在C++0x中的原子变量文档中,关于内存顺序的描述中提到:
释放-获取顺序
在强序系统(x86、SPARC、IBM大型机)上,自动执行释放-获取顺序。对于此同步模式,不会发出任何其他CPU指令,只会影响某些编译器优化...
首先,x86是否遵循严格的内存顺序?似乎总是强制执行这一点非常低效。这意味着每个写和读操作都需要一个栅栏吗?
另外,如果我有一个对齐的int,在x86系统上,原子变量是否有任何作用?
释放-获取顺序
在强序系统(x86、SPARC、IBM大型机)上,自动执行释放-获取顺序。对于此同步模式,不会发出任何其他CPU指令,只会影响某些编译器优化...
首先,x86是否遵循严格的内存顺序?似乎总是强制执行这一点非常低效。这意味着每个写和读操作都需要一个栅栏吗?
另外,如果我有一个对齐的int,在x86系统上,原子变量是否有任何作用?
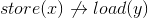
volatile关键字只能在某些编译器中起作用(作为扩展)。这就是为什么标准添加了atomic<>的原因。 - Bo Perssonvolatile并不一定能使读-改-写操作具有原子性。如果你对一个volatile变量执行x++操作,编译器可以将x读入寄存器,增加寄存器的值,然后将寄存器的值存回内存中。 - Adam Rosenfieldvolatile的可观察行为必须是单独的读和写。 - MSaltersoperator++。你不能使用std::atomic<T>写x=x+1,因为这些对象不可复制分配,原因正是这样做是非原子的。 - Adam Rosenfield