我今天来这里是为了检查现有技术的状态。
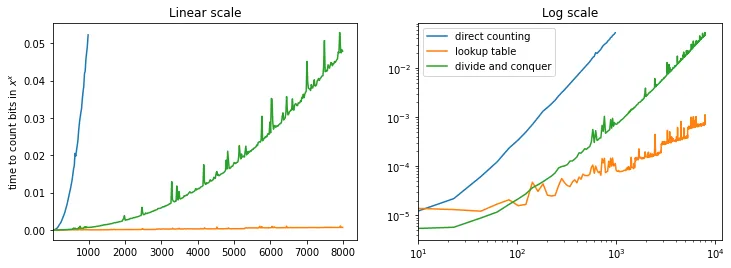
这是一个时常出现的话题,现代CPU有人口统计算法。这对于在某些通信应用程序中计算 Bit Error Rate 很有用。这是汉明重量,与 Hamming Distance 相关,Scipy 有一个 实现,但它使用数组而不是数字的二进制表示进行计算。对于固定大小的计算,例如 numpy 数组,我知道的最快方法是 此回答中的方法,但是所述方法,我将其称为分而治之的方法。在一般情况下,分而治之的复杂度为 O(log(n)) 而不是 O(n)。对于大多数情况,接受的答案非常好,甚至在诸如 C 这样的语言中更好,您可以简单地取((*char)bits)[i],而无需移动数字。
这里我提供了一个通用的分治算法实现,其中掩码是根据输入数字的大小动态计算的。
def dq_number_of_ones(n):
nb = 1
while n >> nb:
nb *= 2
t = (1 << nb) - 1
masks = []
while nb > 1:
nb //= 2
t ^= t >> nb
masks.append(t)
t = n
s = 1
for tm in masks[::-1]:
tm = masks.pop()
t = ((tm & t) >> s) + ((tm >> s) & t)
s *= 2
return t
为了完整性,这里展示原帖的方法和被接受的查找表方法
def number_of_ones(n):
c = 0
while n:
c += n%2
n //= 2
return c
lookup_table = [number_of_ones(i) for i in range(256)]
def lt_number_of_ones(n):
sum = 0
while n != 0:
sum += lookup_table[n & 0xff]
n >>= 8
return sum
这是两者的实际比较
import time
import matplotlib.pyplot as plt
x = []
t1 = []
t2 = []
t3 = []
for i in range(3,8000,20):
y = i**i
if i < 1000:
time.sleep(0.0001)
t0 = time.time()
w1 = number_of_ones(y)
t1.append(time.time() - t0)
else:
t1.append(np.nan)
time.sleep(0.0001)
t0 = time.time()
w2 = dq_number_of_ones(y)
t2.append(time.time() - t0)
time.sleep(0.0001)
t0 = time.time()
_ = lt_number_of_ones(y)
t3.append(time.time() - t0)
time.sleep(0.0001)
x.append(i)
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.plot(x, t1)
plt.plot(x, t2)
plt.plot(x, t3)
plt.xlim([10,None])
plt.title('Linear scale')
plt.ylabel('time to count bits in $x^x$')
plt.subplot(122)
plt.loglog(x, t1)
plt.loglog(x, t2)
plt.loglog(x, t3)
plt.xlim([10,None])
plt.title('Log scale')
plt.legend(['direct counting', 'lookup table', 'divide and conquer'])
int.bit_count()函数。 - Peter Cordes