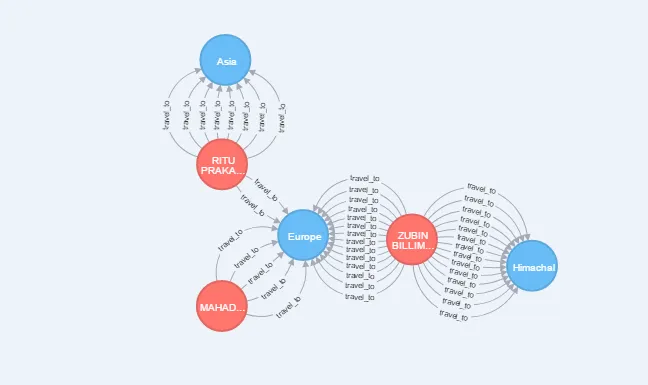
此图表是使用neo4j cypher查询获得的: MATCH (d:dest)-[r]-(n:cust) WITH d,n,count(r)作为popular RETURN d,n ORDER BY popular desc LIMIT 5
例如:在RITUPRAKA...和Asia之间有8个多个边缘,因此查询已返回2个节点以及边缘,其他节点同样如此。
请注意:图表中还有仅具有单个边缘的其他节点,这些节点将不会被返回。
我想在gremlin中做同样的事情。
我已经使用以下查询: g.V().as('out').out().as('in').select('out','in').groupCount().unfold().filter(select(values).is(gt(1))).select(keys)
它显示了 out:v [1234],in:v [3456] .....
但是,我想要显示节点的值而不是节点的ID,例如:out:ICIC1234,in:HDFC234。
我已经修改了查询语句为:g.V().values("name").as('out').out().as('in').values("name").select('out','in').groupCount().unfold().filter(select(values).is(gt(1))).select(keys)。
但是,它显示了类转换异常错误,每个遍历的顶点都需要使用索引进行快速迭代。