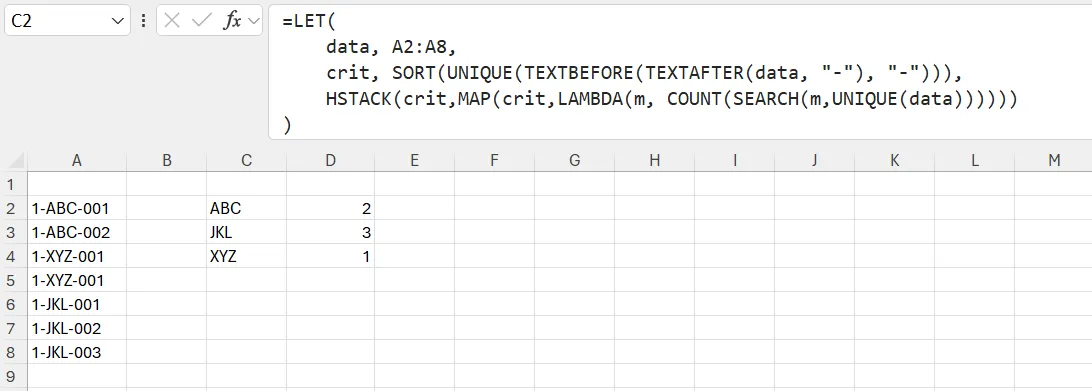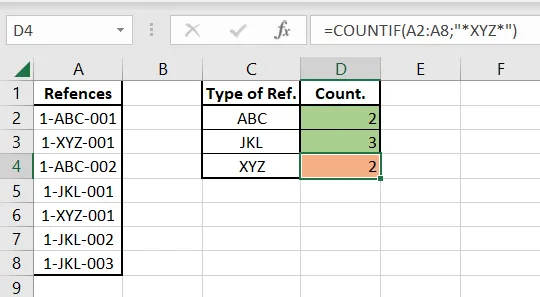
我想知道每种类型的参考文献有多少个。但是,如果文档中的参考文献重复出现,应该只计算为1个。
我尝试过使用COUNTIF函数,但显然它不能正常工作。
正如您在示例中所看到的,XYZ参考文献被计算为有2个不同的条目。但实际上只有1-XYZ-001,并且它出现了两次。
在我的示例中,我应该使用什么公式,以便XYZ显示为1,而其他的保持其值不变?
我看到了类似问题的解决方案,但在这个问题中,我的计数条件只是参考文献的一部分,我认为这会搞乱类似this的东西。
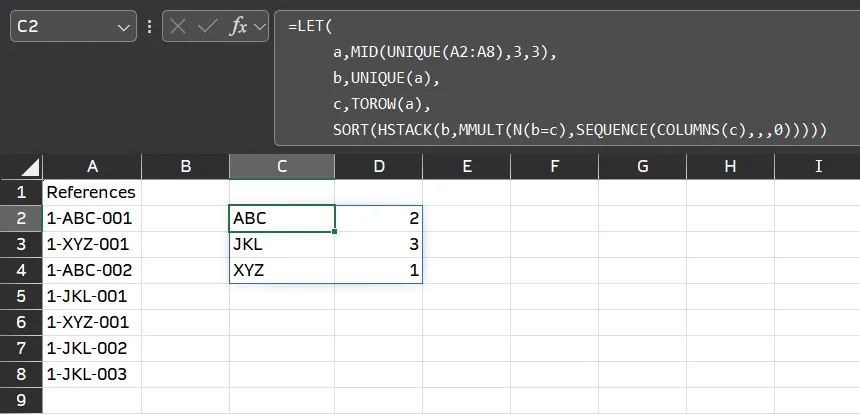
=LET(
a,MID(UNIQUE(A2:A8),3,3),
b,UNIQUE(a),
c,TOROW(a),
SORT(HSTACK(b,MMULT(N(b=c),SEQUENCE(COLUMNS(c),,,0)))))
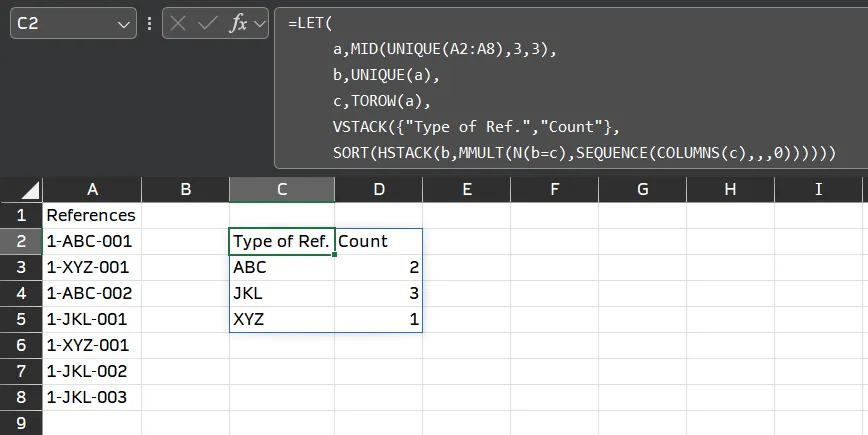
=LET(
a,MID(UNIQUE(A2:A8),3,3),
b,UNIQUE(a),
c,TOROW(a),
VSTACK({"Type of Ref.","Count"},
SORT(HSTACK(b,MMULT(N(b=c),SEQUENCE(COLUMNS(c),,,0))))))
=LET(a, A2:A8,
m, UNIQUE(MID(a,3,3)),
u, MID(UNIQUE(a),3,3),
HSTACK(m,
MMULT(N(TOROW(u)=m),SEQUENCE(ROWS(u),,,0))))
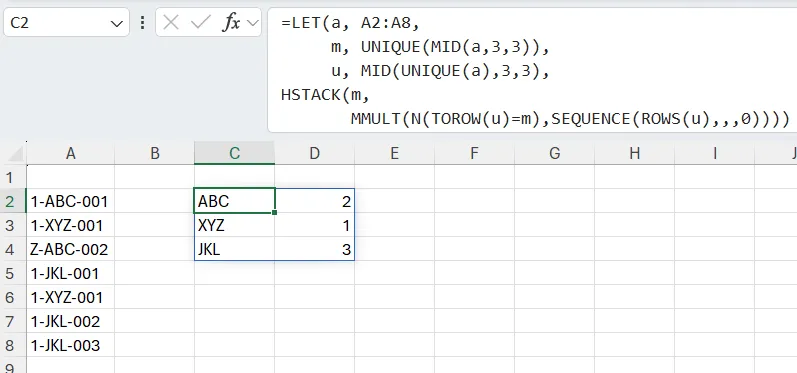
=LET(a, A2:A8,
m, SORT(UNIQUE(MID(a,3,3))),
u, MID(UNIQUE(a),3,3),
HSTACK(m,
MMULT(N(TOROW(u)=m),SEQUENCE(ROWS(u),,,0))))
=LET(a, A2:A8,
u, MID(UNIQUE(a),3,3),
m, SORT(UNIQUE(u)),
HSTACK(m,
MMULT(N(TOROW(u)=m),SEQUENCE(ROWS(u),,,0))))
