这是我的独特观点,但是基于我个人经验遇到的常见模式。而且,“父级”和“子级”这样的术语在谈论网格时我会尽量避免使用。你只需要拥有一个存储东西的大型二维或N维表/矩阵。没有任何层次结构涉及进来——这些数据结构更类似于数组而不是树。
“粗糙”和“精细”
关于“粗糙”和“精细”,我的意思是“粗糙”的搜索查询往往比较便宜,但会给出更多的误报。一个较粗的网格将是分辨率较低(较少,较大单元)的网格。粗略的搜索可能涉及遍历/搜索较少和较大的网格单元。例如,假设我们想要查看一个元素是否与一个点/圆点相交(想象一下只有一个1x1网格存储模拟中的所有内容)。如果圆点与单元格相交,则可以在该单元格返回大量元素,但实际上只有一个或没有一个元素实际上与圆点相交。
因此,“粗略”的查询是广泛而简单的,但没有非常精确地缩小候选人(或“嫌疑人”)列表。它可能会返回太多结果,并且仍然需要进行大量处理才能缩小实际上与搜索参数*相交的内容。
这就像在侦探节目中搜索可能的凶手时,输入“白人男性”可能不需要太多处理即可列出结果,但可能会给出太多结果以至于无法缩小嫌疑人范围。而“好”的情况则相反,可能需要更多的数据库处理,但可以将结果缩小到只有一个嫌疑人。这是一个粗略且有缺陷的比喻,但我希望它能有所帮助。
通常,在我们开始进行诸如内存优化之类的操作之前,广泛优化空间索引的关键是找到“粗略”和“细致”之间的平衡点,无论我们是在谈论空间哈希还是四叉树。如果过于“细致”,我们可能会花费太多时间遍历数据结构(在均匀网格中搜索许多小单元格,或在自适应网格(如四叉树)中花费太多时间进行树遍历)。如果过于“粗略”,空间索引可能会返回太多结果,无法显著减少进一步处理所需的时间。对于空间哈希(我个人不太喜欢的一种数据结构,但在游戏开发中非常流行),通常需要进行大量思考、实验和测量,以确定要使用的最佳单元格大小。
使用均匀的NxM网格,它们的“粗细”(大或小单元和高或低网格分辨率)不仅影响查询的搜索时间,还会影响插入和删除时间,如果元素大于一个点。如果网格太细,一个单独的大型或中等大小的元素可能必须插入到许多微小的单元格中,并从许多微小的单元格中删除,使用大量额外的内存和处理。如果网格太粗,元素可能只需要插入和从一个大单元格中删除,但会对数据结构缩小搜索查询返回的候选人数量的能力产生成本。如果不小心,过于“细/颗粒化”在实践中可能会成为非常瓶颈,开发人员可能会发现他的网格结构使用了几十亿字节的RAM来处理适度的输入大小。对于四叉树等树变体,如果允许的最大树深度值过高,则可能会发生类似的情况,当四叉树的叶节点存储最小的单元格大小时,会导致爆炸性的内存使用和处理(如果允许将单元格细分为树中太小的大小,我们甚至可以开始遇到破坏性能的浮点精度错误)。
加速性能的本质是一种平衡行为。例如,在计算机图形学中,我们通常不希望对正在渲染的单个多边形应用截头锥体剔除,因为这通常与硬件在剪辑阶段已经完成的工作重复,而且它也太“细/粒度”,需要太多的处理时间,与仅请求渲染一个或多个多边形所需的时间相比,这是不划算的。但是,如果我们将截头锥体剔除应用于整个生物或飞船(整个模型/网格),则可能会获得巨大的性能提升,从而避免了一次性请求渲染许多多边形。因此,在这些讨论中,我经常使用“粗略”和“细/粒度”这些术语(直到我找到更多人可以轻松理解的更好的术语)。
统一网格与自适应网格
您可以将四叉树视为具有自适应网格单元大小的“自适应”网格,按层次结构排列(从根到叶子逐步向下钻取,从“粗略”到“细”),而不是简单的NxM“统一”网格。
树形结构的自适应性非常智能,可以处理广泛的用例(尽管通常需要一些最大树深度和/或允许的最小单元大小的调整,以及在细分之前存储在单元/节点中的最大元素数量可能有所不同)。然而,优化树形数据结构可能更加困难,因为层次结构的本质并不容易适应我们的硬件和内存层次结构所适合遍历的连续内存布局。因此,我经常发现不涉及树的数据结构更容易优化,就像优化哈希表可能比优化红黑树更简单一样,特别是当我们可以预先了解要存储的数据类型时。
