最近我设计了一个儿童解谜游戏。然而,我想知道最优解。
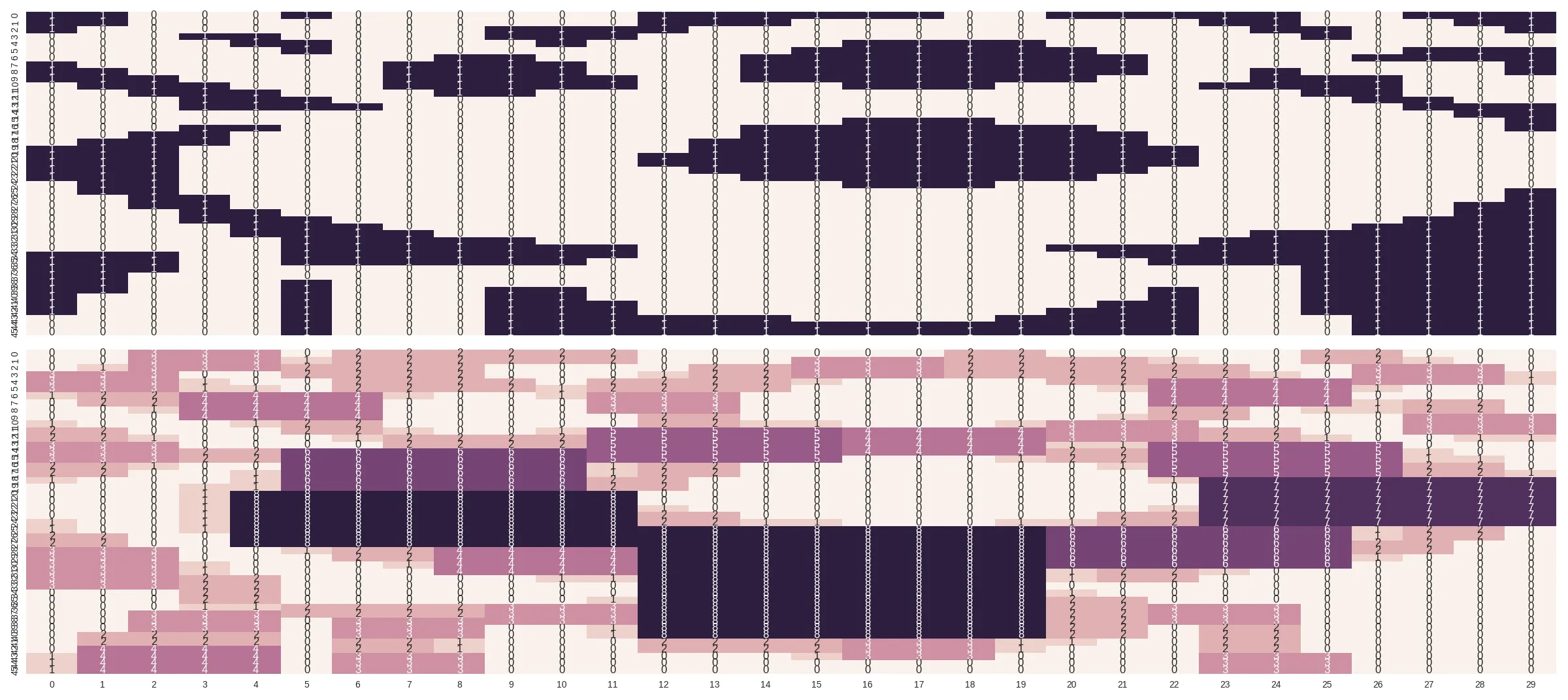
问题如下:你有这样一个由小正方形组成的图案

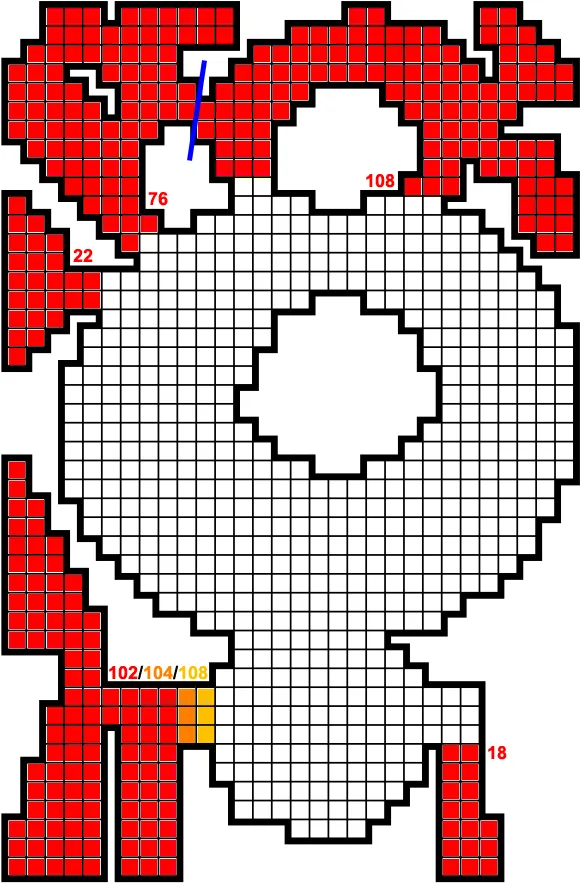
你必须用较大的正方形填充它,并按以下表格进行评分:
| Square Size | 1x1 | 2x2 | 3x3 | 4x4 | 5x5 | 6x6 | 7x7 | 8x8 |
|-------------|-----|-----|-----|-----|-----|-----|-----|-----|
| Points | 0 | 4 | 10 | 20 | 35 | 60 | 84 | 120 |
有太多可能的解决方案需要检查。其他人建议使用动态规划,但我不知道如何将图形分成较小的部分,这些部分放在一起具有相同的最优解。
我希望能够找到一种在合理时间内(如在常规桌面上的几天内)找到这类问题最优解的方法。迄今为止,通过猜测算法和一些手动工作找到的最高分数为1112。
欢迎提供类似问题的解决方案,包括组合子问题的解决方案。我不需要所有代码都写出来,一个算法的大纲或想法就足够了。
注意:最大适合的正方形是8x8,因此不包括更大正方形的得分。
[[1,1,0,0,0,1,0,0,0,0,0,0,1,1,1,1,1,1,0,0,1,1,1,1,1,0,0,1,1,1],
[1,1,0,0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,1,1,0,0,0,1,1],
[1,0,0,0,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,1,1,0,0,0,1],
[0,0,0,1,1,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,1,1,0,0,0,0,1,0,0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,0,0,0,0,0,0,1,1,1],
[0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,1,1,1,1],
[1,0,0,0,0,0,0,1,1,1,1,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,1],
[1,1,0,0,0,0,0,1,1,1,1,0,0,0,1,1,1,1,1,1,1,1,0,0,1,0,0,0,0,1],
[1,1,1,0,0,0,0,1,1,1,1,1,0,0,1,1,1,1,1,1,1,0,0,0,1,1,1,0,0,0],
[0,1,1,1,0,0,0,1,1,1,1,1,0,0,0,0,1,1,1,0,0,0,0,1,1,1,1,0,0,0],
[0,0,1,1,1,0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,0,0,0],
[0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,0,0],
[0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,1],
[0,0,0,1,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,1],
[0,0,1,1,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0],
[0,1,1,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0],
[1,1,1,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0],
[1,1,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0],
[1,1,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0],
[1,1,1,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0],
[1,1,1,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0],
[0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0],
[0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],
[0,0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],
[0,0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1],
[0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1],
[0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1],
[0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1],
[0,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1],
[0,0,0,0,0,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1],
[0,0,0,0,0,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1],
[1,1,1,0,0,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1],
[1,1,1,0,0,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1],
[1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1],
[1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1],
[1,1,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1],
[1,1,0,0,0,1,0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,0,1,0,0,1,1,1,1,1],
[1,0,0,0,0,1,0,0,0,1,1,0,0,0,0,0,0,0,0,0,0,0,1,0,0,1,1,1,1,1],
[1,0,0,0,0,1,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,1,1,0,0,1,1,1,1,1],
[1,0,0,0,0,1,0,0,0,1,1,1,0,0,0,0,0,0,0,0,1,1,1,0,0,1,1,1,1,1],
[0,0,0,0,0,1,0,0,0,1,1,1,1,1,1,0,0,0,0,1,1,1,1,0,0,0,1,1,1,1],
[0,0,0,0,0,1,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1],
[0,0,0,0,0,1,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]];