我在Delphi中编写了一个简单的for循环。
在Julia 1.6中,同样的程序运行速度快了7.6倍。
5. 正如AhnLab所提到的,我进行了相当"干燥"的测试。我猜想需要编写一个执行更复杂/真实任务的完整程序,并在程序结束时查看Julia是否仍然比Delphi 7倍性能更好。
procedure TfrmTester.btnForLoopClick(Sender: TObject);
VAR
i, Total, Big, Small: Integer;
s: string;
begin
TimerStart;
Total:= 0;
Big := 0;
Small:= 0;
for i:= 1 to 1000000000 DO //1 billion
begin
Total:= Total+1;
if Total > 500000
then Big:= Big+1
else Small:= Small+1;
end;
s:= TimerElapsedS;
//here code to show Big/Small on the screen
end;
这段汇编代码在我看来还不错:
TesterForm.pas.111: TimerStart;
007BB91D E8DE7CF9FF call TimerStart
TesterForm.pas.113: Total:= 0;
007BB922 33C0 xor eax,eax
007BB924 8945F4 mov [ebp-$0c],eax
TesterForm.pas.114: Big := 0;
007BB927 33C0 xor eax,eax
007BB929 8945F0 mov [ebp-$10],eax
TesterForm.pas.115: Small:= 0;
007BB92C 33C0 xor eax,eax
007BB92E 8945EC mov [ebp-$14],eax
TesterForm.pas.**116**: for i:= 1 to 1000000000 DO //1 billion
007BB931 C745F801000000 mov [ebp-$08],$00000001
TesterForm.pas.118: Total:= Total+1;
007BB938 FF45F4 inc dword ptr [ebp-$0c]
TesterForm.pas.119: if Total > 500000
007BB93B 817DF420A10700 cmp [ebp-$0c],$0007a120
007BB942 7E05 jle $007bb949
TesterForm.pas.120: then Big:= Big+1
007BB944 FF45F0 inc dword ptr [ebp-$10]
007BB947 EB03 jmp $007bb94c
TesterForm.pas.121: else Small:= Small+1;
007BB949 FF45EC inc dword ptr [ebp-$14]
TesterForm.pas.122: end;
007BB94C FF45F8 inc dword ptr [ebp-$08]
TesterForm.pas.**116**: for i:= 1 to 1000000000 DO //1 billion
007BB94F 817DF801CA9A3B cmp [ebp-$08],$3b9aca01
007BB956 75E0 jnz $007bb938
TesterForm.pas.124: s:= TimerElapsedS;
007BB958 8D45E8 lea eax,[ebp-$18]
为什么Delphi的得分与Julia相比如此糟糕?我能做些什么来改善编译器生成的代码吗?
信息
我的Delphi 10.4.2程序是Win32位。当然,我在“发布”模式下运行 :)
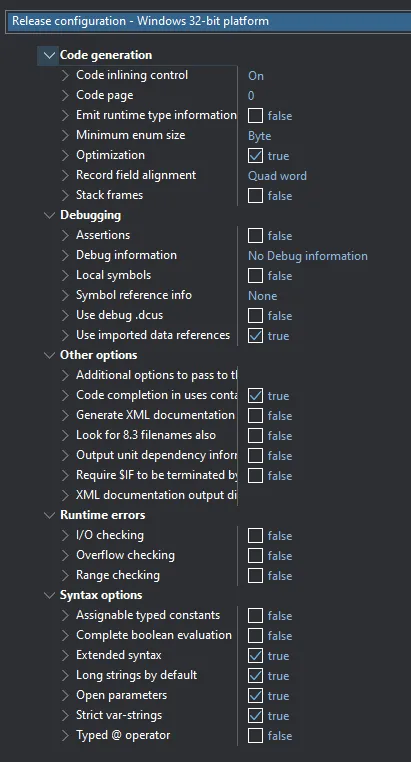
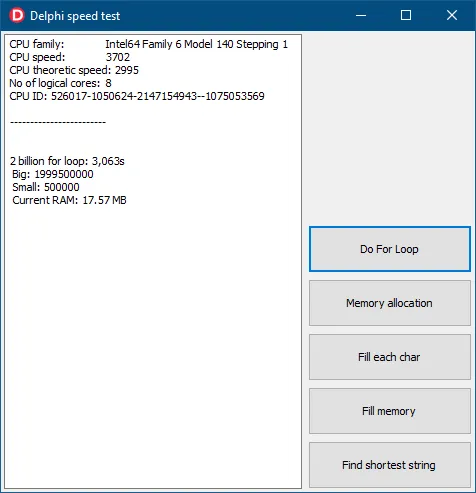
