返回组合
使用数字表或生成数字的CTE,选择0到2^n-1。使用这些数字中包含1的位位置来表示组合中相对成员的存在或缺失,并消除那些没有正确数量值的组合,您应该能够返回所需的所有组合的结果集。
WITH Nums (Num) AS (
SELECT Num
FROM Numbers
WHERE Num BETWEEN 0 AND POWER(2, @n) - 1
), BaseSet AS (
SELECT ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), *
FROM @set
), Combos AS (
SELECT
ComboID = N.Num,
S.Value,
Cnt = Count(*) OVER (PARTITION BY N.Num)
FROM
Nums N
INNER JOIN BaseSet S ON N.Num & S.ind <> 0
)
SELECT
ComboID,
Value
FROM Combos
WHERE Cnt = @k
ORDER BY ComboID, Value;
这个查询表现得相当不错,但是我想到了一种优化它的方法,借鉴了Nifty Parallel Bit Count的思路,首先获取每次取出的正确数量。这样做可以让查询速度提高3至3.5倍(无论是CPU还是时间方面):
WITH Nums AS (
SELECT Num, P1 = (Num & 0x55555555) + ((Num / 2) & 0x55555555)
FROM dbo.Numbers
WHERE Num BETWEEN 0 AND POWER(2, @n) - 1
), Nums2 AS (
SELECT Num, P2 = (P1 & 0x33333333) + ((P1 / 4) & 0x33333333)
FROM Nums
), Nums3 AS (
SELECT Num, P3 = (P2 & 0x0f0f0f0f) + ((P2 / 16) & 0x0f0f0f0f)
FROM Nums2
), BaseSet AS (
SELECT ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), *
FROM @set
)
SELECT
ComboID = N.Num,
S.Value
FROM
Nums3 N
INNER JOIN BaseSet S ON N.Num & S.ind <> 0
WHERE P3 % 255 = @k
ORDER BY ComboID, Value;
我去读了位计数页面,认为如果不使用% 255而是全程使用位运算,这可能会表现得更好。等我有机会时,我会尝试一下,看看效果如何。
我的性能声明基于运行没有ORDER BY子句的查询。为了清晰起见,这段代码正在计算Numbers表中Num的设置1位数。这是因为该数字被用作选择当前组合中哪些元素的索引器,因此1位数的数量将相同。
希望你喜欢!
值得一提的是,使用整数的位模式来选择集合成员的这种技术是我所创造的“垂直交叉连接”。它有效地导致多个数据集的交叉连接,其中集的数量和交叉连接是任意的。在这里,集的数量是每次获取的项目数量。
实际上,通常的水平交叉连接(通过每次加入更多列到现有列列表来进行)看起来像这样:
SELECT
A.Value,
B.Value,
C.Value
FROM
@Set A
CROSS JOIN @Set B
CROSS JOIN @Set C
WHERE
A.Value = 'A'
AND B.Value = 'B'
AND C.Value = 'C'
我的上述查询实际上会与只有一个连接的交叉连接一样多次交叉连接。与实际的交叉连接相比,结果是未旋转的,但这只是小问题。
您代码的评审
首先,我建议您对Factorial UDF进行以下更改:
ALTER FUNCTION dbo.Factorial (
@x bigint
)
RETURNS bigint
AS
BEGIN
IF @x <= 1 RETURN 1
RETURN @x * dbo.Factorial(@x - 1)
END
现在您可以计算更大的组合集,而且更加高效。您甚至可以考虑使用
decimal(38, 0)来允许在组合计算中进行更大的中间计算。
其次,您给出的查询并没有返回正确的结果。例如,使用下面性能测试中的测试数据,集1与集18相同。看起来您的查询采用了一个滑动条纹进行包装:每个集合始终是5个相邻成员,看起来像这样(我进行了旋转以便于查看):
1 ABCDE
2 ABCD Q
3 ABC PQ
4 AB OPQ
5 A NOPQ
6 MNOPQ
7 LMNOP
8 KLMNO
9 JKLMN
10 IJKLM
11 HIJKL
12 GHIJK
13 FGHIJ
14 EFGHI
15 DEFGH
16 CDEFG
17 BCDEF
18 ABCDE
19 ABCD Q
比较一下我的查询中的模式:
31 ABCDE
47 ABCD F
55 ABC EF
59 AB DEF
61 A CDEF
62 BCDEF
79 ABCD G
87 ABC E G
91 AB DE G
93 A CDE G
94 BCDE G
103 ABC FG
107 AB D FG
109 A CD FG
110 BCD FG
115 AB EFG
117 A C EFG
118 BC EFG
121 A DEFG
...
