我已经创建了一个批处理脚本,用于将 SQL 文件从文件夹复制到一个大型 SQL 脚本中。问题是当我运行这个 SQL 脚本时,出现错误:
Incorrect syntax near ''
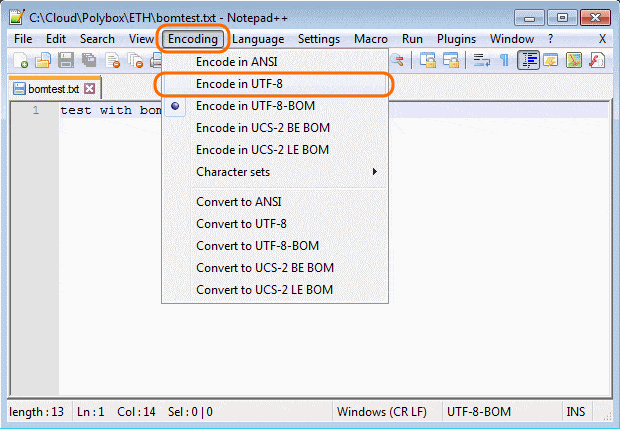
我将这个 SQL 脚本复制到 Notepad++ 中,并将编码设置为 ANSI。我看到发生错误的地方有一个符号(BOM)。
是否有任何方法可以在我的批处理脚本中自动删除它?我不想每次运行此任务时都手动移除它。
下面是我目前的批处理脚本:
@echo off
set "path2work=C:\StoredProcedures"
cd /d "%path2work%"
echo. > C:\FinalScript\AllScripts.sql
for %%a in (*.sql) do (
echo. >>"C:\FinalScript\AllScripts.sql"
echo GO >>"C:\FinalScript\AllScripts.sql"
type "%%a">>"C:\FinalScript\AllScripts.sql"
echo. >>"C:\FinalScript\AllScripts.sql"
)