但是上面的ASM代码是针对“Debug”版本的,因为我不知道如何在运行优化的EXE文件时暂停程序的执行。但是发布版和调试版exe之间的差异非常小(1.8 vs 1.5秒)。Julia只需要195毫秒。
更多讨论
我必须提到,当您第一次在Julia中运行代码时,它的时间非常长,因为Julia是JIT,所以它必须首先编译代码。编译时间(因为它是“一次性”的)未包含在测量中。
此外,正如AmigoJack所评论的那样,Delphi代码几乎可以在任何地方运行,而Julia代码可能仅在具有支持所有这些新/花哨指令的现代CPU的计算机上运行。我有一些小工具,它们是在2004年制作的,今天仍在运行。
无论Julia生成什么代码,除非客户端安装了Julia,否则无法交付给“客户”。
总之,所有这些都表明Delphi编译器非常过时,这很令人遗憾。
4. 我进行了其他测试,发现在一个字符串列表中找到最短和最长的字符串,在Delphi中比Julia快10倍。分配小块内存(10000x10000x4字节)的速度相同。5. 正如AhnLab所提到的,我进行了相当"干燥"的测试。我猜想需要编写一个执行更复杂/真实任务的完整程序,并在程序结束时查看Julia是否仍然比Delphi 7倍性能更好。
更新
好的,这段 Julia 代码对我来说完全陌生。似乎使用了更现代化的操作符:
; ┌ @ Julia_vs_Delphi.jl:4 within `for_fun`
pushq %rbp
movq %rsp, %rbp
subq $96, %rsp
vmovdqa %xmm11, -16(%rbp)
vmovdqa %xmm10, -32(%rbp)
vmovdqa %xmm9, -48(%rbp)
vmovdqa %xmm8, -64(%rbp)
vmovdqa %xmm7, -80(%rbp)
vmovdqa %xmm6, -96(%rbp)
movq %rcx, %rax
; │ @ Julia_vs_Delphi.jl:8 within `for_fun`
; │┌ @ range.jl:5 within `Colon`
; ││┌ @ range.jl:354 within `UnitRange`
; │││┌ @ range.jl:359 within `unitrange_last`
testq %rdx, %rdx
; │└└└
jle L80
; │ @ Julia_vs_Delphi.jl within `for_fun`
movq %rdx, %rcx
sarq $63, %rcx
andnq %rdx, %rcx, %r9
; │ @ Julia_vs_Delphi.jl:13 within `for_fun`
cmpq $8, %r9
jae L93
; │ @ Julia_vs_Delphi.jl within `for_fun`
movl $1, %r10d
xorl %edx, %edx
xorl %r11d, %r11d
jmp L346
L80:
xorl %edx, %edx
xorl %r11d, %r11d
xorl %r9d, %r9d
jmp L386
L93: movabsq $9223372036854775800, %r8 # imm = 0x7FFFFFFFFFFFFFF8
; │ @ Julia_vs_Delphi.jl:13 within `for_fun`
andq %r9, %r8
leaq 1(%r8), %r10
movabsq $.rodata.cst32, %rcx
vmovdqa (%rcx), %ymm1
vpxor %xmm0, %xmm0, %xmm0
movabsq $.rodata.cst8, %rcx
vpbroadcastq (%rcx), %ymm2
movabsq $1023787240, %rcx # imm = 0x3D05C0E8
vpbroadcastq (%rcx), %ymm3
movabsq $1023787248, %rcx # imm = 0x3D05C0F0
vpbroadcastq (%rcx), %ymm5
vpcmpeqd %ymm6, %ymm6, %ymm6
