请帮我解决这个问题(如需更好的理解,请参见附图),因为我完全无助。
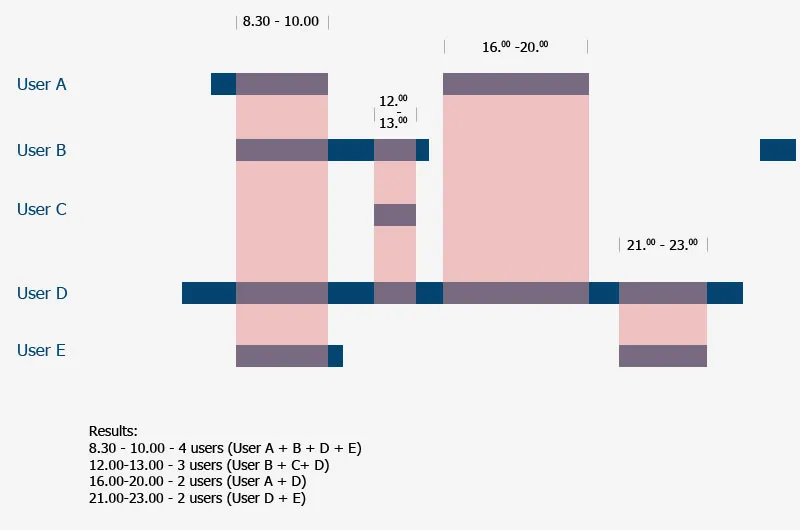
如您所见,我的用户在我的数据库中存储其开始和结束的日期时间为YYYY-mm-dd H:i:s。现在,我需要根据最常见的时间范围重叠(对于大多数用户)找出所有用户的重叠部分。我想获得大多数用户的前3个最常见的datatime重叠。我该怎么做?
我不知道应该使用哪个mysql查询,或者从数据库选择所有日期时间(开始和结束)并在php中处理它(但是如何处理呢?)。 如图所示,结果应该例如时间8:30 - 10:00是用户A + B + C + D的结果。
Table structure:
UserID | Start datetime | End datetime
--------------------------------------
A | 2012-04-03 4:00:00 | 2012-04-03 10:00:00
A | 2012-04-03 16:00:00 | 2012-04-03 20:00:00
B | 2012-04-03 8:30:00 | 2012-04-03 14:00:00
B | 2012-04-06 21:30:00 | 2012-04-06 23:00:00
C | 2012-04-03 12:00:00 | 2012-04-03 13:00:00
D | 2012-04-01 01:00:01 | 2012-04-05 12:00:59
E | 2012-04-03 8:30:00 | 2012-04-03 11:00:00
E | 2012-04-03 21:00:00 | 2012-04-03 23:00:00