我们可以通过一个简单的例子来了解ROLLUP和CUBE之间的区别。考虑一张表,其中包含学生季度测试结果。在某些情况下,我们需要查看相应季度以及学生的总计。以下是示例表格:
SELECT * INTO #TEMP
FROM
(
SELECT 'Quarter 1' PERIOD,'Amar' NAME ,97 MARKS
UNION ALL
SELECT 'Quarter 1','Ram',88
UNION ALL
SELECT 'Quarter 1','Simi',76
UNION ALL
SELECT 'Quarter 2','Amar',94
UNION ALL
SELECT 'Quarter 2','Ram',82
UNION ALL
SELECT 'Quarter 2','Simi',71
UNION ALL
SELECT 'Quarter 3' ,'Amar',95
UNION ALL
SELECT 'Quarter 3','Ram',83
UNION ALL
SELECT 'Quarter 3','Simi',77
UNION ALL
SELECT 'Quarter 4' ,'Amar',91
UNION ALL
SELECT 'Quarter 4','Ram',84
UNION ALL
SELECT 'Quarter 4','Simi',79
)TAB
1. ROLLUP(可以找到与一列相对应的总数)
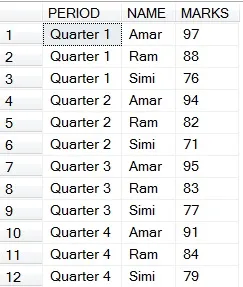
(a) 获取每个学生在所有季度中的总分。
SELECT * FROM #TEMP
UNION ALL
SELECT PERIOD,NAME,SUM(MARKS) TOTAL
FROM #TEMP
GROUP BY NAME,PERIOD
WITH ROLLUP
HAVING PERIOD IS NULL AND NAME IS NOT NULL
// Having is used inorder to emit a row that is the total of all totals of each student
以下是(a)的结果
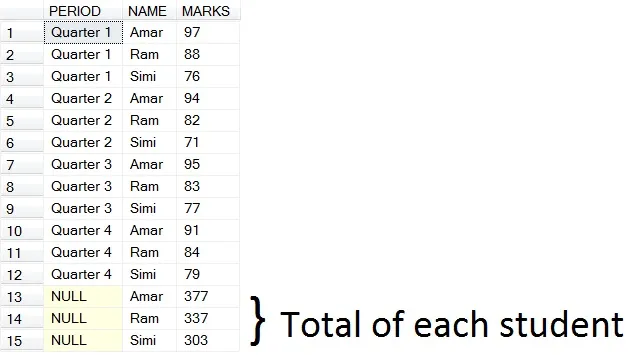
(b)如果您需要获得每个季度的总分数
SELECT * FROM #TEMP
UNION ALL
SELECT PERIOD,NAME,SUM(MARKS) TOTAL
FROM #TEMP
GROUP BY PERIOD,NAME
WITH ROLLUP
HAVING PERIOD IS NOT NULL AND NAME IS NULL
以下是(b)的结果
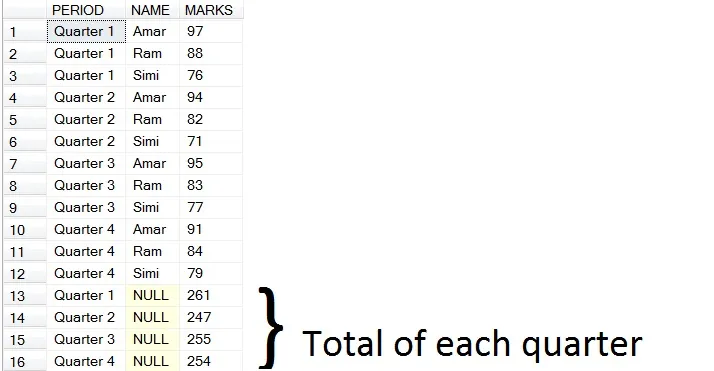
2. CUBE(在一次查询中查找季度和学生的总数)
SELECT PERIOD,NAME,SUM(MARKS) TOTAL
FROM #TEMP
GROUP BY NAME,PERIOD
WITH CUBE
HAVING PERIOD IS NOT NULL OR NAME IS NOT NULL
以下是CUBE的结果
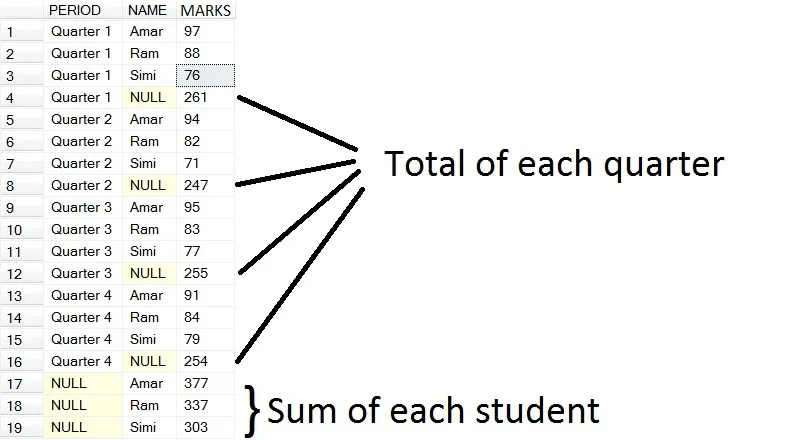
现在您可能会想知道ROLLUP和CUBE的实时用途。有时,我们需要一份报告,在其中一次性查看每个学季的总计和每个学生的总计。这里有一个例子。
我稍微修改了上面的CUBE查询,因为我们需要两个总计的总数。
SELECT CASE WHEN PERIOD IS NULL THEN 'TOTAL' ELSE PERIOD END PERIOD,
CASE WHEN NAME IS NULL THEN 'TOTAL' ELSE NAME END NAME,
SUM(MARKS) MARKS
INTO #TEMP2
FROM #TEMP
GROUP BY NAME,PERIOD
WITH CUBE
DECLARE @cols NVARCHAR (MAX)
SELECT @cols = COALESCE (@cols + ',[' + PERIOD + ']',
'[' + PERIOD + ']')
FROM (SELECT DISTINCT PERIOD FROM #TEMP2) PV
ORDER BY PERIOD
DECLARE @query NVARCHAR(MAX)
SET @query = 'SELECT * FROM
(
SELECT * FROM #TEMP2
) x
PIVOT
(
SUM(MARKS)
FOR [PERIOD] IN (' + @cols + ')
) p;'
EXEC SP_EXECUTESQL @query
现在您将获得以下结果
