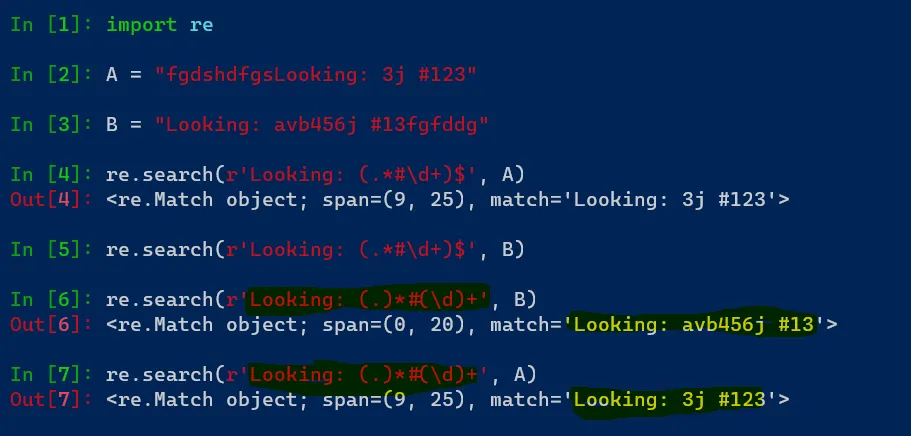
在Python中,我们如何使用re从字符串中获取以下子字符串。
string1 = "fgdshdfgsLooking: 3j #123"
substring = "Looking: 3j #123"
string2 = "Looking: avb456j #13fgfddg"
substring = "Looking: avb456j #13"
尝试:
re.search(r'Looking: (.*#\d+)$', string1)