在x86架构中,指令编码的形式使得解码器可以从每个字节中了解接下来还有多少个字节。
例如,我来向您展示一下解码器如何解码这条指令流。
55
解码器看到
55 并知道这是一个单字节指令
push ebp。因此,它解码
push ebp 并继续执行下一条指令。
push ebp
89
解码器看到的是
89,这是
mov r/m32,r32指令。紧接着该指令后面跟着一个
modr/m字节,用于指定操作数。
push ebp
89 e5
modr/m字节为e5,表示ebp是r/m操作数,esp是r操作数,因此该指令为mov ebp, esp。
push ebp
mov ebp, esp
8b
这个指令是mov r32,r/m32,后面同样跟着一个modr/m字节。
push ebp
mov ebp, esp
8b 45
这个modr/m字节有一个eax操作数和一个操作数,其中的格式为[ebp + disp8],并带有一个8位位移,该位移在下一个字节中给出。
push ebp
mov ebp, esp
8b 45 0c
位移为
0c,因此指令为
mov eax, [ebp + 0xc]。
push ebp
mov ebp, esp
mov eax, [ebp + 0xc]
03
这个指令是add r,r/m32,后面再跟一个modr/m字节。
push ebp
mov ebp, esp
mov eax, [ebp + 0x0c]
03 45
与之前相同,r 操作数为 eax,而 r/m 操作数为 [ebp + disp8]。位移为 08。
push ebp
mov ebp, esp
mov eax, [ebp + 0x0c]
add eax, [ebp + 0x08]
01
这个指令是add r/m32, r,后面跟着一个modr/m字节。
push ebp
mov ebp, esp
mov eax, [ebp + 0x0c]
add eax, [ebp + 0x08]
01 05
这个modr/m字节指示了一个r操作数为eax和一个r/m操作数为[disp32]。下一个四个字节是位移,分别为00 00 00 00。
push ebp
mov ebp, esp
mov eax, [ebp + 0x0c]
add eax, [ebp + 0x08]
add [0x00000000], eax
5d
5d指令是pop ebp,是一条单字节指令。
push ebp
mov ebp, esp
mov eax, [ebp + 0x0c]
add eax, [ebp + 0x08]
add [0x00000000], eax
pop ebp
c3
c3 指令是一个单字节指令,其操作为 ret。该指令会将控制权转移到其他地方,因此解码器从这里停止解码。
push ebp
mov ebp, esp
mov eax, [ebp + 0x0c]
add eax, [ebp + 0x08]
add [0x00000000], eax
pop ebp
ret
在实际的x86处理器中,采用了复杂的并行解码技术。这是可能的,因为处理器可以作弊并预先读取可能或可能不是任何指令的指令字节。
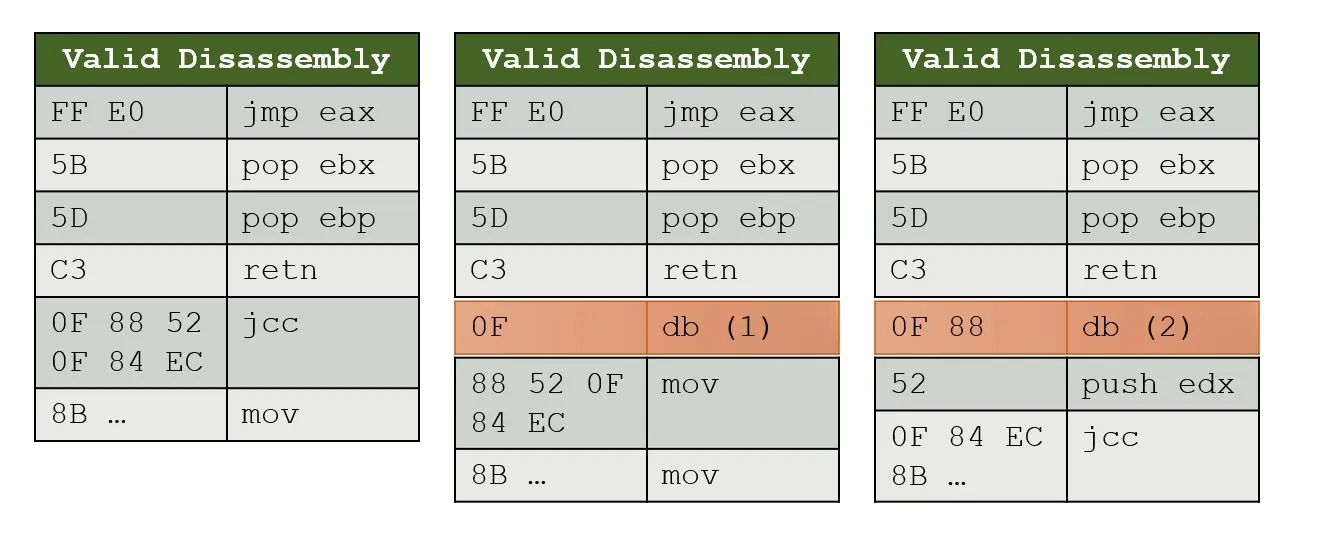
55是push rbp还是push ebp(取决于是 32 位还是 64 位模式)?CPU 必须知道如何解码和解释指令字节,并在这个过程中确定指令的长度。 - RbMmjmp eax将去哪里。 - Jesterretn,这是另一个动态跳转,你不知道它会带你去哪里。顺便说一下,在极端情况下,相同的字节可能会被多次执行,但指令边界不同,因此 CPU 将以不同的方式执行它,因此没有单一正确的反汇编。 - Jester