如果有人对将比特模式转换为组合索引感兴趣,可以注意到31的二进制表示为11111,模式为ABCDE。121的二进制表示为1111001,模式为A__DEFG(反向映射)。
使用实数表进行性能测试结果
我对我的第二个查询运行了一些大数据集的性能测试。目前我没有记录所使用的服务器版本。这是我的测试数据:
DECLARE
@k int,
@n int;
DECLARE @set TABLE (value varchar(24));
INSERT @set VALUES ('A'),('B'),('C'),('D'),('E'),('F'),('G'),('H'),('I'),('J'),('K'),('L'),('M'),('N'),('O'),('P'),('Q');
SET @n = @@RowCount;
SET @k = 5;
DECLARE @combinations bigint = dbo.Factorial(@n) / (dbo.Factorial(@k) * dbo.Factorial(@n - @k));
SELECT CAST(@combinations as varchar(max)) + ' combinations', MaxNumUsedFromNumbersTable = POWER(2, @n);
Peter展示了这种“垂直交叉连接”并不像编写动态SQL来执行CROSS JOIN那样表现出色。在稍微增加一些读取成本的情况下,他的解决方案指标提高了10到17倍。随着工作量的增加,他的查询性能下降得比我的更快,但并不足以阻止任何人使用它。
下面的第二组数字是相对于表中第一行的因子,只是为了显示它的缩放程度。
Erik
Items CPU Writes Reads Duration | CPU Writes Reads Duration
----- ------ ------ ------- -------- | ----- ------ ------ --------
17•5 7344 0 3861 8531 |
18•9 17141 0 7748 18536 | 2.3 2.0 2.2
20•10 76657 0 34078 84614 | 10.4 8.8 9.9
21•11 163859 0 73426 176969 | 22.3 19.0 20.7
21•20 142172 0 71198 154441 | 19.4 18.4 18.1
Peter
Items CPU Writes Reads Duration | CPU Writes Reads Duration
----- ------ ------ ------- -------- | ----- ------ ------ --------
17•5 422 70 10263 794 |
18•9 6046 980 219180 11148 | 14.3 14.0 21.4 14.0
20•10 24422 4126 901172 46106 | 57.9 58.9 87.8 58.1
21•11 58266 8560 2295116 104210 | 138.1 122.3 223.6 131.3
21•20 51391 5 6291273 55169 | 121.8 0.1 613.0 69.5
推测来看,我的查询最终会变得更加便宜(尽管从一开始就是读取的),但需要很长时间。使用集合中的21个项目已经需要一个数字表,最高达到2097152...
这是我最初发表的评论,在意识到我的解决方案可以通过即时数字表显著提高性能之前:
我喜欢单查询解决此类问题的方式,但如果您正在寻找最佳性能,则实际交叉连接最好,除非您开始处理严重数量级的组合。但是,有谁需要成千上万甚至数百万行?即使不断增加的阅读量似乎也不是太大的问题,尽管600万是很多,并且正在快速增长...
无论如何。动态SQL胜利了。我仍然有一个漂亮的查询。 :)
使用即时数字表的性能结果
当我最初撰写这个答案时,我说:
请注意,您可以使用即时数字表,但我还没有尝试过。
好吧,我尝试了一下,结果表现要好得多!以下是我使用的查询:
DECLARE @N int = 16, @K int = 12;
CREATE TABLE #Set (Value char(1) PRIMARY KEY CLUSTERED);
CREATE TABLE #Items (Num int);
INSERT #Items VALUES (@K);
INSERT #Set
SELECT TOP (@N) V
FROM
