我正在使用Google Cloud Composer上的Airflow(版本:composer-1.10.2-airflow-1.10.6)。
我发现当任务过多时调度程序不会安排任务(请参阅下面的甘特图)
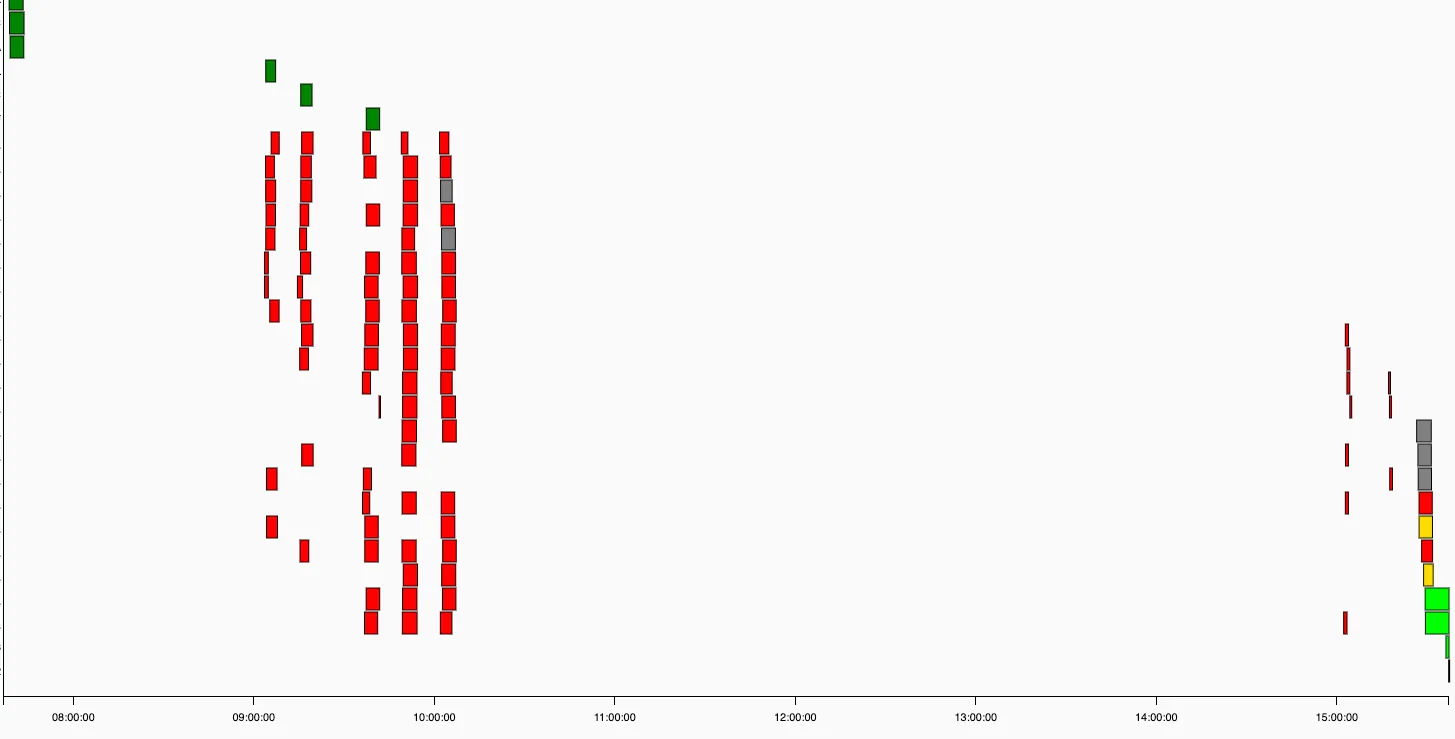 (不要注意颜色,红色任务是“createTable Operators”,如果表已经存在,则会失败5次,然后才运行DAG的下一部分(重要的一部分))
(不要注意颜色,红色任务是“createTable Operators”,如果表已经存在,则会失败5次,然后才运行DAG的下一部分(重要的一部分))
有几个小时的间隔在任务之间!(例如,早上10点到下午3点之间有5个小时没有任何任务执行)
通常情况下,每个DAG大约有100-200个任务,使用40个左右的DAG正常工作(有时会更多)。但最近我添加了2个有很多任务(每个约5000个)的DAG,并且调度程序非常慢或不安排任务。在屏幕截图中,我于下午3点暂停了这2个带有大量任务的DAG,然后调度程序又恢复正常工作了。
您有任何解决方案吗?
Airflow旨在处理“无限量”的任务。
以下是我的环境信息:
- 版本:composer-1.10.2-airflow-1.10.6
- 集群规模:6(12个vCPU,96GB内存)
以下是Airflow配置的一些信息:
╔════════════════════════════════╦═══════╗
║ Airflow parameter ║ value ║
╠════════════════════════════════╬═══════╣
║ -(celery)- ║ ║
║ worker_concurrency ║ 32 ║
║ -(webserver)- ║ ║
║ default_dag_run_display_number ║ 2 ║
║ workers ║ 2 ║
║ worker_refresh_interval ║ 60 ║
║ -(core)- ║ ║
║ max_active_runs_per_dag ║ 1 ║
║ dagbag_import_timeout ║ 600 ║
║ parallelism ║ 200 ║
║ min_file_process_interval ║ 60 ║
║ -(scheduler)- ║ ║
║ processor_poll_interval ║ 5 ║
║ max_threads ║ 2 ║
╚════════════════════════════════╩═══════╝
感谢您的帮助。
编辑:
我的26个DAG由一个.py文件创建,通过解析一个大型JSON变量创建所有DAG和任务。
也许问题就出在这里,因为今天Airflow正在调度除我描述的26个DAG(尤其是那两个大型DAG)之外的其他DAG中的任务。 更具体地说,Airflow有时会安排我的26个DAG的任务,但它更容易和更频繁地安排其他DAG的任务。