我有一个大型数据集,使用列表列进行组织(20Gb)。
1-除了使用Data.table可以提高两倍速度之外,还有其他技巧可以用于类似情况的优化吗?
2-除了saveRDS之外,是否有其他更快的文件库(例如vroom、fst和fwrite不支持listcols),可以支持listcolumns?
3-我尝试了dt[,.(test=tib_sort[tib_sort[, .I[.N]], stringi::stri_sub(dt$ch, length = 5)],by=id)]但是它会抛出一个错误的维数数量。是否有一种方法可以使用listcolumn并自动设置DT和键/索引来执行by操作?
library(dplyr)
library(purrr)
library(data.table)
library(tictoc)
Toy数据
set.seed(123)
tib <-
tibble(id = 1:20000) %>% mutate(k = map_int(id, ~ sample(c(10:30), 1)))
tib <-
tib %>% mutate(tib_df = map(k, ~ tibble(
ch = replicate(.x, paste0(
sample(letters[1:24],
size = sample(c(10:20), 1)),
collapse = ""
)),
num = sample(1:1e10, .x,replace = F)
)))
Dplyr
help <- function(df) {
df <- df %>% top_n(1, num) %>% select(ch)
stringi::stri_sub(df, length = 5)
}
tic("purrr")
tib <- tib %>% mutate(result = map_chr(tib_df, help))
toc(log = T, quiet = T)
Data.table
dt <- copy(tib)
setDT(dt)
tic("setDT w key")
dt[, tib_df := lapply(tib_df, setDT)]
dt[, tib_sort := lapply(tib_df, function(x)
setindex(x, "num"))]
toc(log = T, quiet = T)
tic("dt w key")
dt[, result_dt_key := sapply(tib_df, function(x) {
x[x[, .I[.N]], stringi::stri_sub(ch, length = 5)]
})]
toc(log=T, quiet = T)
计时
tic.log(format = T)
[[1]]
[1] "purrr: 25.499 sec elapsed"
[[2]]
[1] "setDT w key: 4.875 sec elapsed"
[[3]]
[1] "dt w key: 12.077 sec elapsed"
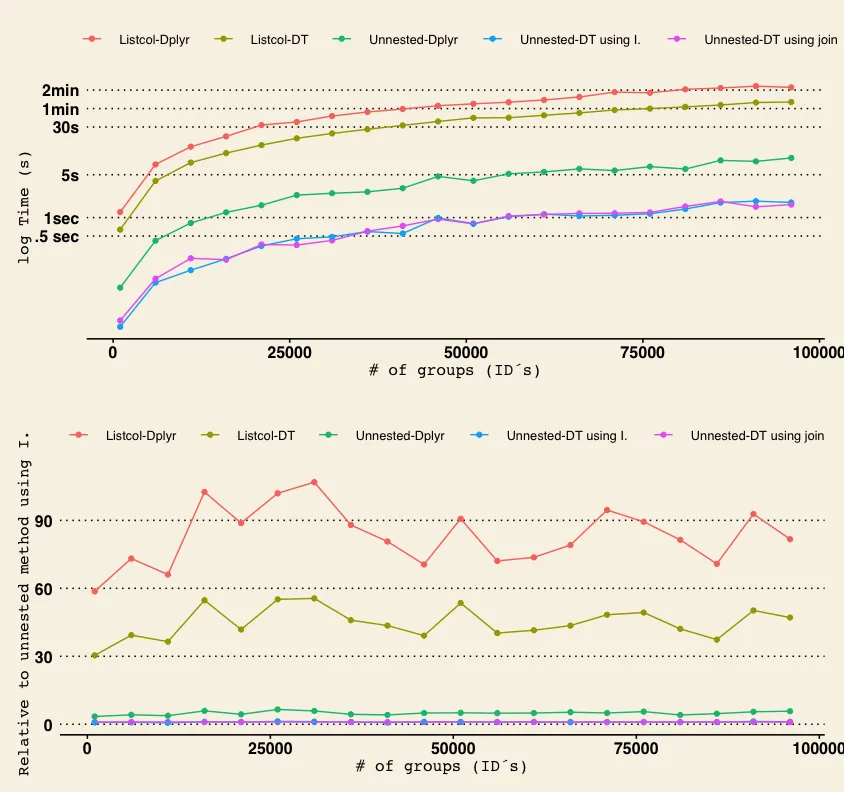
添加了dplyr和data.table中已解嵌套版本后的修改和更新
1 purrr: 25.824 sec elapsed
2 setDT wo key: 2.97 sec elapsed
3 dt wo key: 13.724 sec elapsed
4 setDT w key: 1.778 sec elapsed
5 dt w key: 11.489 sec elapsed
6 dplyr,unnest: 1.496 sec elapsed
7 dt,I,unnest: 0.329 sec elapsed
8 dt, join, unnest: 0.325 sec elapsed
tic("dt, join, unnest")
b <- unnest(tib)
setDT(b)
unnest.J <- b[b[, .(num=max(num)), by = 'id'], on=c('id','num')][,r2:=stringi::stri_sub(ch,length=5)][]
toc(log=T)
res <- list(unnest.J$r2,tib2$result2,dt$result_dt_key,dt$result_dt,tib$result)
sapply(res,identical,unnest.I$r2)
[1] TRUE TRUE TRUE TRUE TRUE
那么,我的结论是,虽然listcolumns作为数据结构在分析中看起来很诱人,但它们要慢得多slooower。