u, MID(UNIQUE(a),3,3),,然后再执行更高效的 m,SORT(UNIQUE(u)),。 - undefined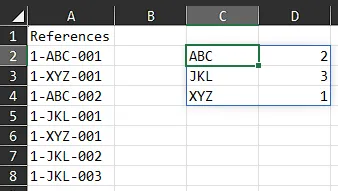
C2中的公式:
=LET(r,A2:A8,f,MID(r,3,3),u,SORT(UNIQUE(f)),HSTACK(u,MAP(u,LAMBDA(s,ROWS(UNIQUE(FILTER(r,f=s)))))))
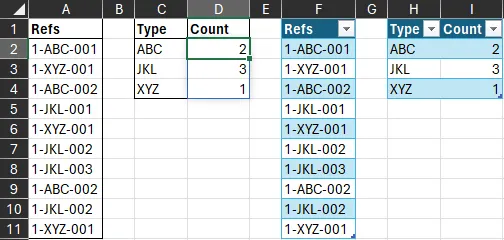
COUNT函数,即计算范围(数组)中数字的数量,实际上不必使用=SUM(N(ISNUMBER(array)))(我在编辑之前使用过)。=COUNT(array)。单元格公式(向下填充)
=TOCOL(BYCOL(SEARCH(TOROW(C2:C4), UNIQUE(A2:A11)), LAMBDA(c, COUNT(c))))
公式在D2(向下复制)
=COUNT(SEARCH(C2, UNIQUE(A$2:A$11)))
=COUNT(SEARCH([@Type], UNIQUE(Table1[Refs])))
=ROWS(FILTER(UNIQUE($A$2:$A$8),ISNUMBER(SEARCH(C2,UNIQUE($A$2:$A$8)))))
=BYROW(
$C$2:$C$4,
LAMBDA(arr,
ROWS(
FILTER(
UNIQUE($A$2:$A$8),
ISNUMBER(SEARCH(arr, UNIQUE($A$2:$A$8)))
)
)
)
)
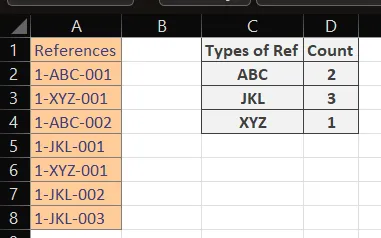
=BYROW(
$C$2:$C$4,
LAMBDA(arr,
IFERROR(
ROWS(
FILTER(
UNIQUE($A$2:$A$8),
ISNUMBER(SEARCH(arr, UNIQUE($A$2:$A$8)))
)
),
0
)
)
)
FILTER返回什么,至少会有一行结果,因此结果永远不会为0。 - undefinedIFERROR轻松进行测试。 - undefined=LET(
data, A2:A8,
crit, SORT(UNIQUE(TEXTBEFORE(TEXTAFTER(data, "-"), "-"))),
HSTACK(crit,MAP(crit,LAMBDA(m, COUNT(SEARCH(m,UNIQUE(data))))))
)