(VALUES ('A'),('B'),('C'),('D'),('E'),('F'),('G'),('H'),('I'),('J'),('K'),('L'),('M'),('N'),('O'),('P'),('Q'),('R'),('S'),('T'),('U'),('V'),('W'),('X'),('Y'),('Z')) X (V);
GO
DECLARE
@N int = (SELECT Count(*) FROM #Set),
@K int = (SELECT TOP 1 Num FROM #Items);
DECLARE @combination int, @value char(1);
WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),
L1 AS (SELECT 1 N FROM L0, L0 B),
L2 AS (SELECT 1 N FROM L1, L1 B),
L3 AS (SELECT 1 N FROM L2, L2 B),
L4 AS (SELECT 1 N FROM L3, L3 B),
L5 AS (SELECT 1 N FROM L4, L4 B),
Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FROM L5),
Nums1 AS (
SELECT Num, P1 = (Num & 0x55555555) + ((Num / 2) & 0x55555555)
FROM Nums
WHERE Num BETWEEN 0 AND Power(2, @N) - 1
), Nums2 AS (
SELECT Num, P2 = (P1 & 0x33333333) + ((P1 / 4) & 0x33333333)
FROM Nums1
), Nums3 AS (
SELECT Num, P3 = (P2 & 0x0F0F0F0F) + ((P2 / 16) & 0x0F0F0F0F)
FROM Nums2
), BaseSet AS (
SELECT Ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), *
FROM #Set
)
SELECT
@Combination = N.Num,
@Value = S.Value
FROM
Nums3 N
INNER JOIN BaseSet S
ON N.Num & S.Ind <> 0
WHERE P3 % 255 = @K;
请注意,我选择将值存储到变量中以减少测试所需的时间和内存。服务器仍然执行相同的工作。我修改了Peter的版本使其类似,并删除了不必要的额外内容,使它们尽可能精简。这些测试使用的服务器版本是
Microsoft SQL Server 2008 (RTM) - 10.0.1600.22 (Intel X86) Standard Edition on Windows NT 5.2 <X86> (Build 3790: Service Pack 2) (VM)在虚拟机上运行。
以下是显示N和K值的性能曲线图,最高为21。它们的基础数据在本页上的另一个回答中。这些值是在每个K和N值下运行每个查询5次的结果,然后丢弃每个指标的最佳和最差值,并对其余3个求平均数。
基本上,我的版本在N值很高和K值很低时有一个“肩膀”(在图表的最左边角落),使其在那里的表现比动态SQL版本更差。然而,这个表现保持得相当低和稳定,而且在N = 21 和K = 11周围的中心峰值的持续时间、CPU和读取方面都比动态SQL版本低得多。
我还包括了一个图表,显示每个项预计返回的行数,以便您可以看到查询与其需要执行的工作量相比的性能。
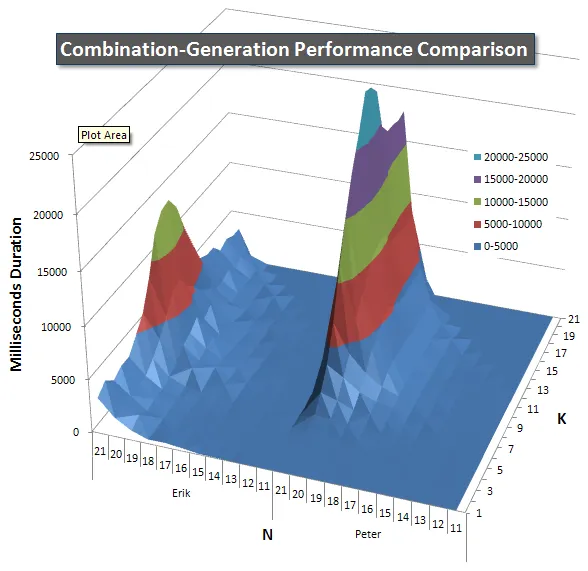
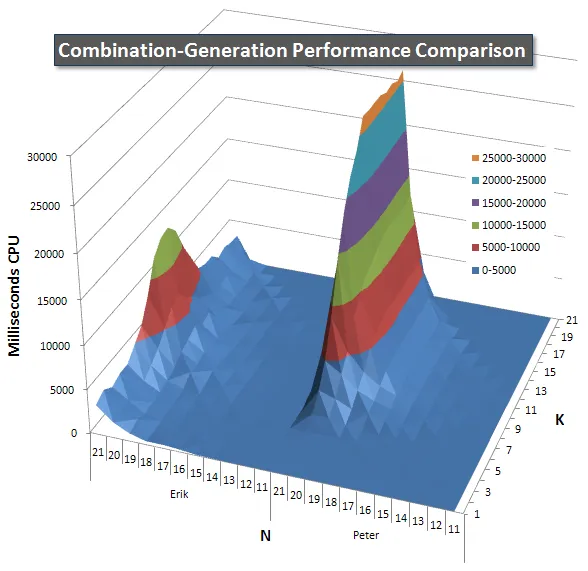
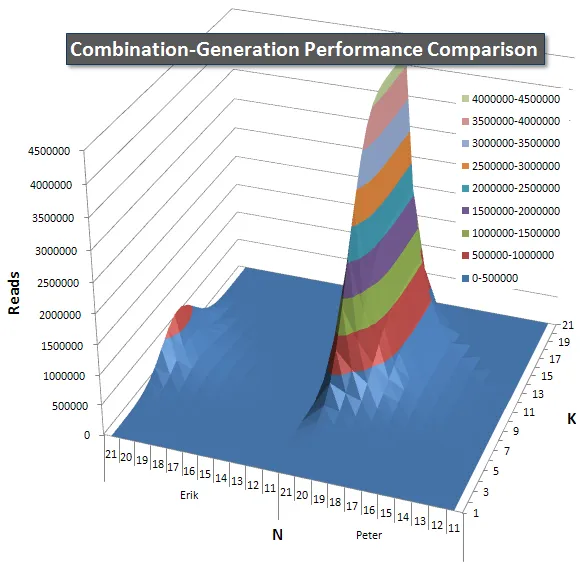
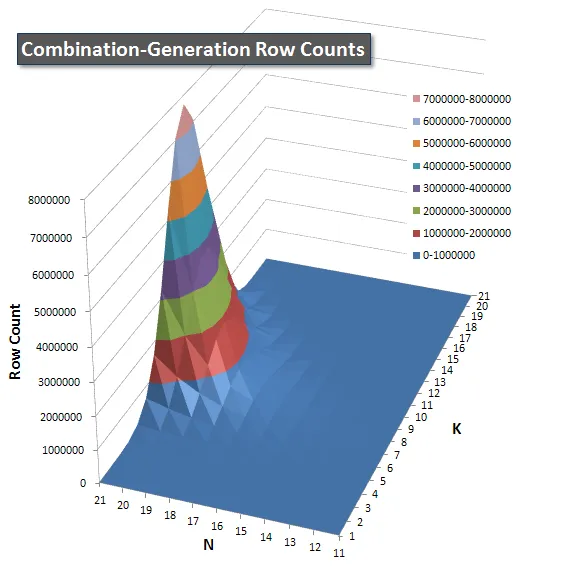
请查看
此页面上我附加的答案以获取完整的性能结果。我达到了发布字符限制,无法在此处包含它。(有什么其他地方可以放吗?)为了将事物放在与我第一个版本的性能结果相比的透视中,这里是与之前相同的格式:
Erik
Items CPU Duration Reads Writes | CPU Duration Reads
----- ----- -------- ------- ------ | ----- -------- -------
