许:
- 任何实体的属性/属性数量为,即任何实体的属性数量不固定,可能会经常更改。 - 允许内容管理员通过管理界面 "on the fly" 添加新属性到现有实体中,而不是一直更改数据库模式。
关于EAV的性能问题有很多讨论,但如果我们不使用混合-EAV,则会出现以下问题:
- 有大量空列(即使99%的数据没有这些属性,我们仍会添加新列) - 在属性不断变化时,花费更多时间维护数据库。 - 没有办法允许内容管理员向现有实体添加新属性
无论如何,这里是我们对新设计的想法(包括基本ERD):
- 对于每个实体都有单独的表,包含一些独有的基本信息,例如id、名称、地址、联系方式、创建日期等等。 - 有两个表,即属性类型和属性表,用于存储属性信息。 - 使用多对多关系将每个实体与属性相关联。 - 将地址存储在不同的表中,并使用外键链接到实体。
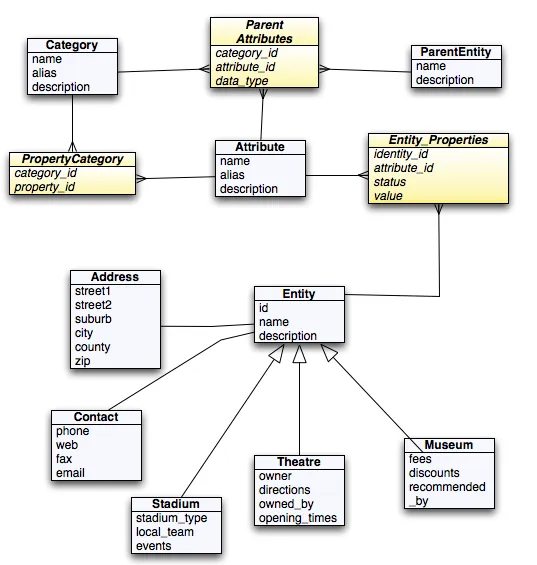
然而,这种设计会导致获取数据时连接数量增加。例如,为了显示给定体育场的所有“属性”,我们可能需要进行20多个连接查询以在单行中获取所有相关属性。
您对这种设计有什么想法?您有什么建议来改进它?
感谢您的阅读。