我正在设计一个服务器守护程序,用于处理大量并发请求并进行异步处理。我意识到这样的项目规模非常庞大,但我很认真,并在进一步操作之前尝试制定清晰的设计和计划。
以下是我的目标列表:
- 可扩展性 - 必须能够将架构并行化到多个处理器甚至多个服务器上。 - 能够处理大量并发连接。 - 如果单个请求需要长时间处理,则不得引起阻塞问题。 - 请求到响应的反应时间必须最小化。 - 基于.NET框架构建(将使用C#编写)。
我提出的架构和流程相当复杂,因此这里是我最初设计的图表:
我正在寻找的建议涉及以下几个方面:
- 我是否忽略了任何此架构的主要缺陷? - 是否有任何性能方面需要考虑更改的内容? - 对于请求,TCP或UDP更合适?拥有TCP提供的“交付证明”非常有用,但UDP的轻量级特性也很吸引人。 - 在Windows服务器上处理100k+同时连接时,是否需要考虑特殊因素?我知道Linux的TCP堆栈处理得很好,但对于Windows,我不太确定。 - 是否有其他问题需要问?我是否忘记考虑任何事情?
我知道这篇文章很长,而且可能要求也比较多,所以感谢您的时间。
以下是我的目标列表:
- 可扩展性 - 必须能够将架构并行化到多个处理器甚至多个服务器上。 - 能够处理大量并发连接。 - 如果单个请求需要长时间处理,则不得引起阻塞问题。 - 请求到响应的反应时间必须最小化。 - 基于.NET框架构建(将使用C#编写)。
我提出的架构和流程相当复杂,因此这里是我最初设计的图表:
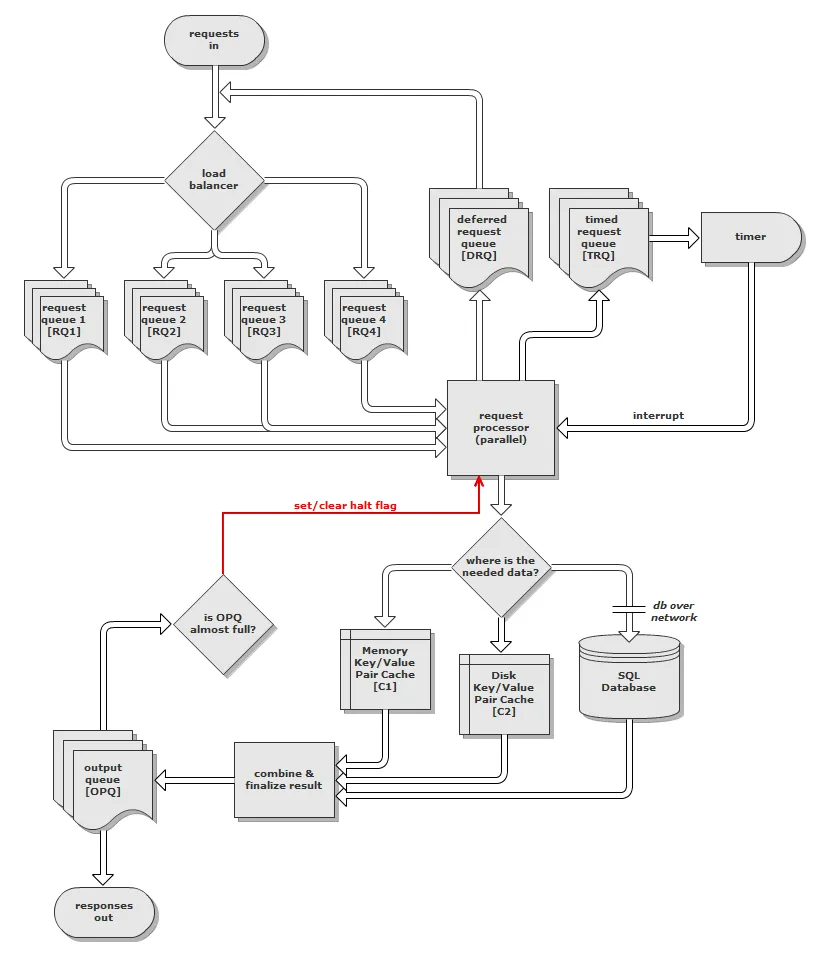
(如果图片调整不好,在这里看)
{kind=link}
该想法是通过网络接收请求(尚未决定TCP或UDP哪个更好),并立即将请求传递给高速负载均衡器。然后,负载均衡器使用加权随机数生成器选择要放置请求的请求队列(RQ)。权重来自每个队列的大小。之所以使用加权RNG而不仅仅将请求放入最不繁忙的队列中,是因为它可以防止空但被阻塞的队列(由于挂起的请求)锁定整个服务器。如果所有RQ都超过一定大小,则负载平衡器会丢弃请求,并将“服务器过于繁忙”的响应放入输出队列(OPQ)- 此部分未在图表中显示。
每个队列对应于一个线程,其亲和性设置为服务器上的一个CPU核心。这些线程是并行请求处理器的一部分,从每个队列消耗请求。请求分为三种类型之一:
立即 - 立即请求是按照名称所示,立即处理的。
可延迟 - 可延迟请求被认为是低优先级。在低负载期间它们会立即处理,或者如果负载高则放入延迟请求队列(DRQ)中。负载均衡器从DRQ中获取这些延迟请求,将它们标记为立即,并将它们放回适当的RQ中。
定时 - 定时请求与目标时间戳一起放入定时请求队列(TRQ)中。这些请求通常是作为另一个请求的结果生成的,而不是由客户端显式发送的。当请求时间戳超过时,下一个可用的请求处理线程会消耗并处理它。
处理请求时,数据可以从内存中的键/值对缓存、键/值对缓存或磁盘上获取,也可以从专用的SQL数据库服务器获取。缓存的值将是BSON,索引将是字符串。我考虑使用 Dictionary<T1,T2> 在内存中实现这个功能,并使用B树(或类似的东西)来进行磁盘缓存。
我正在寻找的建议涉及以下几个方面:
- 我是否忽略了任何此架构的主要缺陷? - 是否有任何性能方面需要考虑更改的内容? - 对于请求,TCP或UDP更合适?拥有TCP提供的“交付证明”非常有用,但UDP的轻量级特性也很吸引人。 - 在Windows服务器上处理100k+同时连接时,是否需要考虑特殊因素?我知道Linux的TCP堆栈处理得很好,但对于Windows,我不太确定。 - 是否有其他问题需要问?我是否忘记考虑任何事情?
我知道这篇文章很长,而且可能要求也比较多,所以感谢您的时间。
这里是更新后的图示链接在此。
{kind=link}