什么是在Java中从字符串中剥离所有不可打印字符的最快方法?
到目前为止,我已经尝试并测量了一个138字节、131个字符的字符串:
replaceAll()方法是 String 类中最慢的方法- 每秒517009个结果
- 预编译 Pattern,然后使用 Matcher 的
replaceAll()方法- 每秒637836个结果
- 使用 StringBuffer,逐一获取代码点并附加到 StringBuffer 中,使用
codepointAt()方法- 每秒711946个结果
- 使用 StringBuffer,逐一获取字符并附加到 StringBuffer 中,使用
charAt()方法- 每秒1052964个结果
- 预分配一个
char[]缓冲区,逐一获取字符并填充该缓冲区,然后将其转换回 String- 每秒2022653个结果
- 预分配 2 个
char[]缓冲区 - 旧的和新的,一次性使用getChars()方法获取现有字符串的所有字符,逐一迭代旧缓冲区并填充新缓冲区,然后将新缓冲区转换为 String - 我自己的最快版本- 每秒2502502个结果
- 使用 2 个
byte[]缓冲区进行相同的操作,但使用getBytes()方法,并将编码指定为 "utf-8"- 每秒857485个结果
- 使用 2 个
byte[]缓冲区进行相同的操作,但将编码指定为常量Charset.forName("utf-8")- 每秒791076个结果
- 使用 2 个
byte[]缓冲区进行相同的操作,但将编码指定为 1 字节本地编码(几乎是不明智的做法)- 每秒370164个结果
我最好的尝试如下:
char[] oldChars = new char[s.length()];
s.getChars(0, s.length(), oldChars, 0);
char[] newChars = new char[s.length()];
int newLen = 0;
for (int j = 0; j < s.length(); j++) {
char ch = oldChars[j];
if (ch >= ' ') {
newChars[newLen] = ch;
newLen++;
}
}
s = new String(newChars, 0, newLen);
有没有想法如何使它更快?
额外加分回答一个非常奇怪的问题:为什么直接使用“utf-8”字符集名称比使用预分配的静态常量Charset.forName("utf-8")性能更好?
更新
- ratchet freak的建议取得了令人印象深刻的3105590个结果/秒的性能,提高了24%!
- Ed Staub的建议又带来了进一步的改进——3471017个结果/秒,比之前最佳的结果提高了12%。
更新2
我尽力收集了所有提出的解决方案及其交叉变异,并将其发布为在github上提供的小型基准测试框架。目前它拥有17种算法。其中有一个是“特殊”的——Voo1算法(由SO用户Voo提供)采用复杂的反射技巧,从而实现了卓越的速度,但会破坏JVM字符串的状态,因此单独进行基准测试。
欢迎您查看并在您的计算机上运行它以确定结果。这是我在我的机器上得到的结果摘要。它的规格:
- Debian sid
- Linux 2.6.39-2-amd64 (x86_64)
- 已从软件包
sun-java6-jdk-6.24-1安装Java,JVM标识为- Java(TM) SE Runtime Environment (build 1.6.0_24-b07)
- Java HotSpot(TM) 64-Bit Server VM (build 19.1-b02, mixed mode)
不同的算法在给定不同的输入数据集时最终会产生不同的结果。我以三种模式运行了基准测试:
相同的单个字符串
此模式适用于由StringSource类提供的同一单个字符串作为常量。决斗是:
