Consider the following piece of code:
package com.sarvagya;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.stream.Collectors;
public class Streamer {
private static final int LOOP_COUNT = 2000;
public static void main(String[] args){
try{
for(int i = 0; i < LOOP_COUNT; ++i){
poolRunner();
System.out.println("done loop " + i);
try{
Thread.sleep(50L);
}
catch (Exception e){
System.out.println(e);
}
}
}
catch (ExecutionException | InterruptedException e){
System.out.println(e);
}
// Add a delay outside the loop to make sure all daemon threads are cleared before main exits.
try{
Thread.sleep(10 * 60 * 1000L);
}
catch (Exception e){
System.out.println(e);
}
}
/**
* poolRunner method.
* Assume I don't have any control over this method e.g. done by some library.
* @throws InterruptedException
* @throws ExecutionException
*/
private static void poolRunner() throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
pool.submit(() ->{
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7,8,9,10, 11,12,14,15,16);
List<Integer> collect = numbers.stream()
.parallel()
.filter(xx -> xx > 5)
.collect(Collectors.toList());
System.out.println(collect);
}).get();
}
}
在上面的代码中,
poolRunner方法创建了一个ForkJoinPool并向其中提交一些任务。当使用Java 8并将LOOP_COUNT设置为2000时,我们可以看到最大线程数约为3600,如下所示:
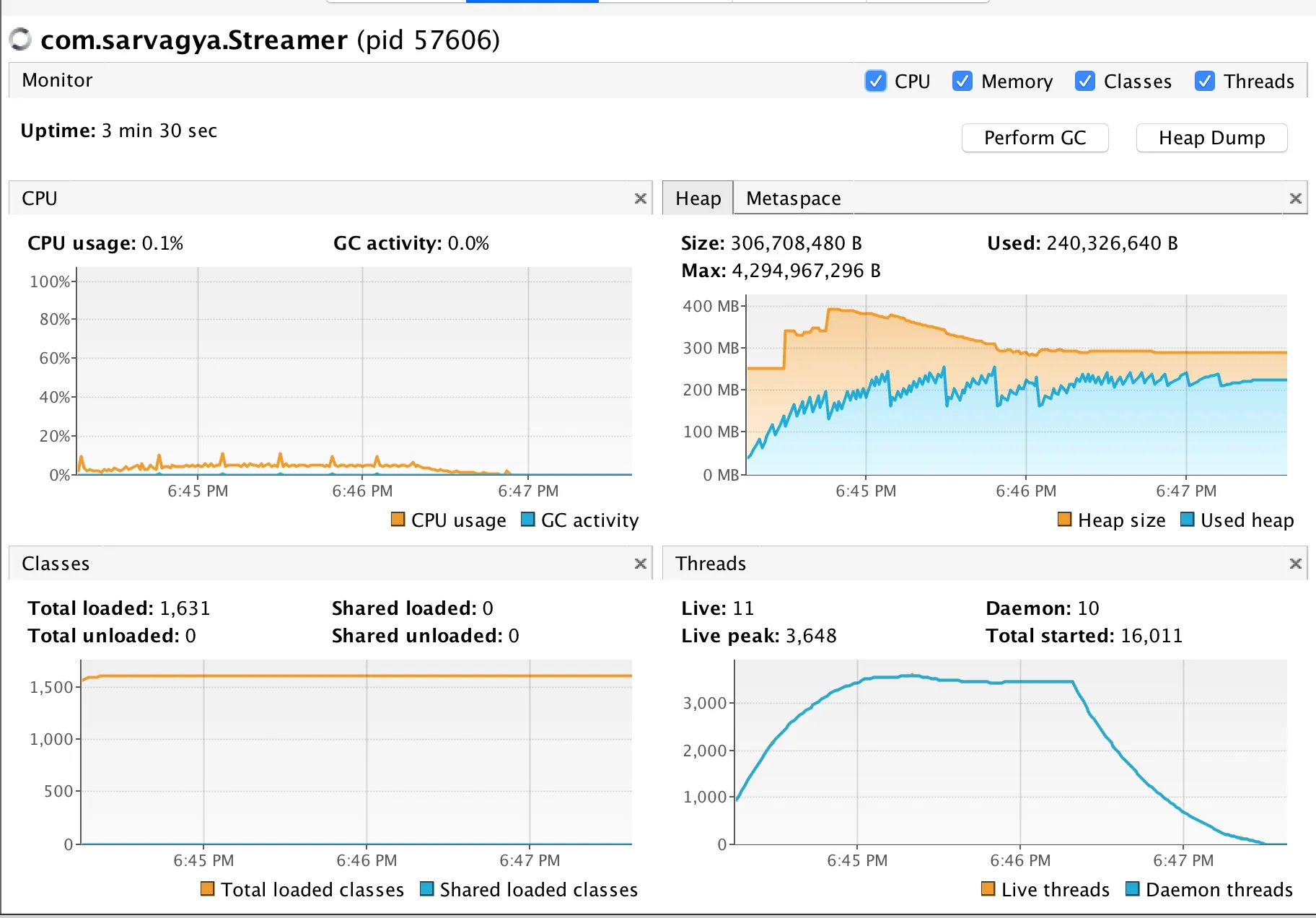 图:性能分析
图:性能分析
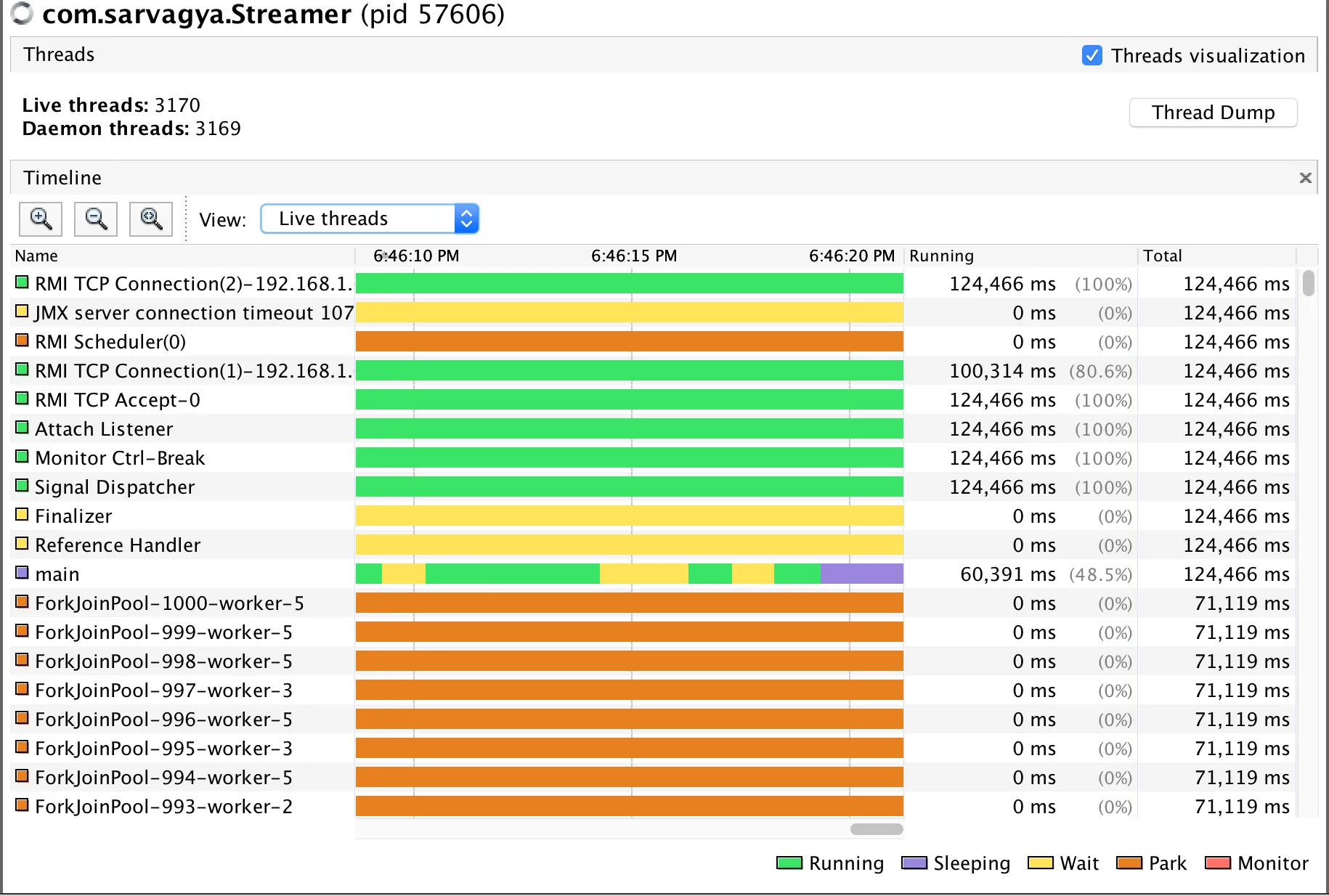 图:线程信息。
图:线程信息。
[28.822s][warning][os,thread] Failed to start thread - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached.
