我想了解在Swift中存储在栈和堆中的内容。我有一个大概的估计:所有打印出来并显示内存地址而非具体值的对象都存储在栈中,所有打印出来作为具体值的对象都存储在堆中,这基本上取决于值类型和引用类型。我的理解完全错误吗?如果可以的话,能否提供栈/堆的可视化表示?
Swift堆和栈的理解
76
- Dániel Nagy
1
2这个演示介绍了Swift在堆和栈上的一些用法:https://realm.io/news/andy-matuschak-controlling-complexity/。简而言之,在Swift中,你不能像在C语言中那样假设一个值或引用最终会在堆还是栈上。 - Krzysztof Szafranek
4个回答
90
正如@Juul所述,引用类型存储在堆中,而值类型存储在栈中。
以下是解释: 栈和堆 栈用于静态内存分配,堆用于动态内存分配,两者都存储在计算机的RAM中。
在栈上分配的变量直接存储到内存中,对该内存的访问非常快,并且其分配在编译程序时确定。当一个函数或方法调用另一个函数,该函数又调用另一个函数等等,所有这些函数的执行都保持挂起,直到最后一个函数返回其值。栈始终以LIFO顺序保留,最近保留的块始终是下一个要释放的块。这使得跟踪栈非常简单。从栈中释放块只是调整一个指针。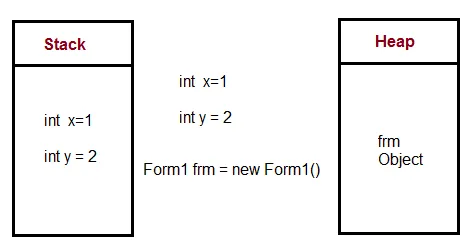 在堆上分配的变量在运行时分配其内存,访问此内存较慢,但堆的大小仅受虚拟内存大小的限制。堆的元素彼此之间没有依赖关系,可以随时任意访问。您可以随时分配块并释放它。这使得跟踪堆的哪些部分在任何给定时间分配或空闲更加复杂。
在堆上分配的变量在运行时分配其内存,访问此内存较慢,但堆的大小仅受虚拟内存大小的限制。堆的元素彼此之间没有依赖关系,可以随时任意访问。您可以随时分配块并释放它。这使得跟踪堆的哪些部分在任何给定时间分配或空闲更加复杂。
对于逃逸闭包:需要记住的一点是,在捕获在栈上存储的值的情况下,该值将被复制到堆中,以便在执行闭包时仍然可用。
更多参考信息:http://net-informations.com/faq/net/stack-heap.htm
以下是解释: 栈和堆 栈用于静态内存分配,堆用于动态内存分配,两者都存储在计算机的RAM中。
在栈上分配的变量直接存储到内存中,对该内存的访问非常快,并且其分配在编译程序时确定。当一个函数或方法调用另一个函数,该函数又调用另一个函数等等,所有这些函数的执行都保持挂起,直到最后一个函数返回其值。栈始终以LIFO顺序保留,最近保留的块始终是下一个要释放的块。这使得跟踪栈非常简单。从栈中释放块只是调整一个指针。
在堆上分配的变量在运行时分配其内存,访问此内存较慢,但堆的大小仅受虚拟内存大小的限制。堆的元素彼此之间没有依赖关系,可以随时任意访问。您可以随时分配块并释放它。这使得跟踪堆的哪些部分在任何给定时间分配或空闲更加复杂。对于逃逸闭包:需要记住的一点是,在捕获在栈上存储的值的情况下,该值将被复制到堆中,以便在执行闭包时仍然可用。
更多参考信息:http://net-informations.com/faq/net/stack-heap.htm
- Jaydeep Vyas
5
16需要记住的重要一点是,如果堆栈中存储的值被捕获到闭包中,那么该值将被移动到堆中,以便在执行闭包时仍然可用。 - Oleksandr Kruk
6这只适用于逃逸闭包,因为只有它们可以在以后执行。 - Cristik
1@Cristik 这是真的 :), 根据我的经验,大多数都是逃逸闭包,因为代理/异步请求使用了大量的闭包,这就是为什么我提到它作为需要记住的事情。 - Oleksandr Kruk
1@Cristik,感谢您的评论,我已经更新了我的答案。 - Jaydeep Vyas
4因为你的答案大部分是从这里 http://net-informations.com/faq/net/stack-heap.htm 复制的,所以最好将其作为参考链接。 - Nat
20
类(引用类型)是分配在堆上的,值类型(例如结构体、字符串、整数、布尔等)存储在栈中。有关更详细的答案,请参见此主题:为什么选择结构体而不是类?