我经常倾向于在许多场景中更喜欢简单、更连续的数据结构,原因之一是实时模拟的性能需求通常不仅需要快速帧率,而且需要
一致 且可预测的帧率。这种一致性很重要,因为即使一个视频游戏在大部分时间内都有非常高的帧率,但如果游戏的某个部分导致帧率在短时间内急剧下降,玩家可能会因此死亡并失败。在我的情况下,避免这些类型的场景并且尽量减少数据结构中的病态最坏情况非常重要。通常情况下,我发现对于许多简单数据结构(不涉及自适应层次结构并且有点 "愚蠢"),我更容易预测其性能特征。很多时候,我发现帧率的稳定性和可预测性与我可以预测数据结构的整体内存使用情况以及内存使用的稳定性有关。如果内存使用是极不可预测和间歇性的,我通常(不总是,但经常)发现帧率也会是间歇性的。
所以我个人经常使用网格来获得更好的结果,但是如果在特定的仿真环境中难以确定单个最优单元格大小,我就使用多个实例:一个具有较大单元格大小的实例用于“粗略”搜索(例如10x10),一个具有较小单元格大小的实例用于“更细致”的搜索(例如100x100),甚至还可以使用更小单元格的实例进行“最细致”的搜索(例如1000x1000)。如果在粗略搜索中没有返回结果,则不进行更细致的搜索。这样我就可以平衡四叉树和网格的效益。
过去我在使用这些类型的表示法时,没有在所有三个网格实例中存储单个元素。这将使元素条目/节点在这些结构中的内存使用量增加三倍。相反,我插入了更细网格中占用单元格的索引到较粗网格中,因为通常占用单元格比仿真中的元素总数少得多。只有具有最小单元格大小的最高分辨率最细网格才会存储元素。最细网格中的单元格类似于四叉树的叶节点。
在我对那个问题的一个答案中,我称之为“松紧双网格”,它是对这个多网格思想的扩展。不同之处在于,更细的网格实际上是松散的,并且具有根据插入到其中的元素而扩展和收缩的单元格大小,始终保证单个元素(无论大小如何)只需插入到网格中的一个单元格即可。更粗的网格存储更细的网格的占用单元格,从而导致两个常数时间查询(一个在更粗的紧密网格中,另一个在更细的松散网格中),以返回与搜索参数匹配的潜在候选元素列表。它还具有最稳定和可预测的内存使用情况(不一定是最小内存使用情况,因为细/松散单元格需要存储一个轴对齐的边界框,该边界框会扩展/收缩,从而向单元格添加另外约16字节),并且相应的帧速率稳定,因为一个元素总是插入到一个单元格中,并且除了其自身的元素数据之外,不需要任何额外的内存来存储它,除非它的插入导致松散单元格扩展到必须插入更多单元格的程度,这应该是一个相当罕见的情况。
其他用途的多个网格
我有点困惑,因为我本能地会使用一个或者三个带有适当operator()的std::map来减少其内存占用,但我不确定它是否会很快,因为查询AABB意味着堆叠多个O(log n)的访问。
我认为这是我们许多人的直觉,也可能是潜意识中只想依靠一种解决方案来应对所有问题,因为编程可以变得非常乏味和重复,理想情况下只需实现一次并将其重用于所有事情:一件“一刀切”的T恤。但是,一件“一刀切”的衬衫可能不适合我们非常宽阔和肌肉发达的程序员身体。因此,有时候使用小号、中号和大号的比喻会有所帮助。
这可能是我尝试用幽默的方式使我的冗长文本更加有趣可读的一种尝试。
例如,如果您正在使用
std::map来实现类似于空间哈希的功能,则可能需要花费大量时间和精力来寻找最佳单元格大小。在视频游戏中,人们可能会妥协,将单元格大小相对于游戏中平均人类的大小(可能略小或略大),因为游戏中的许多模型/精灵都是为人类使用而设计的。但是对于微小的事物和巨大的事物来说,这可能会变得非常棘手并且非常次优。在这种情况下,我们最好抵制自己的直觉和欲望,不要只使用一个解决方案,而是使用多个解决方案(它仍然可以是相同的代码,但是使用不同参数构造的相同类实例的多个实例用于数据结构)。
