这个问题并不是关于采样数据的,我知道`sample_n`函数,但这个问题是关于从数据框架中模拟数据,以便比较其在模拟和真实情况下的平均值(使用`group_by summarise`)。
我通过以下方式计算了实际平均差异:
我通过以下方式计算了实际平均差异:
df %>%
group_by(allfour) %>%
summarise(hs_completion=mean(hsgrad),
count=n())
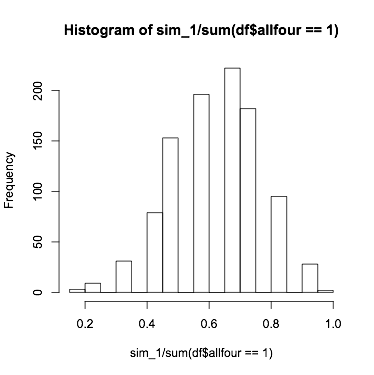
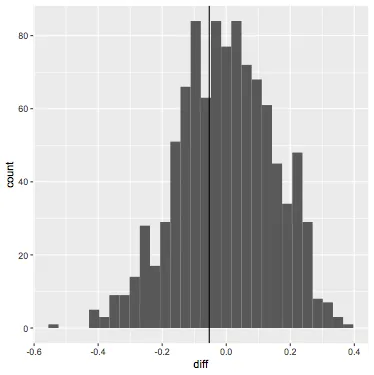
然而,我正在努力从每个组中绘制100个模拟,并将每个向量除以相应组的大小,以将其转换为模拟毕业率,并计算两个组之间这些率的差异。完成后,我需要绘制这些模拟差异的直方图,并在该直方图上添加一个红色垂直线,在观察数据中计算出的平均差异值处。
我知道tidyverse和ggplot,所以绘图不是问题,只是当记录有限时如何进行100次模拟。
数据框df的示例如下:
structure(list(hsgrad = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 0L, 1L, 1L, 0L, 0L, 1L, 1L, 1L, 1L, 0L, 1L, 0L, 0L,
0L, 1L, 1L, 0L, 0L, 0L, 0L, 1L, 1L, 0L, 1L, 1L, 1L, 0L, 0L, 0L,
1L, 1L, 0L, 0L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 0L, 1L, 0L, 0L,
0L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 0L, 1L, 0L, 0L,
1L, 1L, 0L, 1L, 1L, 1L, 0L, 0L, 0L, 0L, 1L, 1L, 0L, 0L, 1L, 1L,
1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 0L), allfour = structure(c(1L,
2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 2L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 1L,
1L, 1L, 1L, 1L, 1L, 2L, 2L, 1L, 2L, 1L, 1L, 1L, 1L, 1L, 2L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 2L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 2L, 1L), .Label = c("0", "1"), class = "factor")), row.names = c(NA,
100L), class = "data.frame")