我刚刚听说了
据我了解,表情符号是UTF-8字符,因此应该适合于
char8_t,char16_t和char32_t的存在,并正在测试它。当我尝试编译下面的代码时,g++会抛出以下错误:error: use of deleted function ‘std::basic_ostream<char, _Traits>& std::operator<<(basic_ostream<char, _Traits>&, char32_t) [with _Traits = char_traits<char>]’
6 | std::cout << U'' << std::endl;
| ^~~~~
#include <iostream>
int main() {
char32_t c = U'';
std::cout << c << std::endl;
return 0;
}
此外,为什么我不能将表情符号放入char8_t或char16_t中呢?例如,下面的代码行不起作用:
char16_t c1 = u'';
char8_t c2 = u8'';
auto c3 = u'';
auto c4 = u8'';
据我了解,表情符号是UTF-8字符,因此应该适合于
char8_t。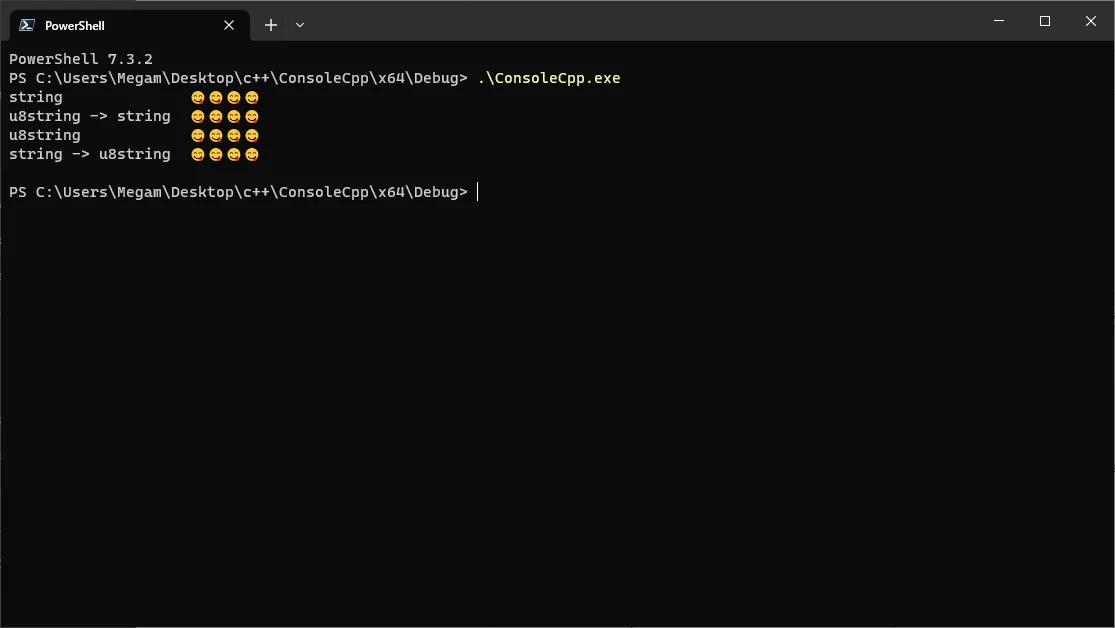
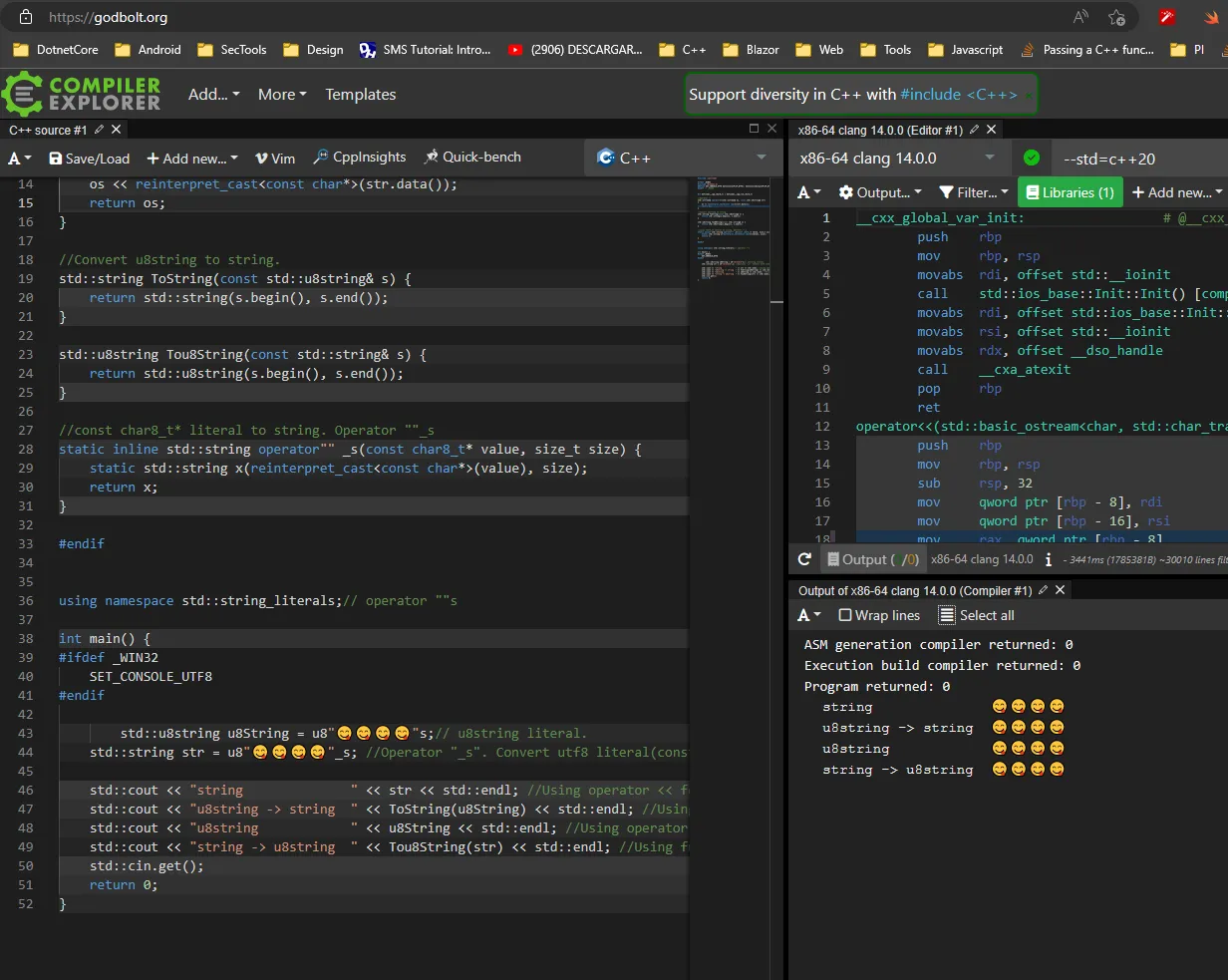
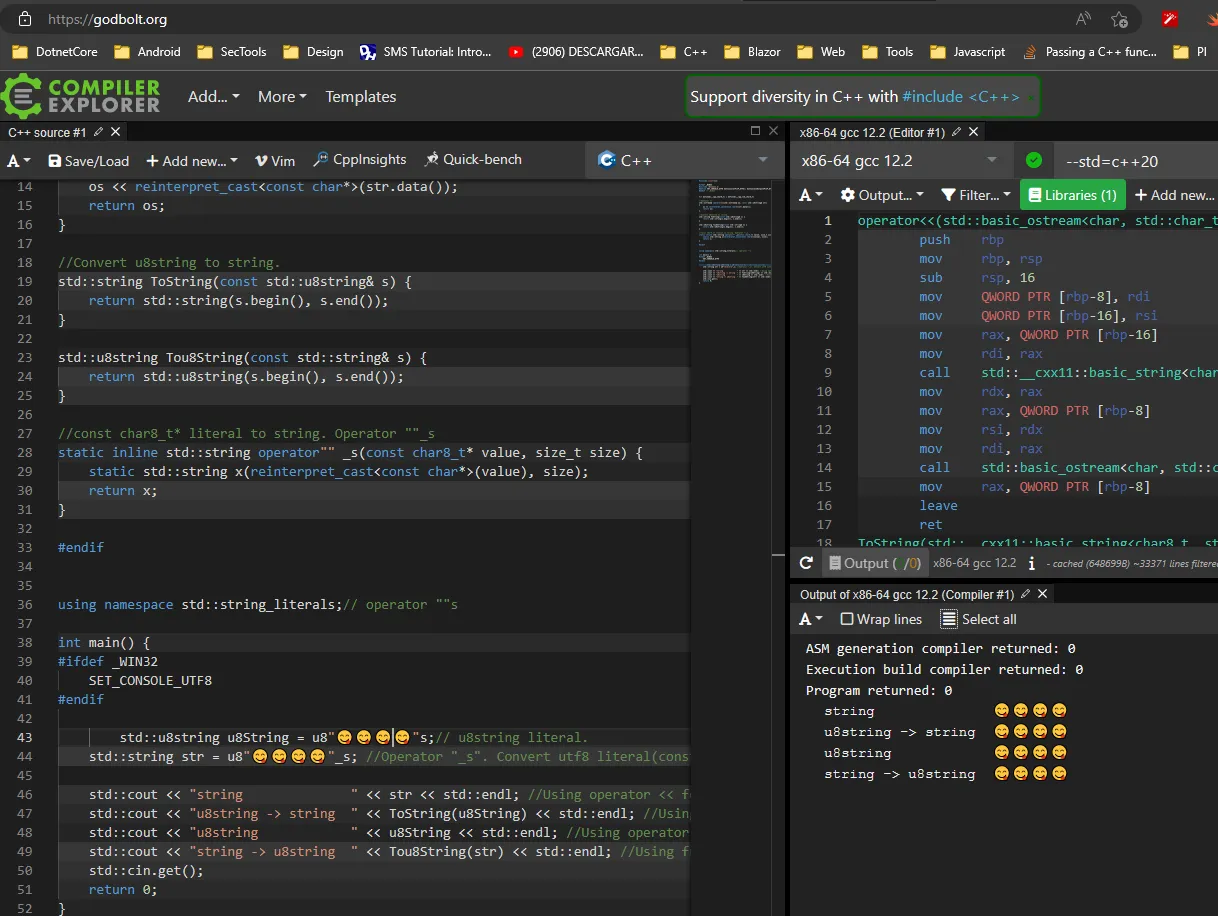
char const* c = "";。 - chrysanteuint8_t中没有足够的空间来容纳所有 ASCII 字符和所有表情符号。你需要一个具有更多空间的数据结构。 - Thomas Matthews