例如,我有一串大量的单词并想计算每个单词的出现次数。问题在于这些单词是倾斜的。这意味着某些单词的频率非常高,但大多数其他单词的频率很低。在Flink中,我们可以使用以下方法来解决此问题。首先,在流上执行shuffle grouping,在每个节点上以窗口时间本地计算单词计数,最后将计数更新为累积结果。
从我的另一个问题中,我知道Flink只支持键控流上的窗口,否则窗口操作将不会并行执行。
我的问题是,在Flink中是否有一种好的方法来解决这种偏斜数据的问题?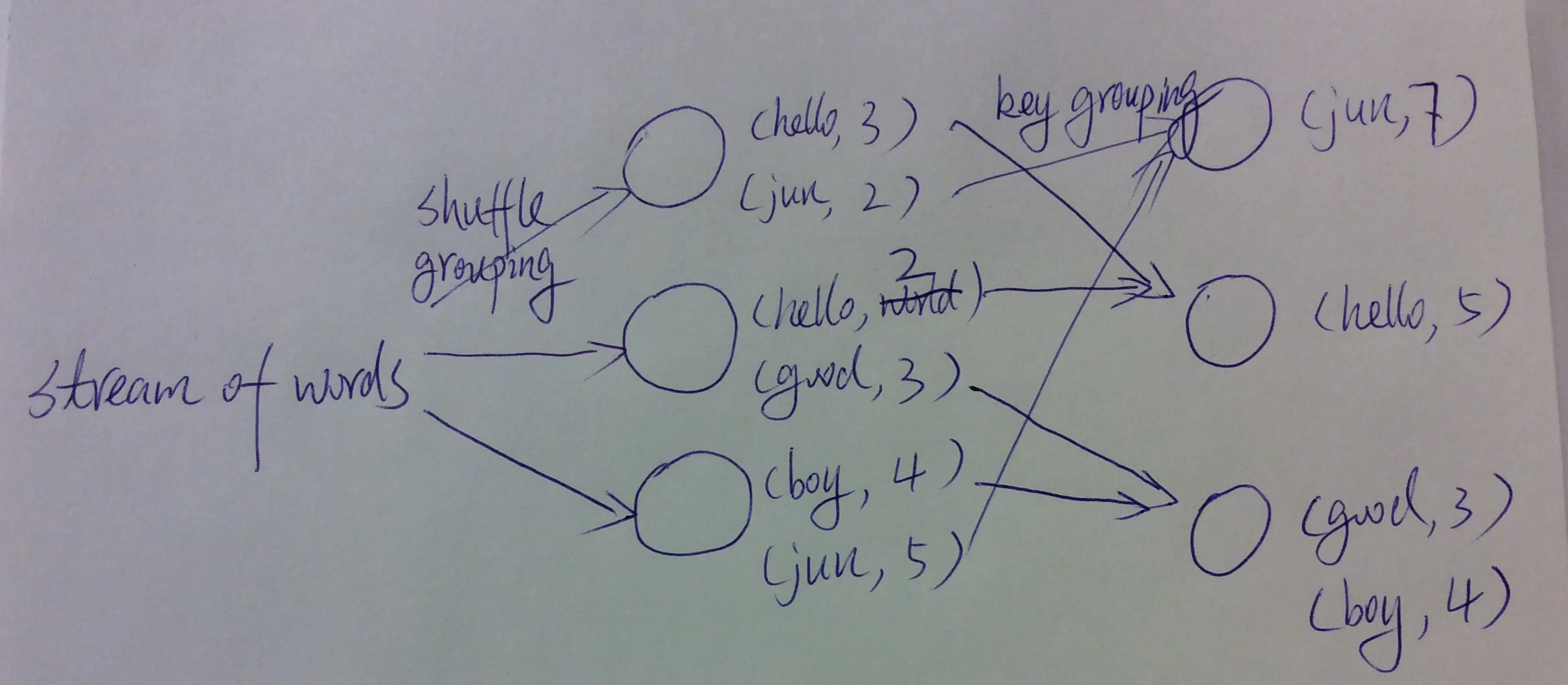
从我的另一个问题中,我知道Flink只支持键控流上的窗口,否则窗口操作将不会并行执行。
我的问题是,在Flink中是否有一种好的方法来解决这种偏斜数据的问题?