我有以下问题。我想要计算小于或等于零的值的出现次数。例如,在以下数据中,我有3个出现次数:1(0,0,0),2(-1,-2),3(0,0)。在R中是否有内置函数来计算连续出现的次数。
a <- c(2,4,5,3,2,4,7,0,0,0,4,3,2,-1,-2,3,2,0,0,4)
我有以下问题。我想要计算小于或等于零的值的出现次数。例如,在以下数据中,我有3个出现次数:1(0,0,0),2(-1,-2),3(0,0)。在R中是否有内置函数来计算连续出现的次数。
a <- c(2,4,5,3,2,4,7,0,0,0,4,3,2,-1,-2,3,2,0,0,4)
sum(rle(a <= 0)$values)
这将会得到:
[1] 3
这是如何工作的:
rle function you create a runlength-encoding of a <= 0.The output of rle(a <= 0) is:
Run Length Encoding
lengths: int [1:7] 7 3 3 2 2 2 1
values : logi [1:7] FALSE TRUE FALSE TRUE FALSE TRUE ...
Now you just have to sum the values part of the rle-object:
> sum(rle(a <= 0)$values)
[1] 3
rl <- rle(a <= 0); sum(rl$lengths[rl$values]) 这样的内容吗? - Jaaprle :> sum(rle(a<=0)$values)
[1] 3
解释:
rle 将向量分成大于0或小于等于0的运行。 $values 取决于相应的运行是否满足谓词 (a <= 0) 或其否定,它们是 true 或 false。您需要与值 TRUE 对应的运行,函数 sum 强制将这些 TRUE 转换为 1。
使用 rle 的答案是好的,但这里有另一种方法:
b <- a <= 0
sum(b) - sum(b[which(b) - 1])
这个功能会计算非正元素的数量,并减去前面有多少个非正元素(因此只有每个非正数运行的开头最终会产生贡献)。
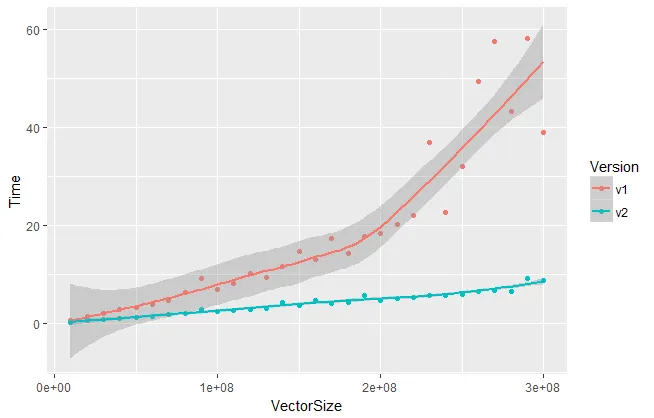
我进行了快速测试,发现对于大向量(1000万至3亿个元素),它的运行速度比其他方法快几倍。
v1 <- function(a) sum(rle(a<=0)$values)
v2 <- function(a) {
b <- a <= 0
sum(b) - sum(b[which(b) - 1])
}
v1.time <- NULL
v2.time <- NULL
sizes <- 1:30 * 1E7
for (s in sizes) {
x <- sample(-100:100, s, replace = TRUE)
v1.time <- c(v1.time, system.time(
v1.result <- v1(x)
)[['elapsed']])
v2.time <- c(v2.time, system.time(
v2.result <- v2(x)
)[['elapsed']])
print(c(v1.result, v2.result)) # Show that they agree
print(v1.time)
print(v2.time)
}
library(tidyverse)
data.frame(VectorSize = sizes,
v1 = v1.time,
v2 = v2.time) %>%
gather('Version', 'Time', -VectorSize) %>%
ggplot(aes(x = VectorSize, y = Time, color = Version)) + geom_point() + geom_smooth()
这里有另一种选项(不重复相同的东西),使用 rleid
library(data.table)
uniqueN(rleid(a<=0)[a<=0])
#[1] 3
rleid 给出逻辑向量 (a <=0) 的运行长度 ID,使用逻辑向量 ([a<=0]) 子集化 ID,并使用 uniqueN 找到唯一 ID 的 length。
sum(diff(a <=0)==1)
#[1] 3
rleid 呢 ;-) - Jaapsum(diff(a <= 0) == 1)将无法给出正确的输出。 - Jaapset.seed(3)
b<-c(4,6,4,2,3)
run<- replicate(2,{
a <- runif(5,3,5)
dif <- a - b
return(dif)
})
run
[,1] [,2]
[1,] -0.6639169 0.2087881
[2,] -1.3849672 -2.7507331
[3,] -0.2301153 -0.4107982
[4,] 1.6554686 2.1552198
[5,] 1.2042013 1.2619585
当我尝试时
sum(rle(run<=0)$values)
我得到了
Error in rle(run <= 0) : 'x' must be a vector of an atomic type
但它可以与之配合工作
uniqueN(rleid(run<=0)[run<=0])