我有一个外部模块,该模块返回一些字符串。我不确定字符串是如何返回的。我真的不知道Unicode字符串的工作原理和原因。
例如,该模块应返回捷克语单词"být",意思是"to be"。(如果您看不到第二个字母-它应该看起来像this。)如果我使用Data Dumper显示由模块返回的字符串,我会看到b\x{fd}t。
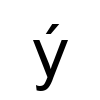{kind=link}
但是,如果我尝试使用print $s打印它,我会得到"在打印中宽字符"的警告,并且会用?代替ý。
如果我尝试Encode::decode(whatever, $s);,生成的字符串无论我在whatever中输入什么,都无法打印(始终带有“宽字符”警告,有时是乱码,有时是正确的)。
如果我尝试Encode::encode("utf-8", $s);,则生成的字符串可以正常打印,没有问题或错误消息。
use encoding 'utf8';,那么打印输出就不需要任何编码/解码。然而,如果我使用IO::CaptureOutput或Capture::Tiny模块,它会再次报出“Wide character”的错误。我有一些问题,主要是关于到底发生了什么。 (我尝试阅读过perldocs,但是我并没有从中获得太多智慧)
- 为什么我不能在从模块获取字符串后立即打印它?
- 为什么我无法打印经过“decode”解码的字符串?“decode”到底做了什么?
- “encode”到底做了什么,为什么在编码后打印时没有问题?
use encoding到底做了什么?为什么默认编码与utf-8不同?- 如果我想要在使用其中一个捕获模块时打印标量而不会出现任何问题,我该怎么办?
编辑:有些人告诉我使用-C、binmode或PERL_UNICODE。这是一个很好的建议。然而,不知何故,两个捕获模块神奇地破坏了STDOUT的UTF8性质。这似乎更像是模块的一个错误,但我不确定。
编辑2:好吧,最好的解决方案是放弃这些模块,自己编写“捕获”(灵活性要少得多)。