一些迭代器更快。我知道这是因为我从Channel 9的Bob Tabor那里听说过永远不要复制和粘贴。
我习惯于这样设置数组值:
testArray[0] = 0;
testArray[1] = 1;
这只是一个简单的示例,但为了不复制粘贴或重新输入,我想我应该使用循环。但我有这种感觉,循环比仅列出命令要慢,而且看起来我是对的:列出事物要快得多。在我的大多数试验中,速度从最快到最慢依次为列表、do循环、for循环和while循环。
为什么列出事物比使用迭代器快?为什么迭代器的速度不同?
如果我没有以最有效的方式使用这些迭代器,请帮助我。
以下是我的结果(对于2个int数组),我的代码如下(对于4个int数组)。我在Windows 7 64位上尝试过几次。
无论是我不擅长迭代,还是使用迭代器并不像它所说的那样好。请告诉我哪一个是。非常感谢。
int trials = 0;
TimeSpan listTimer = new TimeSpan(0, 0, 0, 0);
TimeSpan forTimer = new TimeSpan(0, 0, 0, 0);
TimeSpan doTimer = new TimeSpan(0, 0, 0, 0);
TimeSpan whileTimer = new TimeSpan(0, 0, 0, 0);
Stopwatch stopWatch = new Stopwatch();
long numberOfIterations = 100000000;
int numElements = 4;
int[] testArray = new int[numElements];
testArray[0] = 0;
testArray[1] = 1;
testArray[2] = 2;
testArray[3] = 3;
// List them
stopWatch.Start();
for (int x = 0; x < numberOfIterations; x++)
{
testArray[0] = 0;
testArray[1] = 1;
testArray[2] = 2;
testArray[3] = 3;
}
stopWatch.Stop();
listTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
// for them
stopWatch.Start();
int q;
for (int x = 0; x < numberOfIterations; x++)
{
for (q = 0; q < numElements; q++)
testArray[q] = q;
}
stopWatch.Stop();
forTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
// do them
stopWatch.Start();
int r;
for (int x = 0; x < numberOfIterations; x++)
{
r = 0;
do
{
testArray[r] = r;
r++;
} while (r < numElements);
}
stopWatch.Stop();
doTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
// while
stopWatch.Start();
int s;
for (int x = 0; x < numberOfIterations; x++)
{
s = 0;
while (s < numElements)
{
testArray[s] = s;
s++;
}
}
stopWatch.Stop();
whileTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
Console.WriteLine("listTimer");
Console.WriteLine(listTimer);
Console.WriteLine("forTimer");
Console.WriteLine(forTimer);
Console.WriteLine("doTimer");
Console.WriteLine(doTimer);
Console.WriteLine("whileTimer");
Console.WriteLine(whileTimer);
Console.WriteLine("Enter any key to try again the program");
Console.ReadLine();
trials++;
当我尝试了一个四个元素的数组后,结果似乎更加明显了。
我认为如果像其他实验一样通过变量分配值给listThem组将是公平的。这确实使listThem组变慢了一点,但它仍然是最快的。在几次尝试后,以下是结果:
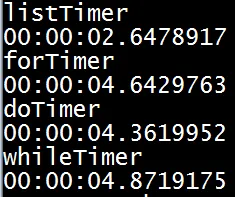 这是我如何实现列表的方式:
这是我如何实现列表的方式:int w = 0;
for (int x = 0; x < numberOfIterations; x++)
{
testArray[w] = w;
w++;
testArray[w] = w;
w++;
testArray[w] = w;
w++;
testArray[w] = w;
w = 0;
}
我知道这些结果可能是具体实现相关的,但你会认为微软应该警告我们每种循环的优劣之处,尤其是在速度方面。你怎么看?谢谢。
更新: 根据评论,我发布了代码,发现列表仍然比循环更快,但循环的性能更接近。循环的速度从快到慢依次为: for、while、do...while。这有点不同,所以我的猜测是do和while的速度基本相同,而for循环比do和while循环快约0.5%,至少在我的机器上是如此。以下是几次试验的结果: 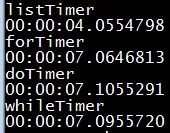
numElements的使用更改为硬编码数字(或将其更改为const)?编译器可能会决定展开内部循环。 - sinelaw