表1(id,name)
表2(id,name)
查询语句:
SELECT name
FROM table2
-- that are not in table1 already
表1(id,name)
表2(id,name)
查询语句:
SELECT name
FROM table2
-- that are not in table1 already
SELECT t1.name
FROM table1 t1
LEFT JOIN table2 t2 ON t2.name = t1.name
WHERE t2.name IS NULL
Q: 这里发生了什么?
A: 在概念上,我们选择table1中的所有行,并尝试查找与name列具有相同值的行。如果没有这样的行,则对于该行,我们将只在结果中留下table2部分为空。然后,我们通过选择只有匹配行不存在的结果中的那些行来限制我们的选择。最后,我们忽略结果中除name列(从table1确定存在)之外的所有字段。
虽然这可能不是所有情况下最有效的方法,但它应该在几乎每个试图实现ANSI 92 SQL的数据库引擎中都可以运行。
你可以选择
SELECT name
FROM table2
WHERE name NOT IN
(SELECT name
FROM table1)
SELECT name
FROM table2
WHERE NOT EXISTS
(SELECT *
FROM table1
WHERE table1.name = table2.name)
参见此问题,了解三种实现此操作的技巧。
我没有足够的声望点数来投票赞同 froadie的答案。但是我不同意对 Kris的答案 的评论。以下是答案:
SELECT name
FROM table2
WHERE name NOT IN
(SELECT name
FROM table1)
实际上要高效得多。我不知道为什么,但是我正在处理80万条记录,并且与上面发布的第二个答案相比,差异非常大。只是我的两分钱。
SELECT <column_list>
FROM TABLEA a
LEFTJOIN TABLEB b
ON a.Key = b.Key
WHERE b.Key IS NULL;
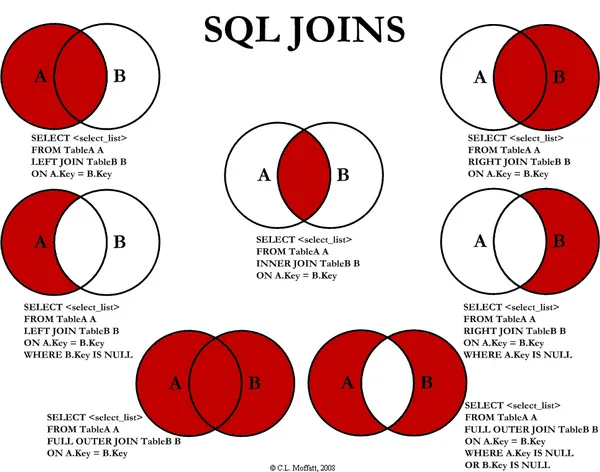
这是纯集合论,你可以使用 minus 操作来实现。
select id, name from table1
minus
select id, name from table2
这是最适合我的方法。
SELECT *
FROM @T1
EXCEPT
SELECT a.*
FROM @T1 a
JOIN @T2 b ON a.ID = b.ID
这比我尝试过的任何其他方法都快了两倍以上。
注意潜在陷阱。如果 Table1 中的 Name 字段包含空值,那么你可能会遇到一些惊喜。
更好的做法是:
SELECT name
FROM table2
WHERE name NOT IN
(SELECT ISNULL(name ,'')
FROM table1)
EXCEPT或在oracle中使用MINUS,根据http://blog.sqlauthority.com/2008/08/07/sql-server-except-clause-in-sql-server-is-similar-to-minus-clause-in-oracle/的说法,它们是相同的。SELECT *
FROM [dbo].[table1] t1
LEFT JOIN [dbo].[table2] t2 ON t1.[t1_ID] = t2.[t2_ID]
WHERE t2.[t2_ID] IS NULL
SELECT name, source, id
FROM
(
SELECT name, "active_ingredients" as source, active_ingredients.id as id
FROM active_ingredients
UNION ALL
SELECT active_ingredients.name as name, "UNII_database" as source, temp_active_ingredients_aliases.id as id
FROM active_ingredients
INNER JOIN temp_active_ingredients_aliases ON temp_active_ingredients_aliases.alias_name = active_ingredients.name
) tbl
GROUP BY name
HAVING count(*) = 1
ORDER BY name