movabsq $1023787256, %rcx # imm = 0x3D05C0F8
vpbroadcastq (%rcx), %ymm7
movq %r8, %rcx
vpxor %xmm4, %xmm4, %xmm4
vpxor %xmm8, %xmm8, %xmm8
vpxor %xmm9, %xmm9, %xmm9
nopw %cs:(%rax,%rax)
; │ @ Julia_vs_Delphi.jl within `for_fun`
L224:
vpaddq %ymm2, %ymm1, %ymm10
; │ @ Julia_vs_Delphi.jl:10 within `for_fun`
vpxor %ymm3, %ymm1, %ymm11
vpcmpgtq %ymm11, %ymm5, %ymm11
vpxor %ymm3, %ymm10, %ymm10
vpcmpgtq %ymm10, %ymm5, %ymm10
vpsubq %ymm11, %ymm0, %ymm0
vpsubq %ymm10, %ymm4, %ymm4
vpaddq %ymm11, %ymm8, %ymm8
vpsubq %ymm6, %ymm8, %ymm8
vpaddq %ymm10, %ymm9, %ymm9
vpsubq %ymm6, %ymm9, %ymm9
vpaddq %ymm7, %ymm1, %ymm1
addq $-8, %rcx
jne L224
; │ @ Julia_vs_Delphi.jl:13 within `for_fun`
vpaddq %ymm8, %ymm9, %ymm1
vextracti128 $1, %ymm1, %xmm2
vpaddq %xmm2, %xmm1, %xmm1
vpshufd $238, %xmm1, %xmm2 # xmm2 = xmm1[2,3,2,3]
vpaddq %xmm2, %xmm1, %xmm1
vmovq %xmm1, %r11
vpaddq %ymm0, %ymm4, %ymm0
vextracti128 $1, %ymm0, %xmm1
vpaddq %xmm1, %xmm0, %xmm0
vpshufd $238, %xmm0, %xmm1 # xmm1 = xmm0[2,3,2,3]
vpaddq %xmm1, %xmm0, %xmm0
vmovq %xmm0, %rdx
cmpq %r8, %r9
je L386
L346:
leaq 1(%r9), %r8
nop
; │ @ Julia_vs_Delphi.jl:10 within `for_fun`
; │┌ @ operators.jl:378 within `>`
; ││┌ @ int.jl:83 within `<`
L352:
xorl %ecx, %ecx
cmpq $500000, %r10 # imm = 0x7A120
seta %cl
cmpq $500001, %r10 # imm = 0x7A121
; │└└
adcq $0, %rdx
addq %rcx, %r11
; │ @ Julia_vs_Delphi.jl:13 within `for_fun`
; │┌ @ range.jl:837 within `iterate`
incq %r10
; ││┌ @ promotion.jl:468 within `==`
cmpq %r10, %r8
; │└└
jne L352
; │ @ Julia_vs_Delphi.jl:17 within `for_fun`
L386:
movq %r9, (%rax)
movq %rdx, 8(%rax)
movq %r11, 16(%rax)
vmovaps -96(%rbp), %xmm6
vmovaps -80(%rbp), %xmm7
vmovaps -64(%rbp), %xmm8
vmovaps -48(%rbp), %xmm9
vmovaps -32(%rbp), %xmm10
vmovaps -16(%rbp), %xmm11
addq $96, %rsp
popq %rbp
vzeroupper
retq
nopw %cs:(%rax,%rax)