编辑:我保留了我的答案的第一部分,因为如果这不是一项学校任务,那么在我看来,这仍然是一种更好的方法。我用更新替换了答案的第二部分以匹配 OP 的问题。
您似乎想要做的是创建一个查询字符串解析器,它将读取查询字符串并将其转换为一系列 AND/OR/NOT 组合以返回正确的键。
有两种方法可以实现这一点。
- 根据您所写的需求,迄今为止最简单的解决方案是将数据加载到任何 SQL 数据库中(例如 SQLite,它不需要完整运行的 SQL 服务器),将字典键加载为单独的字段(如果您不关心正常形式等,则您的其余数据可以全部位于另一个字段中),并将传入的查询转换为 SQL,大致如下:
SQL 表至少具有以下内容:
CREATE TABLE my_data(
dictkey text,
data text);
python_query="foo OR bar AND NOT gazonk"
sql_keywords=["AND","NOT","OR"]
sql_query=[]
for word in python_query.split(" "):
if word in sql_keywords:
sql_query+=[ word ]
else:
sql_query+=["dictkey='%s'" % word]
real_sql_query=" ".join(sql_query)
这需要一些转义和控制检查以防止 SQL 注入和特殊字符,但通常它只会将您的查询转换为 SQL,当针对 SQL 数据库运行时,将返回键(可能还有数据)以进行进一步处理。
- 现在是纯 Python 版本。
您需要做的是分析您获得的字符串并将逻辑应用于您现有的 Python 数据。
将字符串分析为特定组件(及其交互)的过程称为 解析。如果您实际上想要构建自己的完整解析器,那么会有 Python 模块可用,但是对于学校作业,我希望您被要求构建自己的解析器。
根据您的描述,查询可以用准 BNF 形式 表达为:
(<[NOT] word> <AND|OR>)...
既然您说优先级并不重要,那么您可以采用逐字逐句解析的简单方式。
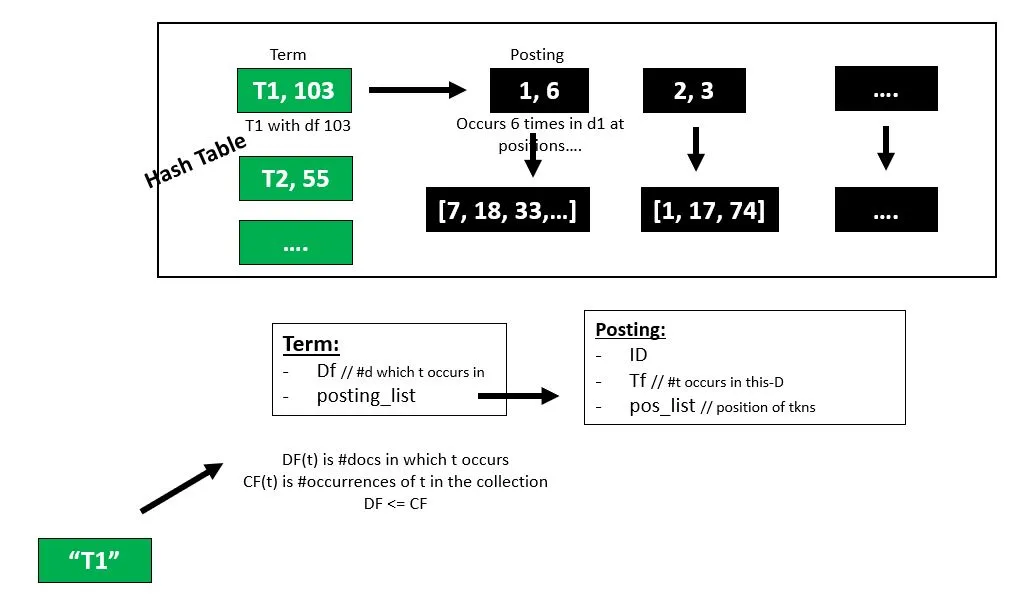
接下来,您需要将关键词与文件名匹配,而如其他答案中所提到的,最简单的方法是使用集合。
因此,大致可以按以下方式进行:
import re
query="foo OR bar AND NOT gazonk"
result_set=set()
operation=None
for word in re.split(" +(AND|OR) +",query):
inverted=False
if word in ['AND','OR']:
operation=word
continue
if word.find('NOT ') == 0:
if operation is 'OR':
continue
inverted=True
realword=word[4:]
else:
realword=word
if operation is not None:
current_set=set(inverted_index[realword].keys())
if operation is 'AND':
if inverted is True:
result_set -= current_set
else:
result_set &= current_set
elif operation is 'OR':
result_set |= current_set
operation=None
print result_set
请注意,这不是一个完整的解决方案(例如它没有包括处理查询的第一个术语,并且它要求布尔运算符为大写),也没有经过测试。但是,它应该能够实现展示如何处理它的主要目的。做更多的事情将会为您编写课程作业,这对您来说是不利的,因为您应该学习如何做它以便理解它。随时询问以获得澄清。