[28.822s][warning][os,thread] Failed to start thread - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached.
[28.822s][warning][os,thread] Failed to start thread - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached.
Exception in thread "ForkJoinPool-509-worker-5" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reached
at java.base/java.lang.Thread.start0(Native Method)
at java.base/java.lang.Thread.start(Thread.java:803)
at java.base/java.util.concurrent.ForkJoinPool.createWorker(ForkJoinPool.java:1329)
at java.base/java.util.concurrent.ForkJoinPool.tryAddWorker(ForkJoinPool.java:1352)
at java.base/java.util.concurrent.ForkJoinPool.signalWork(ForkJoinPool.java:1476)
at java.base/java.util.concurrent.ForkJoinPool.deregisterWorker(ForkJoinPool.java:1458)
at java.base/java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:187)
很快就达到了最大线程限制。将LOOP_COUNT保持在500,工作正常,但是这些线程清除得非常缓慢,并且达到了约500个线程的平台。请参见下面的图像:
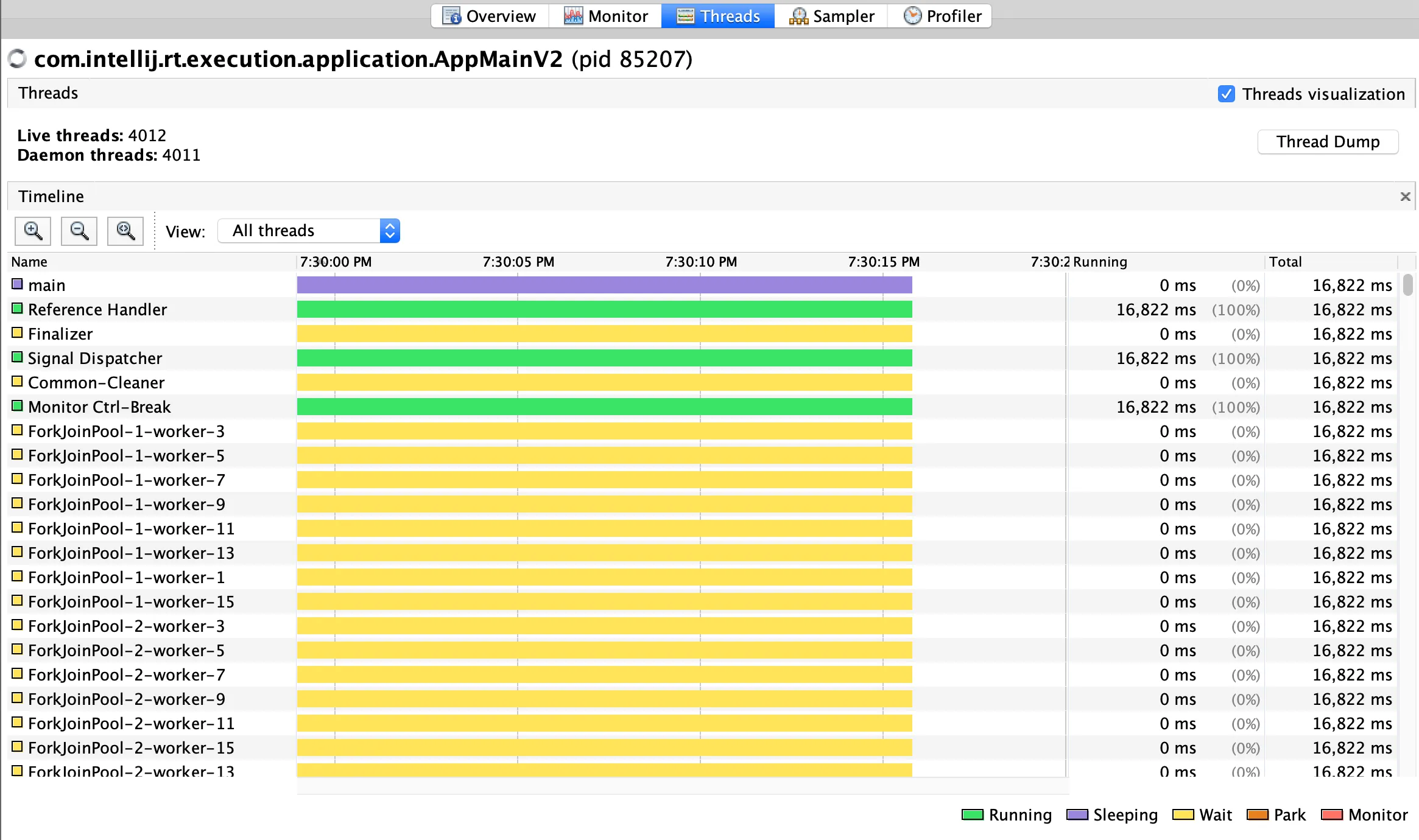 图:OpenJDK 11中的线程信息
图:OpenJDK 11中的线程信息
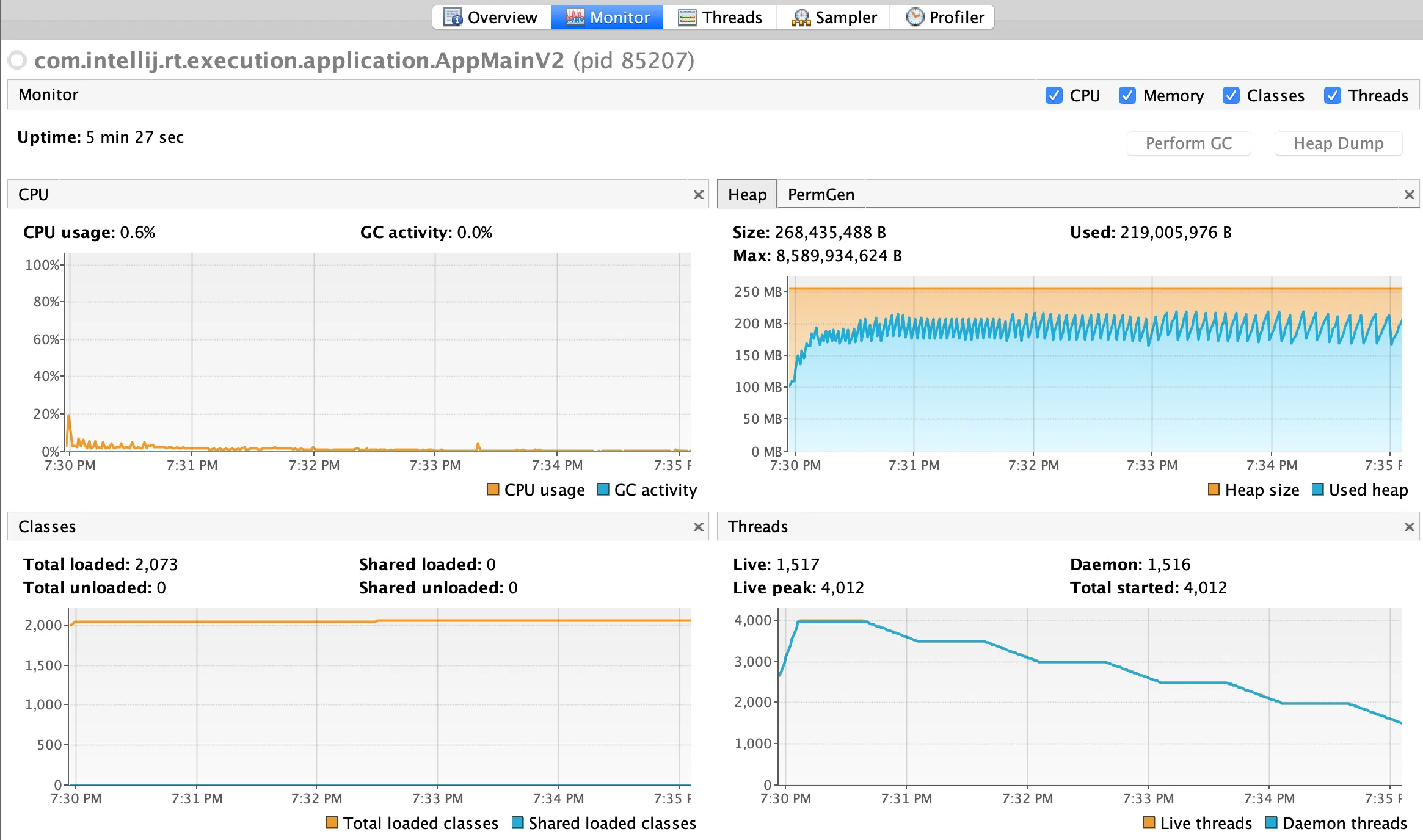 图:OpenJDK 11中的性能分析
图:OpenJDK 11中的性能分析
这个问题是OpenJDK 11的问题还是我的代码有问题。谢谢。