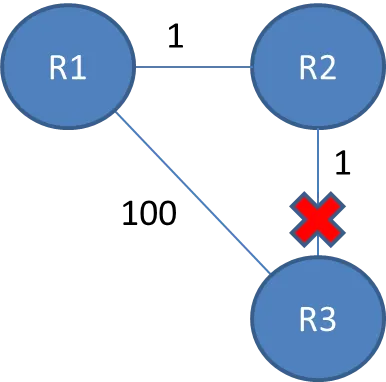
据我所理解,计数到无穷大是指一个路由器向另一个路由器提供旧信息,这些信息会继续在网络中传播直至无穷大。从我所读的内容来看,当一个链接被移除时,这种情况肯定会发生。
例如,在上面的示例中,当算法收敛时,R2以1的成本到达R3,R1通过R2以2的成本到达R3。如果R2和R3之间的成本增加到5,则会导致相同的问题,R2可以从R1接收到成本为2的更新,并通过R1将其成本更改为3,然后R1通过R2将其路由成本更改为4等等。但是,如果已经收敛的路由成本降低,则不会引起变化。这是正确的吗?是链接成本的增加可能会导致问题,而不是降低成本?还有其他可能的原因吗?将路由器离线是否与链接离线相同?

因此,在本例中,Bellman-Ford算法将对每个路由器进行收敛,它们将彼此拥有条目。R2将知道它可以以成本1到达R3,而R1将知道它可以通过R2以成本2到达R3。
如果R2和R3之间的链接断开,则R2将知道它不能再通过该链接到达R3,并将其从表中删除。在发送任何更新之前,可能会收到来自R1的更新,表示它可以以成本2到达R3。R2可以以成本1到达R1,因此它将更新一个路由,通过R1到达R3,成本为3。然后,R1稍后会收到来自R2的更新,并将其成本更新为4。然后他们将互相传递错误信息并持续不断。
我看到有些地方提到,导致计数无限的原因不仅仅是链接离线,还可能包括链接成本的变化。我思考了一下,据我所知,链接成本的增加可能会导致问题。然而,我并没有看到降低成本会导致问题的可能性。例如,在上面的示例中,当算法收敛时,R2以1的成本到达R3,R1通过R2以2的成本到达R3。如果R2和R3之间的成本增加到5,则会导致相同的问题,R2可以从R1接收到成本为2的更新,并通过R1将其成本更改为3,然后R1通过R2将其路由成本更改为4等等。但是,如果已经收敛的路由成本降低,则不会引起变化。这是正确的吗?是链接成本的增加可能会导致问题,而不是降低成本?还有其他可能的原因吗?将路由器离线是否与链接离线相同?