- Juul
5
13这已经不是真的了。Swift可以优化一些分配,使它们成为堆栈分配,当它可以证明值不会逃逸时。值类型和引用类型是一个概念上的差异,它并不取决于值被分配到哪里。 - russbishop
3谢谢你的提问。这是翻译的结果:@russbishop 谢谢你的澄清。是否有一个网页链接,更详细地解释了你提到的优化方法? - code4latte
2@russbishop 肯定会感激附带解释的链接。 - rommex
这种优化被称为“堆栈提升”。我在网上找不到任何概述其行为的文章,但如果你感兴趣,可以查阅Swift源代码。 - Dmitry Serov
7
通常当我们问这样的问题(是栈还是堆)时,我们关心性能,并且受到避免堆分配过度成本的愿望的驱动。遵循“引用类型被分配到堆上,值类型被分配到栈上”的通用规则可能会导致次优化的设计决策,并需要进一步讨论。
有人可能错误地得出结论,传递结构体(值类型)普遍比传递类(引用类型)更快,因为它永远不需要堆分配。事实证明这并不总是正确的。
重要的反例是协议类型,其中具有值语义(结构体)的具体多态类型实现了一个协议,就像在这个玩具示例中一样:
注意,
事实证明底层有很多逻辑。Swift编译器会创建所谓的
如此将协议类型对象传递给函数可能需要堆分配。编译器会进行分配和复制操作,以便您仍然可以获得值语义,但成本将取决于结构体是否长达3个字长。这使得“值类型在栈上,引用类型在堆上”并不总是正确的。
有人可能错误地得出结论,传递结构体(值类型)普遍比传递类(引用类型)更快,因为它永远不需要堆分配。事实证明这并不总是正确的。
重要的反例是协议类型,其中具有值语义(结构体)的具体多态类型实现了一个协议,就像在这个玩具示例中一样:
protocol Vehicle {
var mileage: Double { get }
}
struct CombustionCar: Vehicle {
let mpg: Double
let isDiesel: Bool
let isManual: Bool
var fuelLevel: Double // gallons
var mileage: Double { fuelLevel * mpg }
}
struct ElectricCar: Vehicle {
let mpge: Double
var batteryLevel: Double // kWh
var mileage: Double { batteryLevel * mpge / 33.7 }
}
func printMileage(vehicle: Vehicle) {
print("\(vehicle.mileage)")
}
let datsun: Vehicle = CombustionCar(mpg: 18.19,
isDiesel: false,
isManual: false,
fuelLevel: 12)
let tesla: Vehicle = ElectricCar(mpge: 132,
batteryLevel: 50)
let vehicles: [Vehicle] = [datsun, tesla]
for vehicle in vehicles {
printMileage(vehicle: vehicle)
}
注意,
CombustionCar和ElectricCar对象的大小不同,但我们能够将它们混合在一个Vehicle协议类型的数组中。这引出了一个问题:容器元素难道不需要具有相同的大小吗?如果编译器无法始终知道元素大小,它如何计算数组元素的偏移量?事实证明底层有很多逻辑。Swift编译器会创建所谓的
Existential Container。它是一个固定大小的数据结构,作为对象的包装器。它被传递给函数调用(压入堆栈)而不是实际的结构体。
Existential Container由五个单词组成。| |
|valueBuffer|
| |
| vwt |
| pwt |
前三个字被称为valueBuffer,这是实际结构体存储的地方。不过,如果结构体大小大于三个字,则编译器会在堆上分配结构体,并将引用存储在valueBuffer中:
STACK STACK HEAP
| mpge | | reference |-->| mpg |
|batteryLevel| | | | isDiesel |
| | | | | isManual |
| vwt | | vwt | | fuelLevel |
| pwt | | pwt |
如此将协议类型对象传递给函数可能需要堆分配。编译器会进行分配和复制操作,以便您仍然可以获得值语义,但成本将取决于结构体是否长达3个字长。这使得“值类型在栈上,引用类型在堆上”并不总是正确的。
- Hubert Pietrzykowski
3
感谢你做出这样深入的解释,真的很棒!我想更多地了解它,如果你能分享任何有用的资源,我也将非常感激。 - joliejuly
非常好的解释,Hubert。你能否提供一些文档链接来说明这些知识的来源?让我们让你的答案经得起时间的考验。 - rojarand
1@joliejuly 这里有一个很好的解释:https://developer.apple.com/videos/play/wwdc2016/416/ - rojarand
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 4 C#中的栈和堆
- 6 堆/栈和多进程
- 8 Swift中关于栈和堆的误解
- 17 为什么需要堆和栈?
- 4 块、栈和堆
- 4 理解栈、堆和内存管理
- 10 一个栈和栈,以及一个堆和堆的区别
- 6 JVM - 堆和栈
- 10 Windows汇编堆和栈?
- 7 线程堆和栈