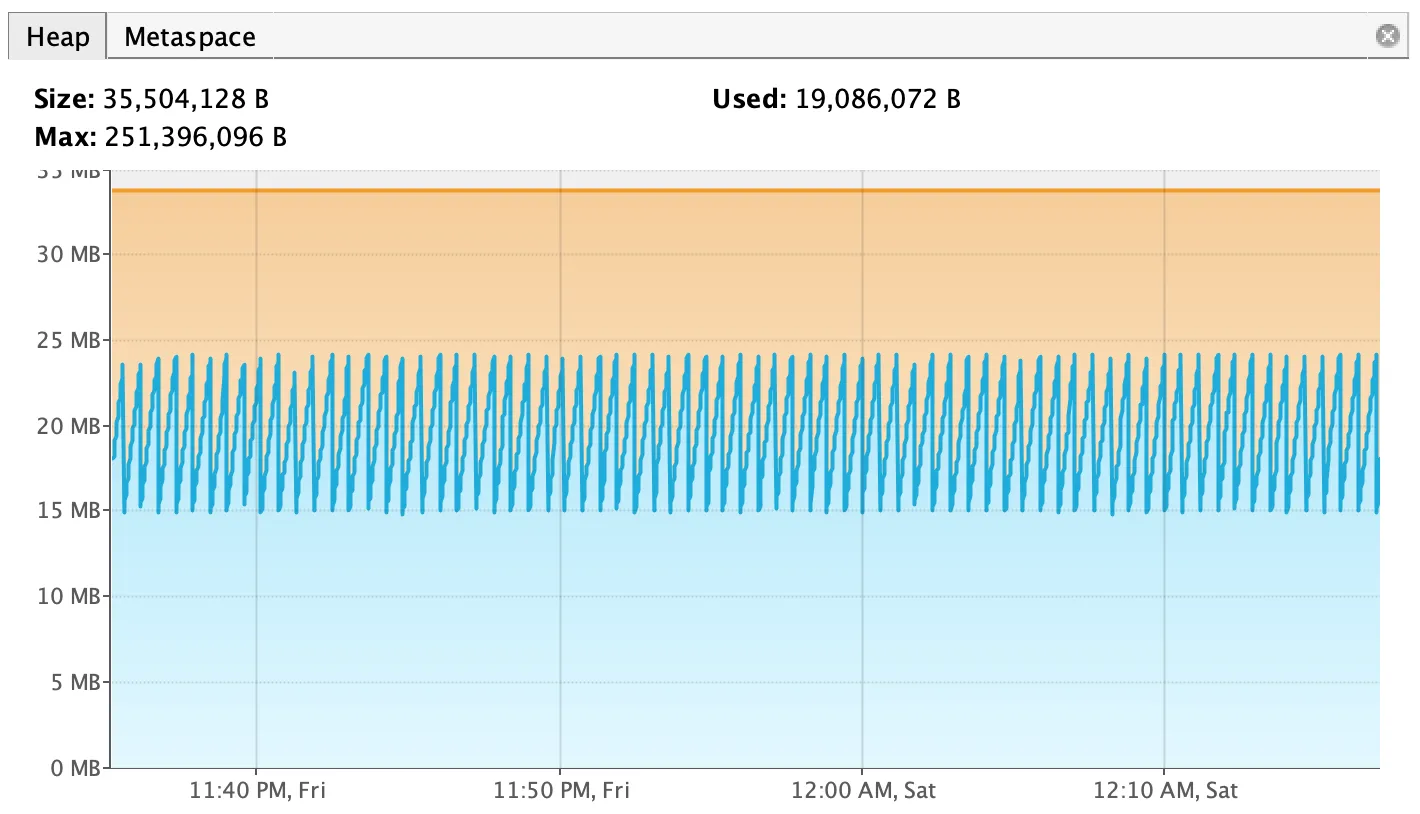
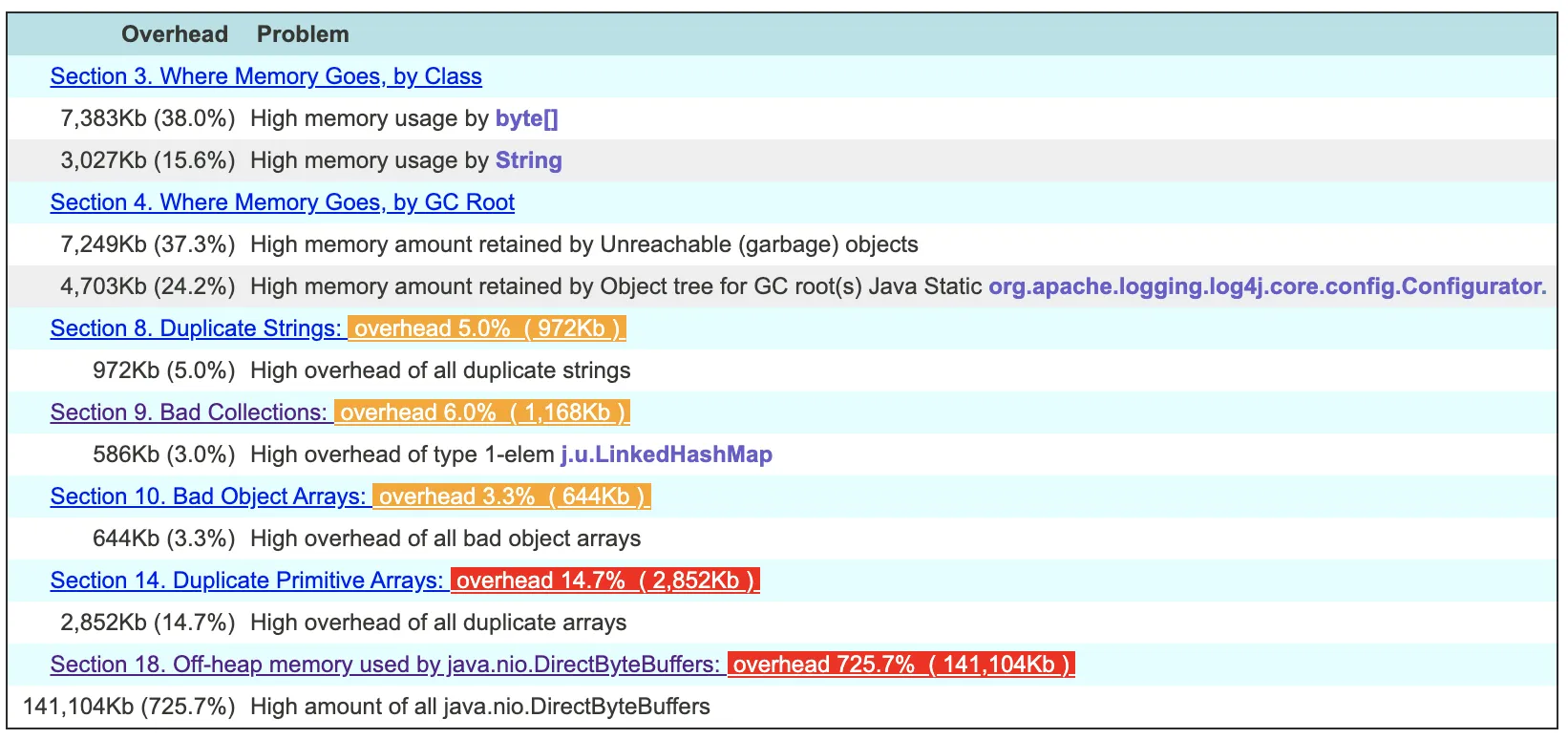
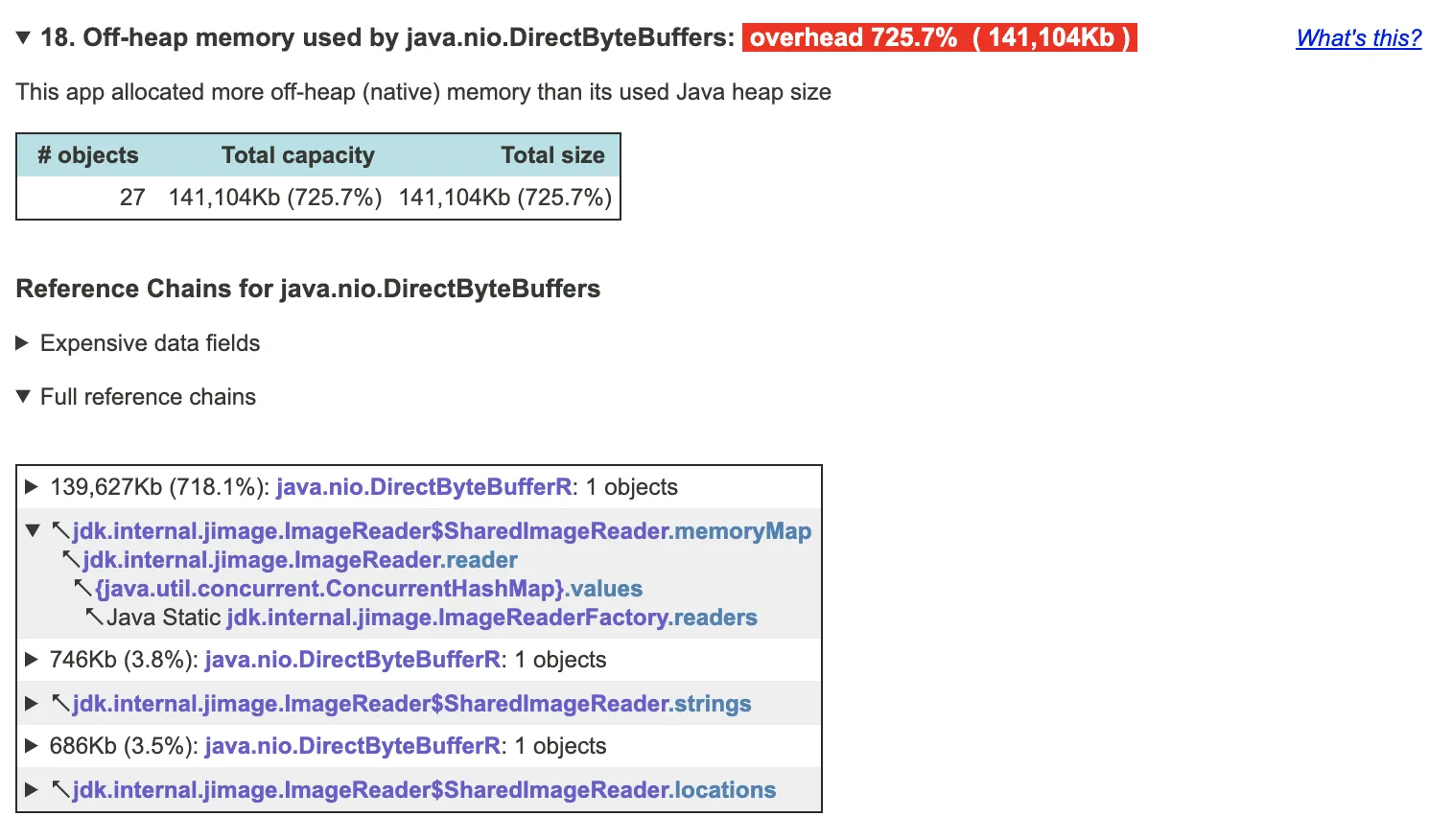
我们通常会处理由于堆或permgen大小配置问题而导致的OutOfMemoryError问题。但是,所有JVM内存并不都是permgen或堆。
就我所理解的而言,它也可能与线程/堆栈、本机JVM代码等有关。
但是使用pmap,我可以看到进程分配了9.3G,其中3.3G是非堆内存使用量。
我想知道监视和调整此额外非堆内存消耗的可能性有哪些。
我不使用直接的非堆内存访问(MaxDirectMemorySize默认为64m)。
我们面临的主要问题是:
我正在考虑测试在一些流行的基于Java的存储/NoSQL中使用的
但是使用pmap,我可以看到进程分配了9.3G,其中3.3G是非堆内存使用量。
我想知道监视和调整此额外非堆内存消耗的可能性有哪些。
我不使用直接的非堆内存访问(MaxDirectMemorySize默认为64m)。
Context: Load testing
Application: Solr/Lucene server
OS: Ubuntu
Thread count: 700
Virtualization: vSphere (run by us, no external hosting)