每秒操作数 │ 算法 ──────────┼────────────────────────────── 6,535,947 │ Voo1 ──────────┼────────────────────────────── 5,350,454 │ RatchetFreak2EdStaub1GreyCat1 5,249,343 │ EdStaub1 5,002,501 │ EdStaub1GreyCat1 4,859,086 │ ArrayOfCharFromStringCharAt 4,295,532 │ RatchetFreak1 4,045,307 │ ArrayOfCharFromArrayOfChar 2,790,178 │ RatchetFreak2EdStaub1GreyCat2 2,583,311 │ RatchetFreak2 1,274,859 │ StringBuilderChar 1,138,174 │ StringBuilderCodePoint 994,727 │ ArrayOfByteUTF8String 918,611 │ ArrayOfByteUTF8Const 756,086 │ MatcherReplace 598,945 │ StringReplaceAll 460,045 │ ArrayOfByteWindows1251
以图表形式呈现:
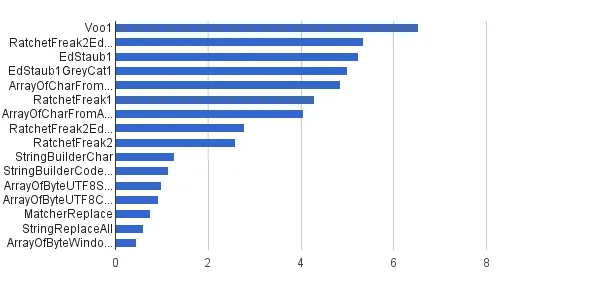
(来源: greycat.ru)
{kind=link}
多个字符串,100%的字符串包含控制字符
源字符串提供程序使用(0..127)字符集预先生成了大量随机字符串,因此几乎所有字符串都包含至少一个控制字符。算法以轮流方式从这个预生成的数组中接收字符串。
每秒操作数 │ 算法 ──────────┼────────────────────────────── 2 123 142 │ Voo1 ──────────┼────────────────────────────── 1 782 214 │ EdStaub1 1 776 199 │ EdStaub1GreyCat1 1 694 628 │ ArrayOfCharFromStringCharAt 1 481 481 │ ArrayOfCharFromArrayOfChar 1 460 067 │ RatchetFreak2EdStaub1GreyCat1 1 438 435 │ RatchetFreak2EdStaub1GreyCat2 1 366 494 │ RatchetFreak2 1 349 710 │ RatchetFreak1 893 176 │ ArrayOfByteUTF8String 817 127 │ ArrayOfByteUTF8Const 778 089 │ StringBuilderChar 734 754 │ StringBuilderCodePoint 377 829 │ ArrayOfByteWindows1251 224 140 │ MatcherReplace 211 104 │ StringReplaceAll
以图表形式呈现:
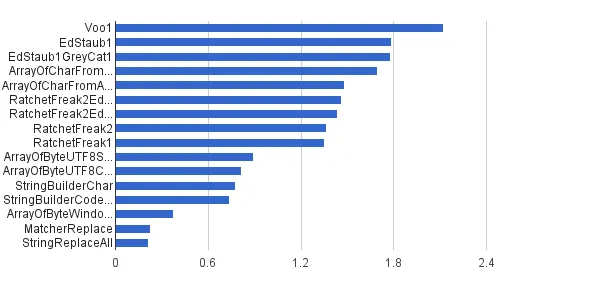
(来源: greycat.ru)
{kind=link}
多个字符串,1%的字符串包含控制字符
与之前相同,但只有1%的字符串是使用控制字符生成的 - 其他99%是使用[32..127]字符集生成的,因此它们根本不包含控制字符。这种合成负载最接近我所在地区此算法的真实应用。按图表形式呈现:
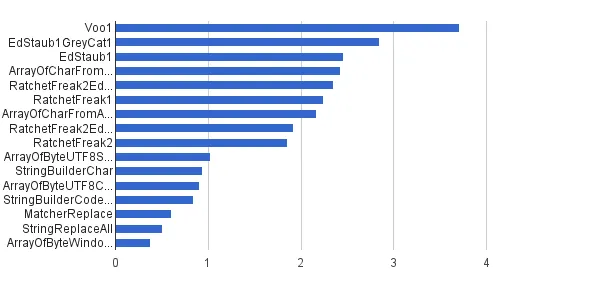
(来源:greycat.ru)
{kind=link}
对于我来说很难决定谁提供了最好的答案,但考虑到实际应用场景,Ed Staub提供/启发的解决方案是最好的,我想标记他的答案是公平的。感谢所有参与其中的人,你们的意见非常有帮助和宝贵。请随意在您的计算机上运行测试套件并提出更好的解决方案(任何工作JNI解决方案?)。
参考资料
- GitHub存储库 带有基准测试套件
StringBuilder是非同步的,所以它比StringBuffer略快。我提到这一点是因为你标记了这个为“微优化”。 - user177800s.length()从for循环中提取出来 :-) - home\t和\n。你字符集中127以上的许多字符是不可打印的。 - Peter Lawreys.length()作为字符串缓冲区的容量进行初始化? - ratchet freak