我有几千个PDF文件,包含从数字化纸质表单中提取出的黑白图像(1位)。我正在尝试OCR一些字段,但有时书写太模糊:

我刚刚学习了形态学变换。它们真的很酷!我感觉自己在滥用它们(就像我学Perl时滥用正则表达式一样)。
我只对日期07-06-2017感兴趣:
im = cv2.blur(im, (5, 5))
plt.imshow(im, 'gray')

ret, thresh = cv2.threshold(im, 250, 255, 0)
plt.imshow(~thresh, 'gray')

填写此表格的人似乎对网格不太在意,因此我试图将其去掉。我可以使用此转换来分离出水平线:
horizontal = cv2.morphologyEx(
~thresh,
cv2.MORPH_OPEN,
cv2.getStructuringElement(cv2.MORPH_RECT, (100, 1)),
)
plt.imshow(horizontal, 'gray')
我也可以获取垂直线:

plt.imshow(horizontal ^ ~thresh, 'gray')
ret, thresh2 = cv2.threshold(roi, 127, 255, 0)
vertical = cv2.morphologyEx(
~thresh2,
cv2.MORPH_OPEN,
cv2.getStructuringElement(cv2.MORPH_RECT, (2, 15)),
iterations=2
)
vertical = cv2.morphologyEx(
~vertical,
cv2.MORPH_ERODE,
cv2.getStructuringElement(cv2.MORPH_RECT, (9, 9))
)
horizontal = cv2.morphologyEx(
~horizontal,
cv2.MORPH_ERODE,
cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7))
)
plt.imshow(vertical & horizontal, 'gray')

plt.imshow(horizontal & vertical & ~thresh, 'gray')
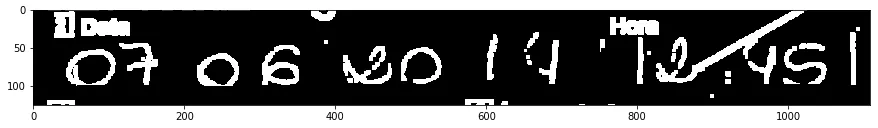
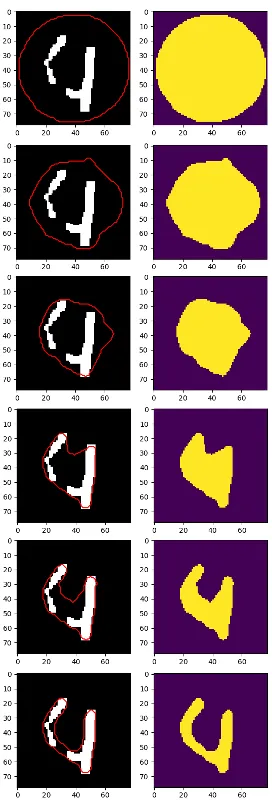
我最好的结果是这个,但数字4仍然分成了两部分:
plt.imshow(cv2.morphologyEx(im2, cv2.MORPH_CLOSE,
cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))), 'gray')
可能此时最好使用cv2.findContours和一些启发式方法来定位每个数字,但我在思考:
- 我应该放弃并要求所有文档重新以灰度扫描吗?
- 是否有更好的方法来隔离和定位模糊的数字?
- 您知道任何形态学变换可以合并“4”这样的情况吗?
[更新]
重新扫描文档是否太过苛刻?如果没有太大的麻烦,我认为获取更高质量的输入比训练和尝试改进模型以承受嘈杂和非典型数据更好
背景信息:我是巴西公共机构的一个无名小卒。 ICR解决方案的价格从6位数开始,因此没有人相信一个人能在内部编写ICR解决方案。 我太天真了,以至于相信我可以证明他们是错误的。 这些PDF文件存放在FTP服务器上(约10万个文件),仅为了摆脱死树版本而进行了扫描。 可能我可以获取原始表格并自己扫描,但我必须要求一些官方支持-由于这是公共部门,因此我希望尽可能地保持这个项目的低调。 现在我有50%的错误率,但如果这种方法行不通,那么改进它就没有意义。

pytesseract来获取打印表格的编号。我已经成功地将70,000张图像与由专业人类打字员输入的数据库中相应的记录进行了链接。这已经很有用了,因为我发现了许多应该在数据库中但不在其中的文件。从政治上讲,这是一个冒险:如果我编写了一个揭露他们失误的系统,我会招致一些敌人,所以我希望展示其他东西。 - Paulo Scardine