JVM
java version "1.7.0_09"
Java(TM) SE Runtime Environment (build 1.7.0_09-b05)
Java HotSpot(TM) 64-Bit Server VM (build 23.5-b02, mixed mode)
调优
-Xms=6g
-Xms=6g
-XX:MaxPermSize=128m
-XX:-UseGCOverheadLimit
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+CMSClassUnloadingEnabled
-XX:+OptimizeStringConcat
-XX:+UseCompressedStrings
-XX:+UseStringCache
内存映射:
https://gist.github.com/slorber/5629214
vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 1743 381 4 1150 1 1 60 92 2 0 1 0 99 0
免费
total used free shared buffers cached
Mem: 7986 7605 381 0 4 1150
-/+ buffers/cache: 6449 1536
Swap: 4091 1743 2348
顶部
top - 11:15:49 up 42 days, 1:34, 2 users, load average: 1.44, 2.11, 2.46
Tasks: 104 total, 1 running, 103 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.5%us, 0.2%sy, 0.0%ni, 98.9%id, 0.4%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 8178412k total, 7773356k used, 405056k free, 4200k buffers
Swap: 4190204k total, 1796368k used, 2393836k free, 1179380k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
17833 jmxtrans 20 0 2458m 145m 2488 S 1 1.8 206:56.06 java
1237 logstash 20 0 2503m 142m 2468 S 1 1.8 354:23.19 java
11348 tomcat 20 0 9184m 5.6g 2808 S 1 71.3 642:25.41 java