关于搜索多个数据结构而不是单个数据结构的开销,最好进行测量,并且值得记住,每个容器的输入大小将因此变小,从而降低每次搜索的成本,并很可能提高引用的局部性。在需要对数搜索时间的分层结构(如std :: map)中,它可能超过了收益(或者不是,最好只是测量和比较),但我倾向于使用更多的数据结构,这些数据结构可以在常数时间内完成(网格或哈希表)。在我的情况下,我发现收益远远超过需要多次搜索才能执行单个查询的额外成本,特别是当元素大小差异巨大或我想要一些基本类似于具有2个或更多NxM网格的层次结构时,这些网格范围从“粗”到“细”。
关于“基于行的优化”,这与统一的固定大小网格而不是树非常相关。它指的是针对每行使用一个单独的可变大小列表/容器,而不是整个网格使用一个单独的列表/容器。除了可能减少空行的内存使用,这些空行只需变为空值而无需分配内存块,它还可以节省大量处理并改善内存访问模式。
如果我们为整个网格存储单个列表,那么我们必须不断地向该共享列表中插入和删除元素,因为元素移动、粒子产生等原因。这可能会导致更多的堆分配/释放来扩大和缩小容器,但也增加了从该列表中的一个元素到下一个元素的平均内存步幅,这将倾向于更多的缓存未命中,因为加载了更多的无关数据到缓存行中。此外,现在我们有很多核心,因此为整个网格使用单个共享容器可能会降低并行处理网格的能力(例如:在搜索一行的同时插入另一行)。它还可能导致结构的净内存使用更多,因为如果我们使用像
std::vector或
ArrayList这样的连续序列,它们通常可以存储所需元素的两倍内存容量,以通过最小化需要重新分配和复制前面元素的线性时间来将插入时间摊销为常数时间,从而减少插入时间。
通过为每个网格行或每个列关联一个单独的中等大小容器,而不是整个网格的巨大容器,我们可以在某些情况下减轻这些成本*。
这是一个需要在之前和之后进行测量的事情,以确保它实际上能够提高整体帧率,并且可能会尝试将整个网格存储为单个列表,从分析器中显示出许多非强制性的缓存未命中。
这可能会引发一个问题,为什么我们不为网格中的每个单元格使用单独的小型列表容器。这是一个平衡的过程。如果我们存储那么多容器(例如:对于一个1000x1000的网格而言,可能会有一百万个std :: vector实例,每个实例存储非常少或没有元素),它会允许最大化并行处理并最小化从单元格中的一个元素到下一个元素的跨度,但这会在内存使用方面产生相当大的开销,并引入大量额外的处理和堆开销。
特别是在我的情况下,我的最好的网格可能存储一百万个或更多的单元格,但每个单元格只需要4个字节。每个单元格的可变大小序列通常会在64位架构上膨胀至至少24个字节或更多(通常远远超过),以存储容器数据(通常是指针和几个额外的整数,或者在堆分配的内存块之上三个指针),但除此之外,插入到空单元格的每个单个元素都可能需要堆分配和强制缓存未命中和页面错误,并且由于缺乏时间局部性而非常频繁。因此,我发现平衡和甜点通常是每行一个列表容器,这是我最佳实现之一。
我使用我所谓的“单链数组列表”来存储网格行中的元素,并允许常数时间插入和删除,同时仍然允许某些程度的空间局部性,使得许多元素是连续的。它可以描述为:
struct GridRow
{
struct Node
{
...
int next = -1;
};
std::vector<Node> nodes;
int free_element = -1;
};
这将结合使用自由列表分配器的链表的一些优点,但无需管理单独的分配器和数据结构实现,因为我发现它们对我的目的来说过于通用和笨重。此外,以这种方式做可以使我们将指针的大小减半到64位架构上的32位数组索引,而不需要额外的32位填充,这在我的用例中是一个重要的优势,因为元素数据的对齐要求与32位索引相结合时,对于我的class/struct常常需要额外的32位填充,而我经常使用32位或更小的整数和32位单精度浮点数或16位半精度浮点数。
非正统的?
