下面是我对这种情况的思考过程,
将有两种不同类型的查询。一种是结果没有被IndexPostion和/或IndexValue切片,第二种是结果被它们切片。
没有单个表设计可以在不进行任何权衡的情况下给我那个结果。权衡可能是存储、性能或查询复杂度。
下面的解决方案是“放弃存储”,但在访问此模式时要考虑性能和查询简单性。
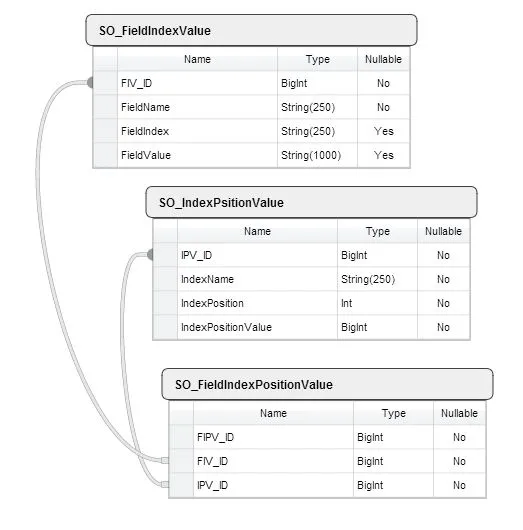
对于第一类型的查询,只使用“SO_FieldIndexValue”表。
但是,对于第二类型的查询,我们需要将其与其他两个表连接起来,在这里我们需要通过IndexPosition/IndexPositionValue过滤结果。
IF OBJECT_ID('SO_FieldIndexPositionValue') IS NOT NULL
DROP TABLE SO_FieldIndexPositionValue
IF OBJECT_ID('SO_FieldIndexValue') IS NOT NULL
DROP TABLE SO_FieldIndexValue
IF OBJECT_ID('SO_IndexPositionValue') IS NOT NULL
DROP TABLE SO_IndexPositionValue
CREATE TABLE SO_FieldIndexValue
(
FIV_ID BIGINT NOT NULL IDENTITY
CONSTRAINT XPK_SO_FieldIndexValue PRIMARY KEY NONCLUSTERED
,FieldName NVARCHAR(50)NOT NULL
,FieldIndex NVARCHAR(10) NOT NULL
,FieldValue NVARCHAR(500) NULL
)
CREATE UNIQUE CLUSTERED INDEX CIDX_SO_FieldIndexValue
ON SO_FieldIndexValue(FIV_ID ASC,FieldName ASC,FieldIndex ASC)
CREATE NONCLUSTERED INDEX NCIDX_SO_FieldIndexValue
ON SO_FieldIndexValue (FIV_ID,FieldName)
INCLUDE (FieldIndex,FieldValue)
CREATE TABLE SO_IndexPositionValue
(
IPV_ID BIGINT NOT NULL IDENTITY
CONSTRAINT XPK_SO_IndexPositionValue PRIMARY KEY NONCLUSTERED
,IndexName SYSNAME NOT NULL
,IndexPosition INT NOT NULL
,IndexPositionValue BIGINT NOT NULL
)
CREATE UNIQUE CLUSTERED INDEX CIDX_SO_IndexPositionValue
ON SO_IndexPositionValue(IPV_ID ASC,IndexPosition ASC, IndexPositionValue ASC)
CREATE TABLE SO_FieldIndexPositionValue
(
FIPV_ID BIGINT NOT NULL IDENTITY
CONSTRAINT XPK_SO_FieldIndexPositionValue PRIMARY KEY NONCLUSTERED
,FIV_ID BIGINT NOT NULL REFERENCES SO_FieldIndexValue (FIV_ID)
,IPV_ID BIGINT NOT NULL REFERENCES SO_IndexPositionValue (IPV_ID)
)
CREATE CLUSTERED INDEX CIDX_SO_FieldIndexPositionValue
ON SO_FieldIndexPositionValue(FIPV_ID ASC,FIV_ID ASC,IPV_ID ASC)
我提供了一个简单的SQL API,只是为了演示如何使用单个API轻松处理插入到此模式中的内容。
有很多机会可以使用此API进行玩耍,并根据需要进行自定义。例如,如果输入格式正确,则添加验证。
IF object_id('pr_FiledValueInsert','p') IS NOT NULL
DROP PROCEDURE pr_FiledValueInsert
GO
CREATE PROCEDURE pr_FiledValueInsert
