考虑以下数据框:
df <- data.frame(replicate(5,sample(1:10,10,rep=TRUE)))
# X1 X2 X3 X4 X5
#1 7 9 8 4 10
#2 2 4 9 4 9
#3 2 7 8 8 6
#4 8 9 6 6 4
#5 5 2 1 4 6
#6 8 2 2 1 7
#7 3 8 6 1 6
#8 3 8 5 9 8
#9 6 2 3 10 7
#10 2 7 4 2 9
使用dplyr,如何在不显式命名列的情况下对每一列进行过滤,并筛选出大于2的所有值。
我需要类似于假设的filter_each(funs(. >= 2))的东西。
目前我正在执行:
```R filter_all(my_data, all_vars(.>=2)) ```
df %>% filter(X1 >= 2, X2 >= 2, X3 >= 2, X4 >= 2, X5 >= 2)
这相当于:
df %>% filter(!rowSums(. < 2))
注意:假设我只想筛选前4列,我会执行以下操作:
df %>% filter(X1 >= 2, X2 >= 2, X3 >= 2, X4 >= 2)
df %>% filter(!rowSums(.[-5] < 2))
是否有更高效的替代方案?
编辑:子问题
如何指定列名并模拟假设的filter_each(funs(. >= 2), -X5)?
基准测试子问题
由于我必须在大型数据集上运行此操作,因此我对建议进行了基准测试。
df <- data.frame(replicate(5,sample(1:10,10e6,rep=TRUE)))
mbm <- microbenchmark(
Marat = df %>% filter(!rowSums(.[,!colnames(.) %in% "X5", drop = FALSE] < 2)),
Richard = filter_(df, .dots = lapply(names(df)[names(df) != "X5"], function(x, y) { call(">=", as.name(x), y) }, 2)),
Docendo = df %>% slice(which(!rowSums(select(., -matches("X5")) < 2L))),
times = 50
)
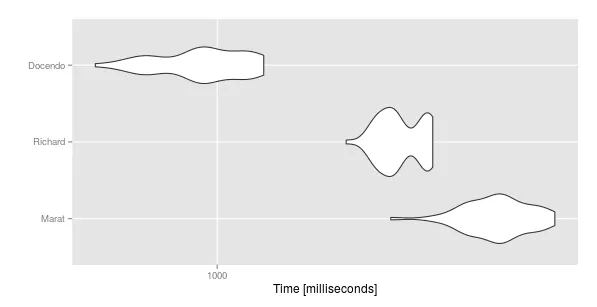
这里是结果:
#Unit: milliseconds
# expr min lq mean median uq max neval
# Marat 1209.1235 1320.3233 1358.7994 1362.0590 1390.342 1448.458 50
# Richard 1151.7691 1196.3060 1222.9900 1216.3936 1256.191 1266.669 50
# Docendo 874.0247 933.1399 983.5435 985.3697 1026.901 1053.407 50


df %>% filter(!rowSums(. < 2))做得很好。 - Marat Talipovdf%>% filter(!rowSums(.[,!colnames(.)%in%'X5',drop = F] <2))。 - Marat TalipovrowSums()在我看来很好! - Gabriel L'Heureux