在这个问题上:
这种类型的网格搜索常见吗?
我不太确定!我在术语方面有些困难,需要向人们请求谅解和耐心沟通。我从80年代儿童时期开始编程,当时互联网并不普及,因此我开始依赖于发明自己的许多技术,并使用自己的粗糙术语作为结果。十五年后,当我二十多岁时获得了计算机科学学位,纠正了一些我的术语和误解,但我已经有很多年时间自己解决问题。因此,我经常不确定其他人是否遇到过相同的解决方案,以及它们是否有正式的名称和术语。
有时候,这使得与其他程序员的沟通变得困难和非常令人沮丧,我不得不请求耐心来解释我的想法。在会议上,我已经养成了一个习惯,总是先展示一些非常有前途的结果,这往往会让人们更加耐心地听我冗长而粗糙的解释它们是如何工作的。如果我从结果开始展示,他们往往会给我的想法更多的机会,但我常常对这个行业中普遍存在的正统主义和教条主义感到非常沮丧,有时会将概念优先于执行和实际结果。我本质上是一个实用主义者,所以我不会考虑“什么是最好的数据结构?”我会考虑我们可以根据自己的优点和缺点有效地实现什么是直观和反直觉的,并且我愿意在概念的纯度方面无限妥协,以换取更简单、更少问题的执行。我只喜欢那些自然流畅的好的可靠解决方案,无论它们是正统还是非正统的,但由于这个原因,我的很多方法可能是非正统的(或者也可能是我还没有找到做过同样事情的人)。我发现这个网站在偶尔找到像我一样的同行时非常有用,“哦,我也做过这个!如果我们这样做,我发现最好的结果是......”或者有人指出,“你提出的是......”。
在性能关键的情况下,我会让分析器为我提供数据结构,粗略地说。也就是说,我会想出一些快速的初稿(通常非常正统),并用分析器来测量它,让分析器的结果给我提供第二个草案的想法,直到我收敛到既简单又高效,并且适当可扩展的要求(这可能会沿着不太正统的方式进行)。我很乐意放弃很多想法,因为我认为我们必须通过淘汰的过程来筛选出好的想法,所以我倾向于循环实现和想法,并成为一个真正快速的原型制作者(我有一种心理倾向,固执地爱上了我花费大量时间解决的问题,所以为了对抗这一点,我学会了在解决方案上花费绝对最少的时间,直到它非常有前途)。
你可以在那个问题的答案中看到我的确切方法,我通过大量的分析和测量,在几天的时间里进行了迭代收敛,并从一个相当正统的四叉树原型到那个不正统的“松紧双网格”解决方案,它处理了最多的代理人数,在最稳定的帧速率下运行得非常快且实现起来比之前所有的结构都更简单。我必须经历很多正统的解决方案并对它们进行测量,才能生成不寻常的松紧变体的最终想法。我总是从正统的解决方案开始,并且因为它们有很好的文档记录和理解,所以一开始就留在盒子里,但是当要求足够高时,我经常发现自己有点超出了范围。