(
@FieldIndexValue NVARCHAR(MAX)
,@FieldValue NVARCHAR(MAX)=NULL
)
AS
BEGIN
SET NOCOUNT ON
BEGIN TRY
BEGIN TRAN
DECLARE @OriginalFiledIndex NVARCHAR(MAX)=@FieldIndexValue
DECLARE @FieldName sysname=''
,@FIV_ID BIGINT
,@FieldIndex sysname
,@IndexName sysname
,@IndexPosition BIGINT
,@IndexPositionValue BIGINT
,@IPV_ID BIGINT
,@FIPV_ID BIGINT
,@CharIndex1 BIGINT
,@CharIndex2 BIGINT
,@StrLen BIGINT
,@StartPos BIGINT
,@EndPos BIGINT
SET @CharIndex1 = CHARINDEX('(',@OriginalFiledIndex)
SET @StrLen = LEN(@OriginalFiledIndex)
SET @CharIndex2 = CHARINDEX(')',@OriginalFiledIndex)
SET @FieldName = RTRIM(LTRIM(SUBSTRING(@OriginalFiledIndex,1,@CharIndex1-1)))
SET @FieldIndex = RTRIM(LTRIM(SUBSTRING(@OriginalFiledIndex,@CharIndex1+1,@StrLen-@CharIndex1-1)))
SELECT @FIV_ID = FIV_ID
FROM SO_FieldIndexValue
WHERE FieldName=@FieldName
AND FieldIndex=@FieldIndex
IF @FIV_ID IS NULL
BEGIN
INSERT INTO SO_FieldIndexValue ( FieldName,FieldIndex,FieldValue )
SELECT @FieldName,@FieldIndex,@FieldValue
SELECT @FIV_ID = SCOPE_IDENTITY()
END
ELSE
BEGIN
RAISERROR('Filed and Index Combination already Exists',16,1)
END
SELECT @StartPos=CHARINDEX('(',@OriginalFiledIndex,1)+1
SELECT @EndPos = CASE WHEN CHARINDEX(',',@OriginalFiledIndex,@StartPos)<>0
THEN CHARINDEX(',',@OriginalFiledIndex,@StartPos)- @StartPos
ELSE CHARINDEX(')',@OriginalFiledIndex,@StartPos) - @StartPos
END
SELECT @IndexPosition = 1
SELECT @IndexPositionValue = SUBSTRING(@OriginalFiledIndex,@StartPos,@EndPos)
SELECT @IndexName = 'Index'+CAST(@IndexPosition AS Sysname)
SELECT @IPV_ID = IPV_ID
FROM SO_IndexPositionValue
WHERE IndexPosition=@IndexPosition
AND IndexPositionValue = @IndexPositionValue
IF @IPV_ID IS NULL
BEGIN
INSERT SO_IndexPositionValue
( IndexName ,
IndexPosition ,
IndexPositionValue
)
SELECT @IndexName,@IndexPosition,@IndexPositionValue
SET @IPV_ID = SCOPE_IDENTITY()
END
IF NOT EXISTS(
SELECT TOP(1) 1
FROM SO_FieldIndexPositionValue
WHERE FIV_ID = @FIV_ID
AND IPV_ID = @IPV_ID
)
BEGIN
INSERT SO_FieldIndexPositionValue( FIV_ID, IPV_ID )