1 root 20 0 24324 1188 656 S 0 0.0 0:01.52 init
2 root 20 0 0 0 0 S 0 0.0 0:00.26 kthreadd
...
df -> tmpfs
Filesystem 1K-blocks Used Available Use% Mounted on
tmpfs 1635684 272 1635412 1% /run
我们面临的主要问题是:
- 服务器有8G物理内存
- Solr的堆只占用了6G
- 有1.5G交换空间
- Swappiness=0
- 堆消耗似乎已经适当调整
- 仅在服务器上运行:Solr和一些监控工具
- 平均响应时间正确
- 有时会有异常长的暂停,长达20秒
我正在考虑测试在一些流行的基于Java的存储/NoSQL中使用的
mlockall技巧,例如ElasticSearch、Voldemort或Cassandra:检查使用mlockall使JVM/Solr不交换。
编辑:
在这里,您可以看到最大堆、已使用堆(蓝色)、已使用交换空间(红色)。它们似乎有些相关。
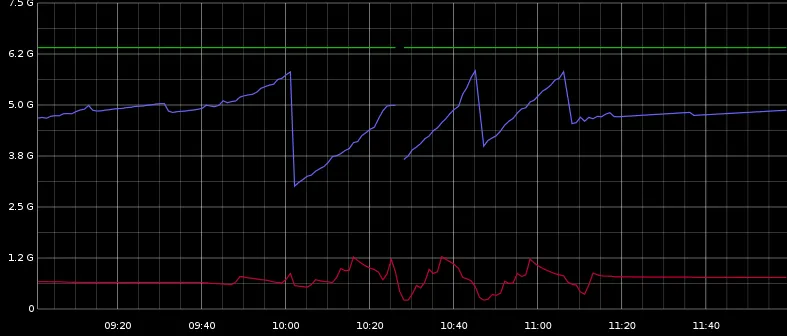
暂停似乎与堆的减少无关,但在10:00至11:30之间定期分布,所以我猜可能与ParNew GC有关。
在负载测试期间,我可以看到一些磁盘活动,还有一些交换IO活动,在测试结束时非常平静。