作为一个在引擎上工作的较低级别的人员,我对于处理更多数据以获得良好的帧速率的能力并不陌生,这通常不仅可以为用户提供更高的互动性,而且还允许艺术家创建比以往任何时候都更高视觉质量的更详细内容。我们始终在追求更高更高的视觉质量和良好的帧速率,这通常归结为性能和尽可能使用粗略近似的组合。这不可避免地导致了某种程度的非正统性,有很多内部解决方案非常独特,适用于特定的引擎,每个引擎都倾向于具有自己非常独特的优点和缺点,就像比较CryEngine、虚幻引擎、Frostbite和Unity一样。
例如,我有一个数据结构,从小时候开始就一直在使用,但我不知道它的名字。这是一个简单明了的概念,它只是一种分层位集合,允许在几次简单的操作中找到可能包含数百万个元素的集合的交集,并且只需几次迭代即可遍历占用集合的数百万个元素(仅通过数据结构本身返回占用元素/位索引范围而不是单个元素/位索引来遍历集合所需的线性时间要求)。但我不知道它的名称,因为它只是我自己编写的,而且我从未在计算机科学中听说过任何人谈论它。我倾向于将其称为“分层位集合”。最初我称之为“稀疏位集树”,但那似乎有点啰嗦。这并不是一个特别聪明的概念,我不会感到惊讶或失望(实际上非常高兴)如果发现有人在我之前发现了同样的解决方案,但这是我从未见过别人使用或讨论的解决方案。它只是扩展了常规的平面位集合的优点,可以通过按位OR快速查找集合交集,并使用FFZ / FFS快速遍历所有集合位,但将两者的线性时间要求降低到对数级别(对数基数远大于2)。
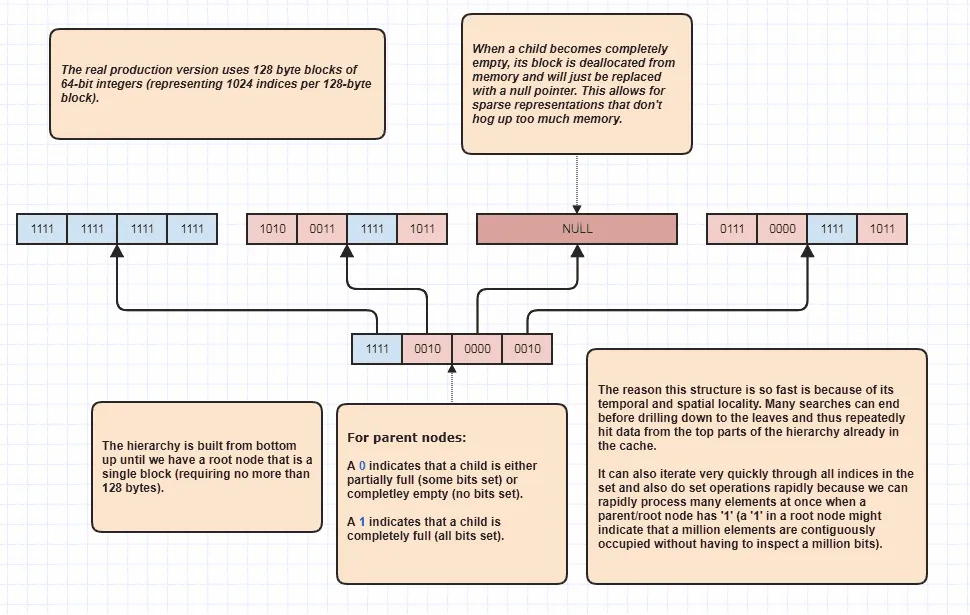
无论如何,如果这些解决方案中有一些非常不正统,我也不会感到惊讶,但如果它们是相当正统的,只是我没有找到这些技术的正确名称和术语,我也不会感到惊讶。对于我来说,这样的网站的吸引力在于寻找使用类似技术的其他人,并尝试找到适当的名称和术语,通常以挫败告终。我还希望提高自己解释这些技术的能力,尽管我在这里总是表达得很糟糕和冗长。我发现使用图片对我很有帮助,因为我发现人类语言充满了歧义。我也喜欢故意不精确的比喻性语言,它包容并庆祝歧义,例如隐喻、类比和幽默夸张,但我发现程序员往往不太欣赏这种缺乏精度的东西。但我从来没有觉得精度那么重要,只要我们能传达关键信息和一个想法的“酷”之处,而他们可以对其余部分进行自己的解释。对于整个解释,我表示歉意,但希望这些内容能够澄清我的粗略术语和我用于到达这些技术的整体方法。此外,英语不是我的母语,这增加了另一层复杂性,我必须将自己的思想翻译成英语单词,并且在这方面遇到了很多困难。