17•5 354 378 12382 0 |
18•9 1849 1893 97246 0 | 5.2 5.0 7.9
20•10 7119 7357 369518 0 | 20.1 19.5 29.8
21•11 13531 13807 705438 0 | 38.2 36.5 57.0
21•20 3234 3295 48 0 | 9.1 8.7 0.0
彼得
Items CPU Duration Reads Writes | CPU Duration Reads
17•5 41 45 6433 0 |
18•9 2051 1522 214021 0 | 50.0 33.8 33.3
20•10 8271 6685 864455 0 | 201.7 148.6 134.4
21•11 18823 15502 2097909 0 | 459.1 344.5 326.1
21•20 25688 17653 4195863 0 | 626.5 392.3 652.2
结论
- 即时生成数字表比包含行的真实表更好,因为在读取大量行时需要大量I/O。使用一些 CPU 更好。
- 我的初始测试范围不够广,无法真正展示两个版本的性能特征。
- Peter 的版本可以通过使每个 JOIN 不仅比前一个项目大,而且还基于有多少个项目需要适合集合来限制最大值来改进。例如,在 21 个项目中,每次拿出 21 个项目,只有一个答案是 21 行(所有 21 个项目,一次),但是动态 SQL 版本在执行计划早期的中间行集中包含诸如“AU”之类的组合,即使在下一个连接中将被丢弃,因为没有比“U”更高的值可用。同样,在第 5 步的中间行集中将包含“ARSTU”,但此时唯一有效的组合是“ABCDE”。这个改进版本不会在中心处有更低的峰值,因此可能不足以成为明显的赢家,但它至少会变得对称,以便图表不会在区域中间保持最大化,而是会像我的版本一样回落到接近 0(请参见每个查询的峰顶的顶部角落)。
持续时间分析
- 直到12个项目中取14个,版本之间的持续时间没有真正显着的差异(>100ms)。在此之前,我的版本获胜30次,动态SQL版本获胜43次。
- 从14•12开始,我的版本更快65次(59 >100ms),动态SQL版本更快64次(60 >100ms)。然而,在我版本更快的所有时候,它节省了平均256.5秒的总持续时间,而当动态SQL版本更快时,它节省了80.2秒。
- 所有试验的平均持续时间为Erik 270.3秒,Peter 446.2秒。
- 如果创建一个查找表来确定使用哪个版本(为输入选择更快的版本),则所有结果可以在188.7秒内执行。每次使用最慢的版本将需要527.7秒。
读取分析
持续时间分析显示我的查询赢得了相当大但不是过分大的优势。当指标切换到读取时,出现了非常不同的情况——我的查询平均使用1/10的读取。
- 直到每次取9个项目时,我的版本和动态SQL版本在读取方面(>1000)没有真正显着的差异。到这一点,我的版本赢了30次,动态SQL版本赢了17次。
- 从9•9开始,我的版本使用较少的读取118次(113>1000),动态SQL版本使用较少的读取69次(31>1000)。然而,在我版本使用较少读取的所有时间中,它平均节省了75.9M的读取量,而当动态SQL版本更快时,它只节省了380K的读取量。
- 所有试验的平均读取量为Erik 8.4M,Peter 84M。
- 如果创建一个查找表来确定要使用哪个版本(选择最佳版本用于输入),则所有结果可以在8M读取中执行。每次都使用最差的版本将需要84.3M的读取。
我非常想看到更新的动态SQL版本的结果,该版本在每个步骤上选择了额外的上限,如上所述。
附录
以下版本的查询比上面列出的性能结果提高了约2.25%。我使用了MIT的HAKMEM位计数方法,并在row_number()的结果上添加了Convert(int),因为它返回一个bigint。当然,我希望这是我用于所有性能测试、图表和数据的版本,但由于它需要耗费大量人力,我不太可能重新进行。
WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),
L1 AS (SELECT 1 N FROM L0, L0 B),
L2 AS (SELECT 1 N FROM L1, L1 B),
L3 AS (SELECT 1 N FROM L2, L2 B),
L4 AS (SELECT 1 N FROM L3, L3 B),
L5 AS (SELECT 1 N FROM L4, L4 B),
Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FROM L5),
Nums1 AS (
SELECT Convert(int, Num) Num
FROM Nums
WHERE Num BETWEEN 1 AND Power(2, @N) - 1
), Nums2 AS (
SELECT
Num,
P1 = Num - ((Num / 2) & 0xDB6DB6DB) - ((Num / 4) & 0x49249249)
FROM Nums1
),
Nums3 AS (SELECT Num, Bits = ((P1 + P1 / 8) & 0xC71C71C7) % 63 FROM Nums2),
BaseSet AS (SELECT Ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM #Set)
SELECT
N.Num,
S.Value
FROM
Nums3 N
INNER JOIN BaseSet S
ON N.Num & S.Ind <> 0
WHERE
Bits = @K
我忍不住想展示另一种版本,它通过查找来获取位数的数量。它甚至可能比其他版本更快:
DECLARE @BitCounts binary(255) =
0x01010201020203010202030203030401020203020303040203030403040405
+ 0x0102020302030304020303040304040502030304030404050304040504050506
+ 0x0102020302030304020303040304040502030304030404050304040504050506
+ 0x0203030403040405030404050405050603040405040505060405050605060607
+ 0x0102020302030304020303040304040502030304030404050304040504050506
+ 0x0203030403040405030404050405050603040405040505060405050605060607
+ 0x0203030403040405030404050405050603040405040505060405050605060607
+ 0x0304040504050506040505060506060704050506050606070506060706070708;
WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),
L1 AS (SELECT 1 N FROM L0, L0 B),
L2 AS (SELECT 1 N FROM L1, L1 B),
L3 AS (SELECT 1 N FROM L2, L2 B),
L4 AS (SELECT 1 N FROM L3, L3 B),
L5 AS (SELECT 1 N FROM L4, L4 B),
Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FROM L5),
Nums1 AS (SELECT Convert(int, Num) Num FROM Nums WHERE Num BETWEEN 1 AND Power(2, @N) - 1),
BaseSet AS (SELECT Ind = Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM ComboSet)
SELECT
@Combination = N.Num,
@Value = S.Value
FROM
Nums1 N
INNER JOIN BaseSet S
ON N.Num & S.Ind <> 0
WHERE
@K =
Convert(int, Substring(@BitCounts, N.Num & 0xFF, 1))
+ Convert(int, Substring(@BitCounts, N.Num / 256 & 0xFF, 1))
+ Convert(int, Substring(@BitCounts, N.Num / 65536 & 0xFF, 1))
+ Convert(int, Substring(@BitCounts, N.Num / 16777216, 1))
n!/(k!(n-k)!) = (n-k+1)(n-k+2)...n/(n-k)!- Denis Valeev