LR(1)分析器中使用的前瞻符号计算如下。首先,起始状态具有以下形式的项目:
S -> .w ($)
对于每个产生式S -> w,其中S是起始符号。这里,$标记表示输入的结束。
接下来,对于任何包含形如A -> x.By(t)的项目的状态,其中x是任意终结符和非终结符的字符串,B是一个非终结符,您需要为每个产生式B -> w和FIRST(yt)集合中的每个终结符添加一个形如B -> .w(s)的项目。(这里,FIRST是FIRST集合,通常在讨论LL解析器时引入。如果您以前没有见过它们,请花几分钟时间查看那些讲义)。
让我们在您的语法上尝试一下。我们首先创建一个包含项目集的项:
S -> .AB ($)
接下来,使用我们的第二个规则,对于A的每个产生式,我们添加一个新项,该项与产生式相对应,并具有FIRST(B$)中每个终结符的展望。由于B总是生成字符串d,FIRST(B$)= d,因此我们引入的所有产生式都将具有展望d。这给出
S -> .AB ($)
A -> .aAb (d)
A -> .a (d)
现在,让我们构建与初始状态中看到 'a' 相对应的状态。 我们从将点向右移动一步开始,为每个以 'a' 开始的产生式进行操作:
A -> a.Ab (d)
A -> a. (d)
现在,由于第一个项目在非终端之前有一个点,我们使用规则为A的每个产生式添加一个项目,给出这些项目的展望FIRST(bd) = b。这样就得到了。
A -> a.Ab (d)
A -> a. (d)
A -> .aAb (b)
A -> .a (b)
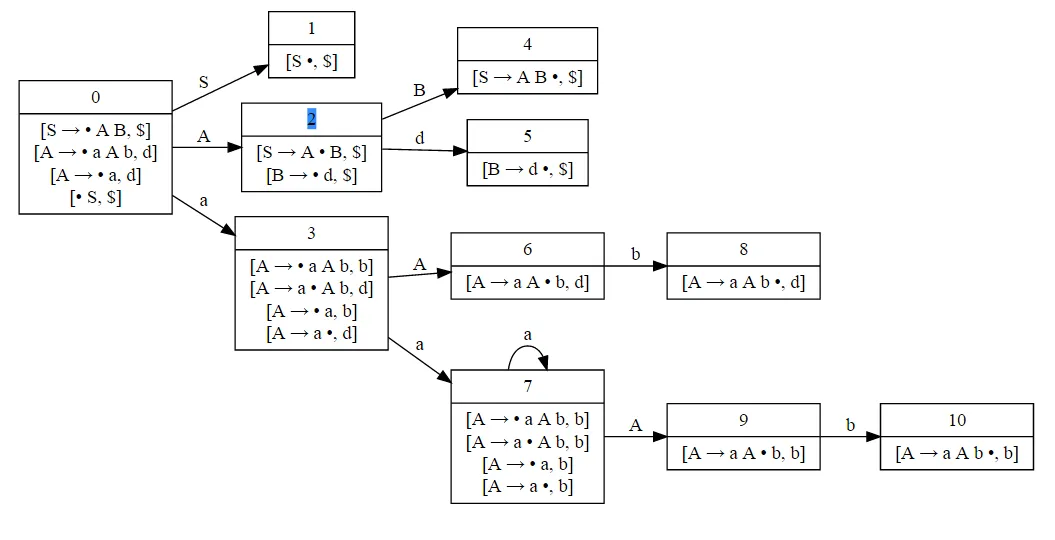
继续这个过程最终将构建出此LR(1)分析器的所有LR(1)状态。以下是示例:
[0]
S -> .AB ($)
A -> .aAb (d)
A -> .a (d)
[1]
A -> a.Ab (d)
A -> a. (d)
A -> .aAb (b)
A -> .a (b)
[2]
A -> a.Ab (b)
A -> a. (b)
A -> .aAb (b)
A -> .a (b)
[3]
A -> aA.b (d)
[4]
A -> aAb. (d)
[5]
S -> A.B ($)
B -> .d ($)
[6]
B -> d. ($)
[7]
S -> AB. ($)
[8]
A -> aA.b (b)
[9]
A -> aAb. (b)
如果有帮助的话,我去年夏天教授了一门编译器课程,
所有讲义幻灯片都可以在线获取。关于自底向上分析的幻灯片应该涵盖了LR分析和语法分析表构建的所有细节,希望你会发现它们很有用!希望这可以帮到你!