我正在尝试实现一种近似算法来解决旅行商问题(TSP),该算法仅在边权满足三角不等式时可用。如Cormen等人所述,《算法导论》(第3版)中的伪代码如下:

这里有一个例子:
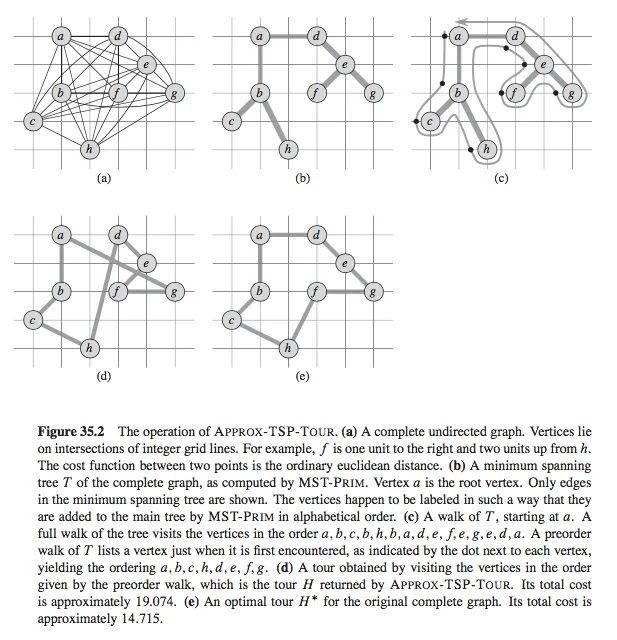
相反,节点具有键和父属性,而非左右属性。以下是我的Prim算法实现(带有一个小测试案例)中它们是如何生成的:
import math
import copy
import pytest
import pandas as pd
from cached_property import cached_property
class Node(object):
def __init__(self, key=math.inf, parent=None):
self.key = key
self.parent = parent
def __lt__(self, other):
return self.key < other.key
class Graph(object):
def __init__(self, edges):
self.edges = edges
@cached_property
def nodes(self):
_nodes = set()
for edge in self.edges:
_nodes.add(edge[0])
_nodes.add(edge[1])
return {node: Node() for node in list(_nodes)}
@cached_property
def adj(self):
A = {node: [] for node in self.nodes}
for edge in self.edges:
u, v, _ = edge
A[u].append(v)
A[v].append(u)
return A
@cached_property
def w(self):
N = len(self.nodes)
none_array = [[None for _ in range(N)] for _ in range(N)]
df = pd.DataFrame(none_array, index=sorted(self.nodes), columns=sorted(self.nodes))
for edge in self.edges:
u, v, weight = edge
df.set_value(u, v, weight)
df.set_value(v, u, weight)
return df
def mst_prim(self, root):
r = self.nodes[root]
r.key = 0
Q = copy.copy(self.nodes)
while Q:
u = min(Q, key=Q.get)
u_node = Q.pop(u)
for v in self.adj[u]:
if v in Q and self.w[u][v] < self.nodes[v].key:
self.nodes[v].parent = u
self.nodes[v].key = self.w[u][v]
@pytest.fixture
def edges_simple():
return [('a', 'b', 4),
('a', 'h', 8),
('b', 'h', 11),
('h', 'i', 7),
('b', 'c', 8),
('h', 'g', 1),
('i', 'c', 2),
('i', 'g', 6),
('c', 'd', 7),
('g', 'f', 2),
('c', 'f', 4),
('d', 'f', 14),
('d', 'e', 9),
('f', 'e', 10)
]
def test_mst_prim(edges_simple):
graph = Graph(edges_simple)
graph.mst_prim(root='a')
# print("\n")
# for u, node in graph.nodes.items():
# print(u, node.__dict__)
assert graph.nodes['a'].parent is None
assert graph.nodes['i'].parent == 'c'
assert graph.nodes['d'].parent == 'c'
if __name__ == "__main__":
# pytest.main([__file__+"::test_mst_prim", "-s"])
pytest.main([__file__, "-s"])
我该如何对这个图执行先序树遍历?(请注意,这个问题类似于 最小生成树的先序遍历,但我发现那里给出的答案比较高级。)