请看下面的截图,看看你能否告诉我为什么这样做不起作用。在TextRecognize的参考页面上的示例看起来相当不错。我认为识别这样的单个字母不应该是一个问题。我尝试过调整字母的大小以及让图像变得更清晰。
为方便起见,如果您想自己尝试,请查看本帖子底部使用的图像。您还可以通过在Google图像搜索中搜索“Wordfeud”来找到更多类似的图像。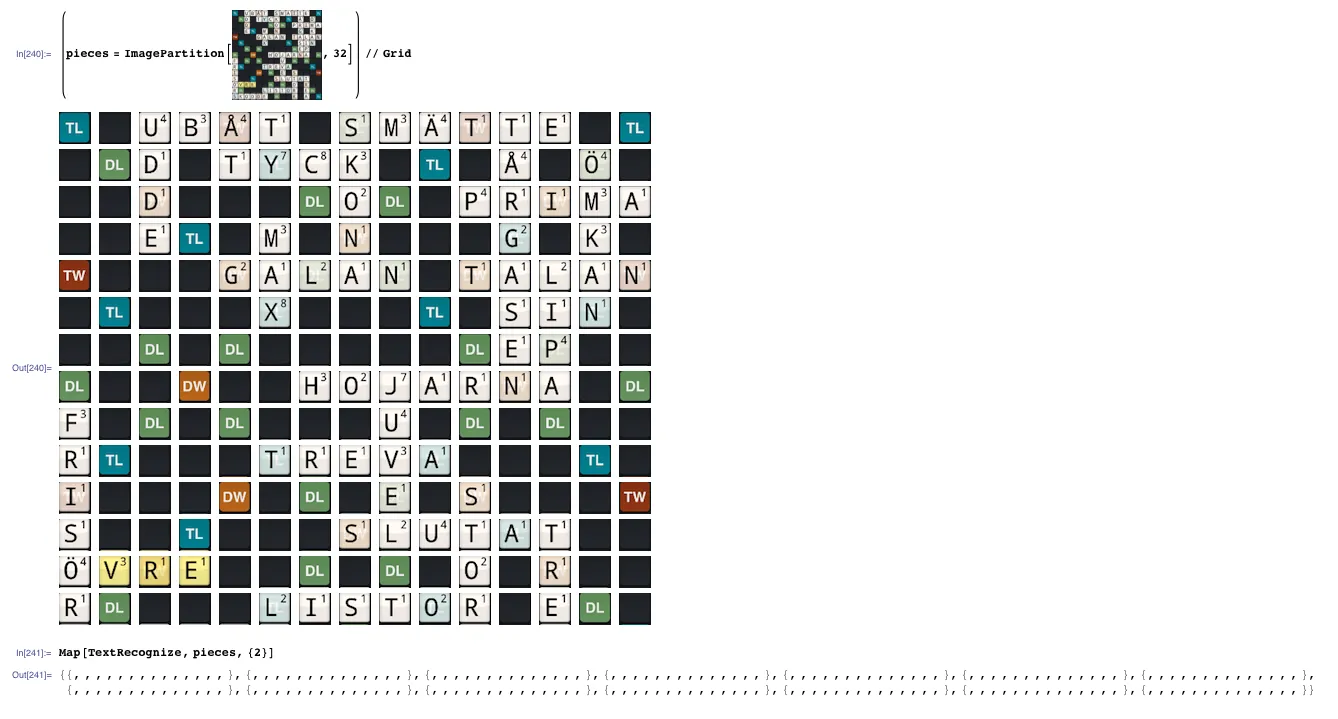

