我有一个数据框,长这样:
w<-read.table(header=TRUE,text="
start.date end.date
2006-06-26 2006-07-24
2006-07-19 2006-08-16
2007-06-09 2007-07-07
2007-06-24 2007-07-22
2007-07-03 2007-07-31
2007-08-04 2007-09-01
2007-08-07 2007-09-04
2007-09-05 2007-10-03
2007-09-14 2007-10-12
2007-10-19 2007-11-16
2007-11-17 2007-12-15
2008-06-18 2008-07-16
2008-06-28 2008-07-26
2008-07-11 2008-08-08
2008-07-23 2008-08-20")
我想获取一个输出,将重叠的开始日期和结束日期合并成一个日期范围。对于这个示例集,我希望得到:
w<-read.table(header=TRUE,text="
start.date end.date
2006-06-26 2006-08-16
2007-06-09 2007-07-31
2007-08-04 2007-09-04
2007-09-05 2007-10-12
2007-10-19 2007-11-16
2007-11-17 2007-12-15
2008-06-18 2008-08-20")
这个问题类似于R中的日期汇总,但我不需要对我的数据进行任何分组,因此那里提供的答案很困惑。
另外,对于我的数据框中的某些部分,下面针对我的问题提出的代码无法工作:
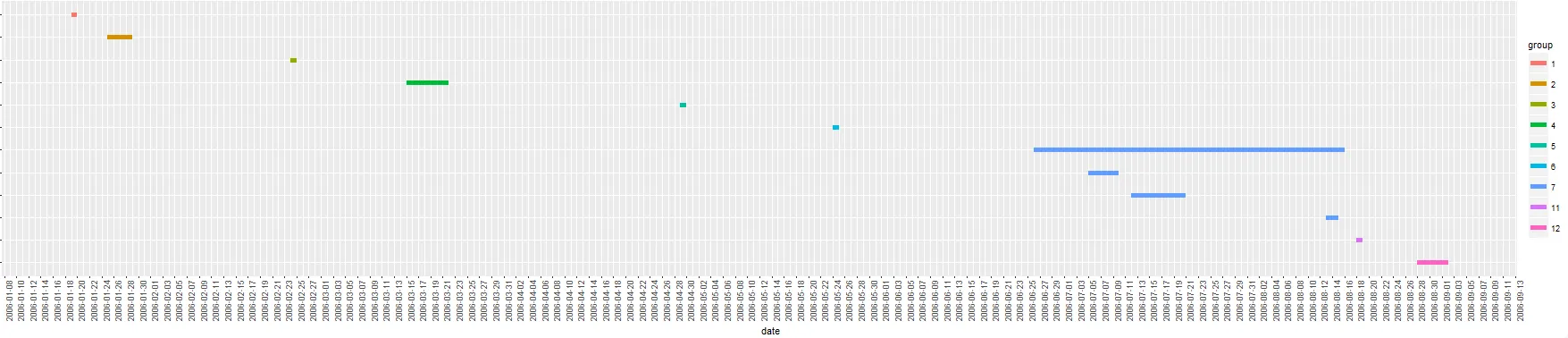
x<-read.table(header=TRUE,text="start.date end.date
2006-01-19 2006-01-20
2006-01-25 2006-01-29
2006-02-24 2006-02-25
2006-03-15 2006-03-22
2006-04-29 2006-04-30
2006-05-24 2006-05-25
2006-06-26 2006-08-16
2006-07-05 2006-07-10
2006-07-12 2006-07-21
2006-08-13 2006-08-15
2006-08-18 2006-08-19
2006-08-28 2006-09-02")
我感到困惑,为什么它不能正常工作?
library(dplyr); w %>% mutate(gr = cumsum(start.date-lag(end.date, default=1)>=0 )) %>% group_by(gr) %>% summarise(start.date = min(start.date), end.date = max(end.date))这段代码使用了dplyr包,并对数据框w进行了处理。它基于start.date和end.date列的值,将数据分成多个组,并计算出每个组的起始日期和结束日期。其中,gr变量是通过cumsum函数和逻辑运算符生成的,用于标记组的变化点。最后,使用group_by和summarise函数生成摘要信息。 - Khashaa