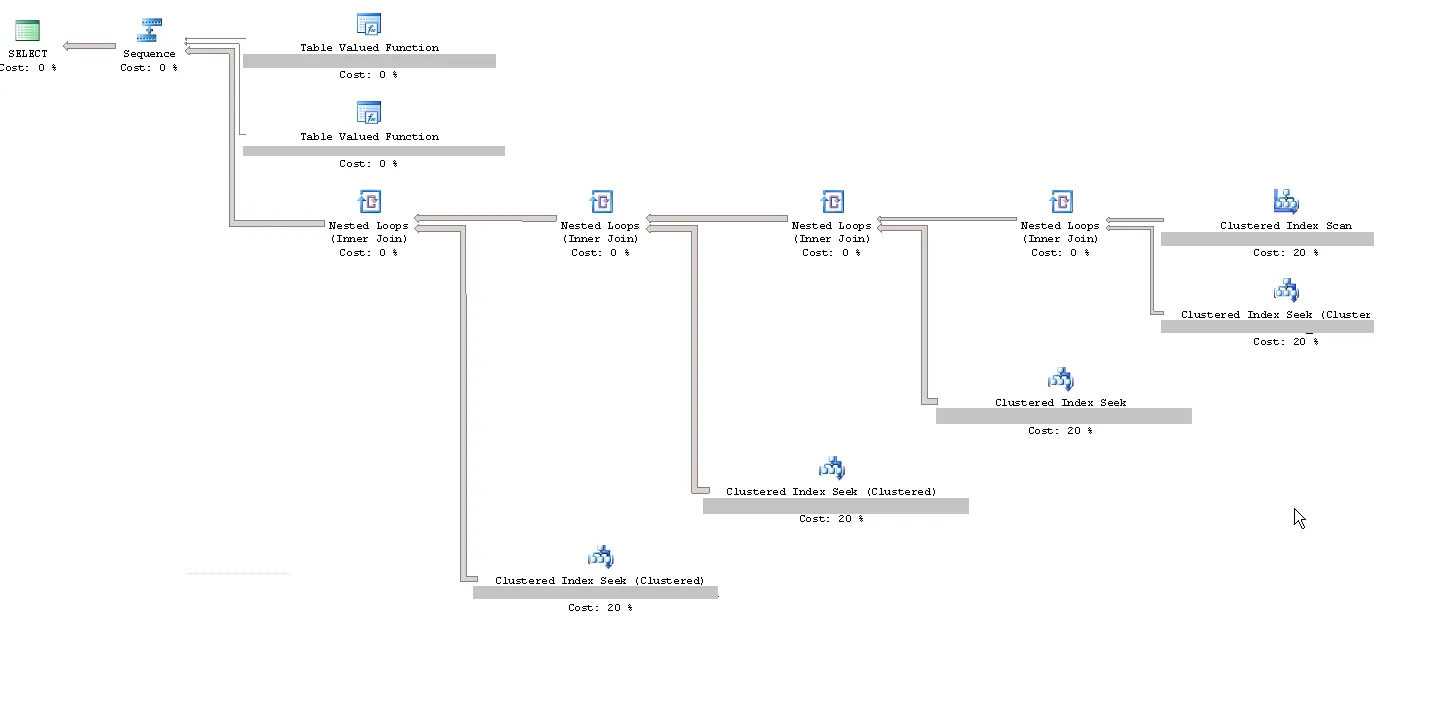
我有一个存储过程,它根据输入参数构建动态SQL语句并执行。
其中一个查询导致超时,所以我决定检查一下。第一次执行出现问题的语句时很慢(30秒-45秒),但每次后续执行只需要1-2秒。
为了重现这个问题,我正在使用
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
我真的很困惑问题出在哪里,因为普通的 SQL 语句如果慢的话,一直都是慢的。现在,它只有第一次执行时才需要很长时间。
这可能是因为它本身很慢需要优化,还是因为其他原因导致的问题?
执行计划如下,但对我来说没有什么奇怪的地方: