尝试了一些性能分析。我认为使用生成器可能会提高速度。但与对原始代码进行轻微修改相比,改进并不明显。但是,如果您不需要同时查看完整列表,则生成器函数应该更快。
import timeit
from itertools import tee, izip, islice
def isplit(source, sep):
sepsize = len(sep)
start = 0
while True:
idx = source.find(sep, start)
if idx == -1:
yield source[start:]
return
yield source[start:idx]
start = idx + sepsize
def pairwise(iterable, n=2):
return izip(*(islice(it, pos, None) for pos, it in enumerate(tee(iterable, n))))
def zipngram(text, n=2):
return zip(*[text.split()[i:] for i in range(n)])
def zipngram2(text, n=2):
words = text.split()
return pairwise(words, n)
def zipngram3(text, n=2):
words = text.split()
return zip(*[words[i:] for i in range(n)])
def zipngram4(text, n=2):
words = isplit(text, ' ')
return pairwise(words, n)
s = "Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
s = s * 10 ** 3
res = []
for n in range(15):
a = timeit.timeit('zipngram(s, n)', 'from __main__ import zipngram, s, n', number=100)
b = timeit.timeit('list(zipngram2(s, n))', 'from __main__ import zipngram2, s, n', number=100)
c = timeit.timeit('zipngram3(s, n)', 'from __main__ import zipngram3, s, n', number=100)
d = timeit.timeit('list(zipngram4(s, n))', 'from __main__ import zipngram4, s, n', number=100)
res.append((a, b, c, d))
a, b, c, d = zip(*res)
import matplotlib.pyplot as plt
plt.plot(a, label="zipngram")
plt.plot(b, label="zipngram2")
plt.plot(c, label="zipngram3")
plt.plot(d, label="zipngram4")
plt.legend(loc=0)
plt.show()
对于这个测试数据,zipngram2和zipngram3似乎是速度最快的。
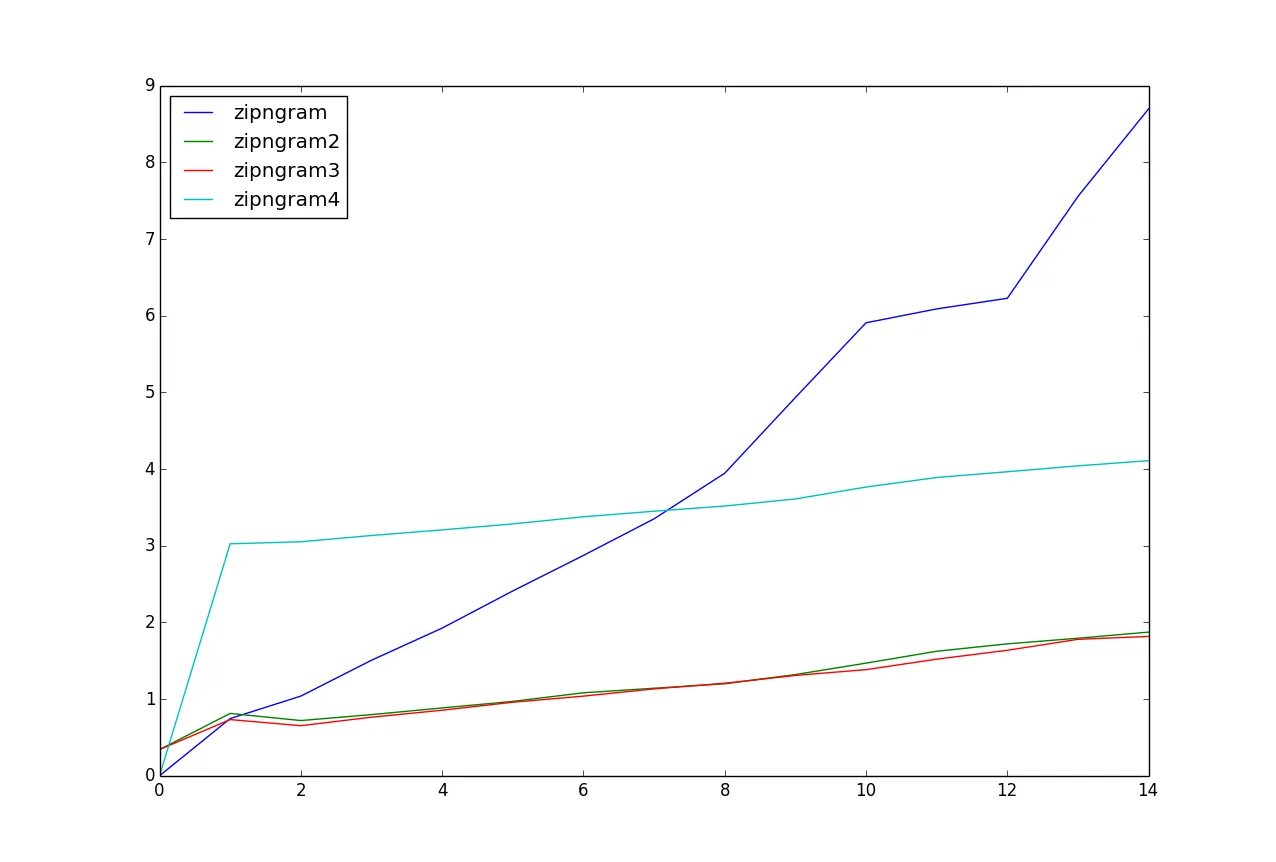
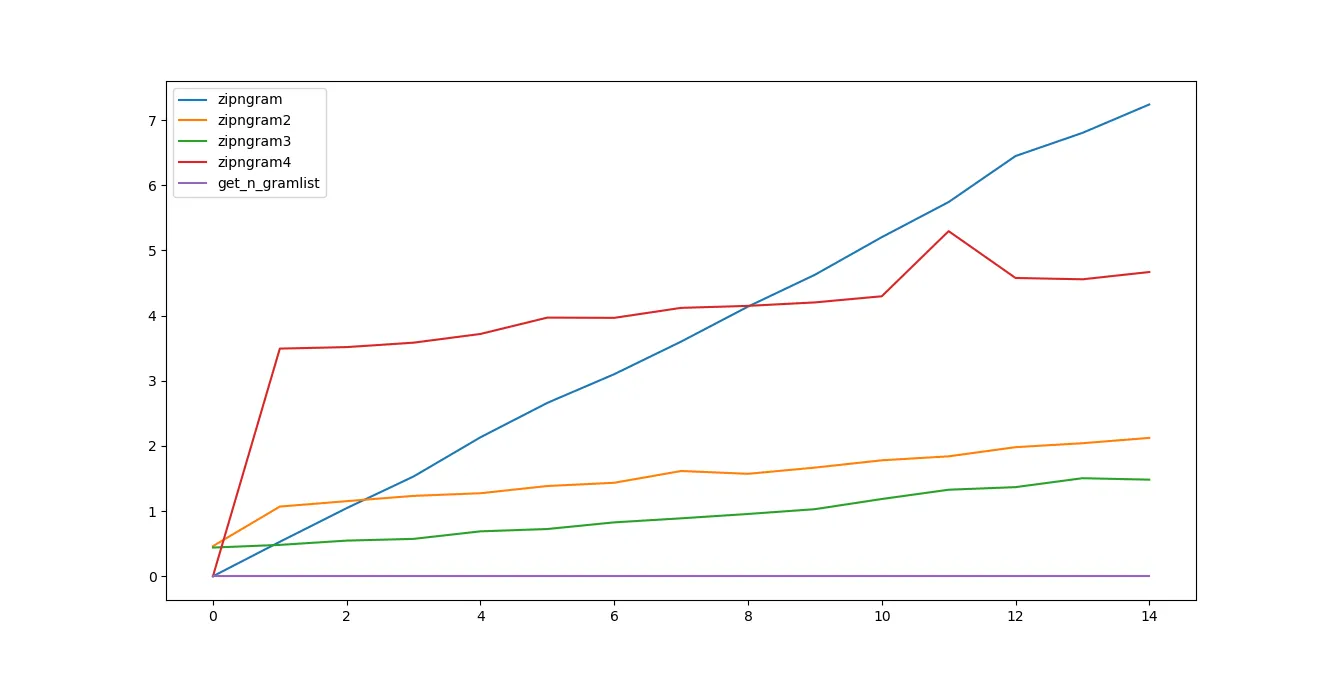
n值编写单独的函数吗?在zipngram中硬编码并删除列表表达式可以在一些粗略的实验中提供1.5-2倍的加速。 - dmcccffi实现的C代码算不算?虽然如果字母表是Unicode而不是ACSII,则这些实现并不容易。如果是后者,SSE汇编可能会更快。此外,如果文本足够长,您可能希望将工作分配到多个核心上。 - Dima Tisnek