SELECT @FIV_ID,@IPV_ID
END
WHILE @StrLen>@StartPos+@EndPos
BEGIN
SET @StartPos = @StartPos+@EndPos+1
SET @EndPos = CASE WHEN CHARINDEX(',',@OriginalFiledIndex,@StartPos)<>0
THEN CHARINDEX(',',@OriginalFiledIndex,@StartPos)- @StartPos
ELSE CHARINDEX(')',@OriginalFiledIndex,@StartPos) - @StartPos
END
SELECT @IndexPosition = @IndexPosition+1
SELECT @IndexPositionValue = SUBSTRING(@OriginalFiledIndex,@StartPos,@EndPos)
SELECT @IndexName = 'Index'+CAST(@IndexPosition AS Sysname)
SET @IPV_ID = NULL
SELECT @IPV_ID = IPV_ID
FROM SO_IndexPositionValue
WHERE IndexPosition=@IndexPosition
AND IndexPositionValue = @IndexPositionValue
IF @IPV_ID IS NULL
BEGIN
INSERT SO_IndexPositionValue
( IndexName ,
IndexPosition ,
IndexPositionValue
)
SELECT @IndexName,@IndexPosition,@IndexPositionValue
SET @IPV_ID = SCOPE_IDENTITY()
END
IF NOT EXISTS(
SELECT TOP(1) 1
FROM SO_FieldIndexPositionValue
WHERE FIV_ID = @FIV_ID
AND IPV_ID = @IPV_ID
)
BEGIN
INSERT SO_FieldIndexPositionValue( FIV_ID, IPV_ID )
SELECT @FIV_ID,@IPV_ID
END
END
COMMIT TRAN
END TRY
BEGIN CATCH
ROLLBACK TRAN
SELECT ERROR_MESSAGE()
END CATCH
SET NOCOUNT OFF
END
GO
现在是样本输入数据
EXECUTE pr_FiledValueInsert 'FIELD1(0,1,0)',101
EXECUTE pr_FiledValueInsert 'FIELD1(0,1,2)','ABCDEF'
EXECUTE pr_FiledValueInsert 'FIELD1(1,0,1)','hello1'
EXECUTE pr_FiledValueInsert 'FIELD2(1,0,0)',102
EXECUTE pr_FiledValueInsert 'FIELD2(1,1,0)','hey2'
EXECUTE pr_FiledValueInsert 'FIELD2(1,0,1)','hello2'
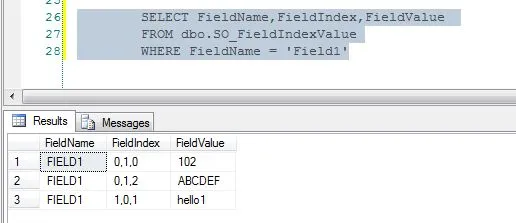
示例查询1
SELECT FieldName,FieldIndex,FieldValue
FROM dbo.SO_FieldIndexValue
WHERE FieldName = 'Field1'
样例结果1
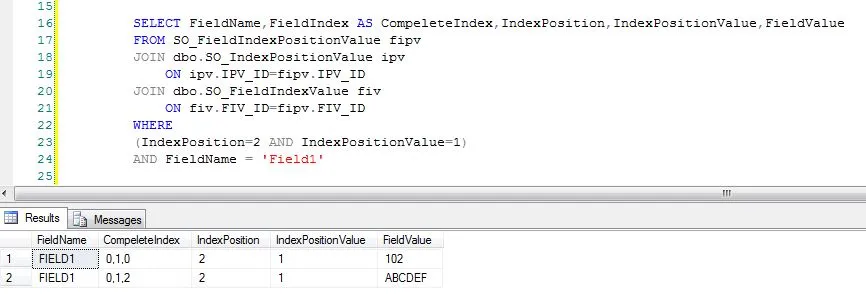
样例查询2
SELECT FieldName,FieldIndex AS CompeleteIndex,IndexPosition,IndexPositionValue,FieldValue
FROM SO_FieldIndexPositionValue fipv
JOIN dbo.SO_IndexPositionValue ipv
ON ipv.IPV_ID=fipv.IPV_ID
JOIN dbo.SO_FieldIndexValue fiv
ON fiv.FIV_ID=fipv.FIV_ID
WHERE
(IndexPosition=2 AND IndexPositionValue=1)
AND FieldName = 'Field1'
示例结果2
该示例展示了一个名为“示例结果2”的图像。