我有一个文件1.txt
$ cat 1.txt
page1
рage1
但是:
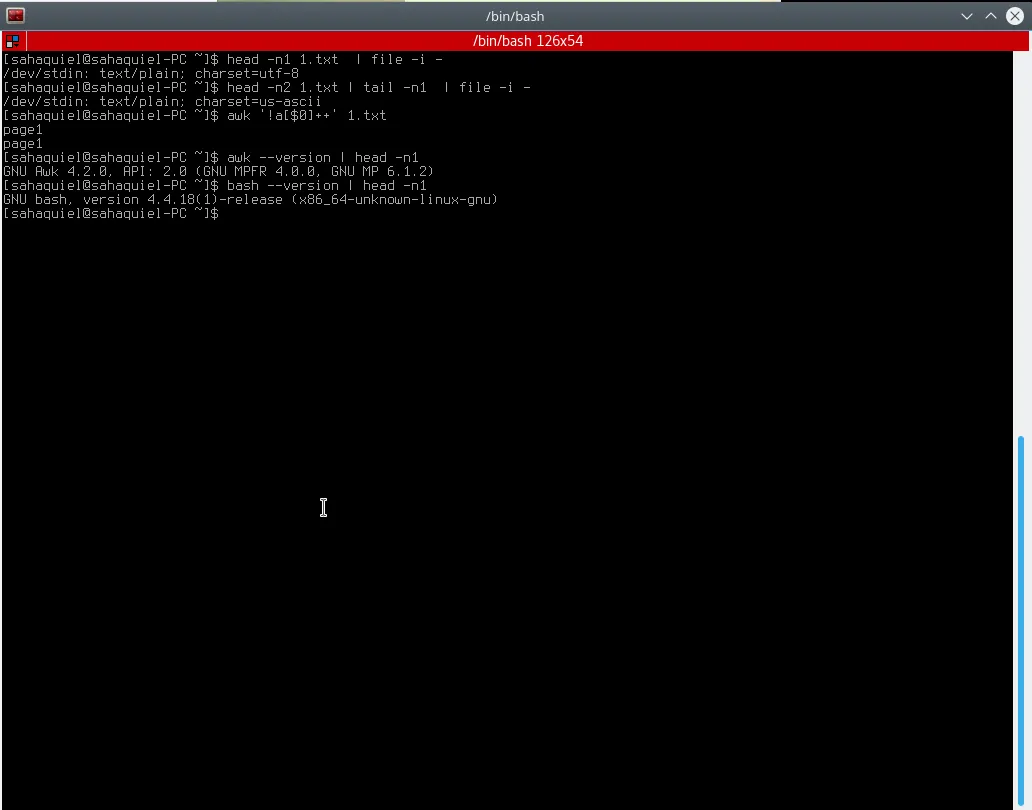
$ head -n1 1.txt | file -i -
/dev/stdin: text/plain; charset=us-ascii
$ head -n2 1.txt | tail -n1 | file -i -
/dev/stdin: text/plain; charset=utf-8
字符串有不同的字符集。因此,我无法用我知道的方法获得唯一的字符串:
$ cat 1.txt | sort | uniq -c | sort -rn
1 рage1
1 page1
那么,你能帮我找到在我的情况下如何获取唯一字符串的方法吗? 附注:请优先使用Linux命令行/ bash / awk解决方案。 但是如果您有另一种编程语言的解决方案,我也很乐意接受。
更新。 awk '!a[$0]++' Input_file 不起作用,图片:
M-QM-^@age1$ page1$。 - Viktor Khilinр,而不是英语中的p。问题太蠢了,谢谢!附言:你能告诉我,你从哪里得到这个信息的吗?"U+0440 р d1 80 CYRILLIC SMALL LETTER ER"- Viktor Khilin