为方便起见,如果您想自己尝试,请查看本帖子底部使用的图像。您还可以通过在Google图像搜索中搜索“Wordfeud”来找到更多类似的图像。
非常棒的问题!
TextRecognize使用启发式算法来识别英语单词。这是使识别单个字母变得非常困难的陷阱。
考虑以下思路:
s = Import["http://i.stack.imgur.com/JHYuh.png"];
p = ImagePartition[s, 32]
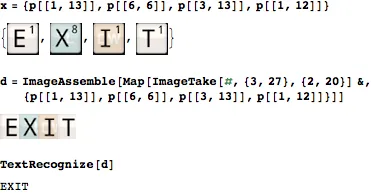
现在选择字母组成英语单词“EXIT”:
x = {p[[1, 13]], p[[6, 6]], p[[3, 13]], p[[1, 12]]}
现在稍微清理一下这些图像,就像这样:
d = ImageAssemble[ Map[ImageTake[#, {3, 27}, {2, 20}] &, x ]];
然后这将返回字符串"EXIT":
TextRecognize[d]
TextRecognize的后端Tesseract已经能实现)。这将使读取数字数据更加容易。 - Szabolcs这种方法与使用TextRecognize完全不同,因此我将其发布为单独的答案。它使用与如何在Mathematica中找到Waldo相同的图像识别技术。
首先获取谜题:
wordfeud = Import["http://i.stack.imgur.com/JHYuh.png"]

然后获取拼图的碎片:
Grid[pieces = ImagePartition[s, 32]]

我们来关注字母E:
LetterE = pieces[[4, 3]]

获取相关性图像:
correlation =
ImageCorrelate[wordfeud, Binarize[LetterE],
NormalizedSquaredEuclideanDistance]

并且突出显示匹配项:
positions = Dilation[ColorNegate[Binarize[correlation, .1]], DiskMatrix[20]];
found = ImageMultiply[wordfeud, ImageAdd[ColorConvert[positions, "GrayLevel"], .5]]

与之前一样,这需要在将相关图像二值化方面进行一些微调,但除此之外,这应该能够帮助识别这个谜题的各部分。
TextRecognize[Binarize@img]
(* output *)
ANTS FFWWW FEEWF
E R o If IU I?
E A FI5F WWWFF 5
5552? L E F F
T s E NTT BT|
H0RWW@0WVlWF;EE F
5 W E ; OCS
FOFT W W R AL%AE
A TT I T ? _
i iE@W'NF WG%S W
A A EW F I i
SWWTW W ALTFCWD N
H A V 5 A F F
PLATT EWWLIGHT
W N E T
HE TIRES C
TEXAS VECTORS
我没有耐心完全清理图像,最快的方法是手动重新输入文本。
结论:除非您有绝对清晰的文本,并且背景均匀明亮(最好是白色),否则不要在mma中使用文本识别。
结果还取决于所使用的文件格式。完全避免使用.pdf格式。
编辑
acl尝试捕获并识别了上面5行文字(编辑前)。他的结果(在下面的评论中):大部分都是无意义的。
我决定也这样做。但由于Prashant警告说字体大小很重要,所以我先放大了文本,使其看起来(在我的眼中)大约为20磅。以下是我扫描和TextRecognize过的文本图片。

以下是未二值化的TextRecognize结果(在那个大尺寸下):
Gliii. Q lk-ii`t`*¥ if EY £\[CloseCurlyDoubleQuote]1\[Euro]'EE \
Di'¥C~E\"P ITF SKI' T»f}!E'!',IL:?E\[CloseCurlyDoubleQuote] I 2 VEEE5\
\[CloseCurlyQuote] LEP \"- \"VE
1. ur e=\\..r.1.»».»\\\\ rw r 1»»\\|a'*r | r .fm -»'-an \
\[OpenCurlyQuote] -.-rr -_.»~|-.'i~-.w~,.-- nv n.w~»-\
\[OpenCurlyDoubleQuote]~"
现在,这是二值图像的文本识别结果。原始图像来自Jing的.png格式。
I didn't have the patience to completely clean up the image. It would \
have been much faster to retype the
text by hand.
Conclusion: Don't use text recognition in mma unless you have \
absolutely clear text against an even-
colored, bright, preferrably white, background.
The results also varied depending on the file format used. Avoid .pdf \
altogether.
TextRecognize无法识别低于某个阈值的文本。 - Prashant Bhate