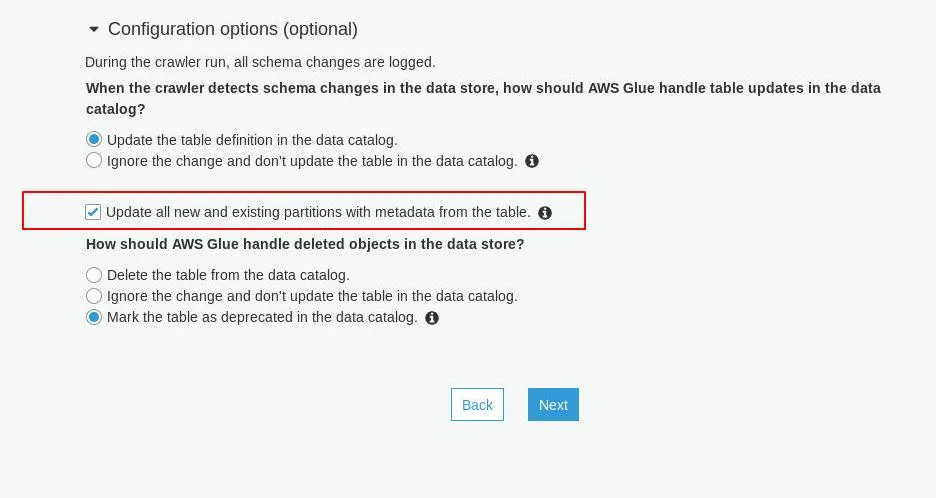
根据这个AWS论坛帖子,有人知道如何使用AWS Glue创建一个包含不同模式的AWS Athena表的分区(在这种情况下,从表模式中选择不同的列子集)吗?
目前,当我在这些数据上运行爬虫,然后在Athena中进行查询时,会出现错误
- 分区代表天 - 文件代表事件 - 每个事件是单个s3文件中的json blob - 事件包含不同列的子集(取决于事件类型) - 整个表的“模式”是所有事件类型的完整列集(由Glue爬虫正确组合) - 每个分区的“模式”是发生在那一天的事件类型的列子集(因此在Glue中,每个分区可能具有来自表模式的不同列子集) - 这种不一致导致了Athena中的错误
如果我要手动编写架构,我可以做到这一点,因为只会有一个表架构,并且JSON文件中缺少的键将被视为Nulls。
提前感谢!
目前,当我在这些数据上运行爬虫,然后在Athena中进行查询时,会出现错误
'HIVE_PARTITION_SCHEMA_MISMATCH'
我的用例是:- 分区代表天 - 文件代表事件 - 每个事件是单个s3文件中的json blob - 事件包含不同列的子集(取决于事件类型) - 整个表的“模式”是所有事件类型的完整列集(由Glue爬虫正确组合) - 每个分区的“模式”是发生在那一天的事件类型的列子集(因此在Glue中,每个分区可能具有来自表模式的不同列子集) - 这种不一致导致了Athena中的错误
如果我要手动编写架构,我可以做到这一点,因为只会有一个表架构,并且JSON文件中缺少的键将被视为Nulls。
提前感谢!