我有一个以UTF-8编码的字符串。例如:
我需要提取句子中的所有表情符号。而且这些表情符号可以是任何东西。
当在终端中使用命令
这是表情符号的对应UTF代码。所有表情符号的代码可以在emojitracker找到。
为了找到所有出现的情况,我使用了一个正则表达式模式
以下是我的代码:
这个 pdf 说
That's a nice joke
我需要提取句子中的所有表情符号。而且这些表情符号可以是任何东西。
当在终端中使用命令
less text.txt查看这个句子时,它会显示为:That's a nice joke <U+1F606><U+1F606><U+1F606> <U+1F61B>
这是表情符号的对应UTF代码。所有表情符号的代码可以在emojitracker找到。
为了找到所有出现的情况,我使用了一个正则表达式模式
(<U\+\w+?>),但对于UTF-8编码的字符串却没有起作用。以下是我的代码:
String s = "That's a nice joke ";
Pattern pattern = Pattern.compile("(<U\\+\\w+?>)");
Matcher matcher = pattern.matcher(s);
List<String> matchList = new ArrayList<>();
while (matcher.find()) {
matchList.add(matcher.group());
}
for (int i = 0; i < matchList.size(); i++) {
System.out.println(matchList.get(i));
}
这个 pdf 说
范围:1F300–1F5FF 适用于杂项符号和象形文字。所以我想捕获在这个范围内的任何字符。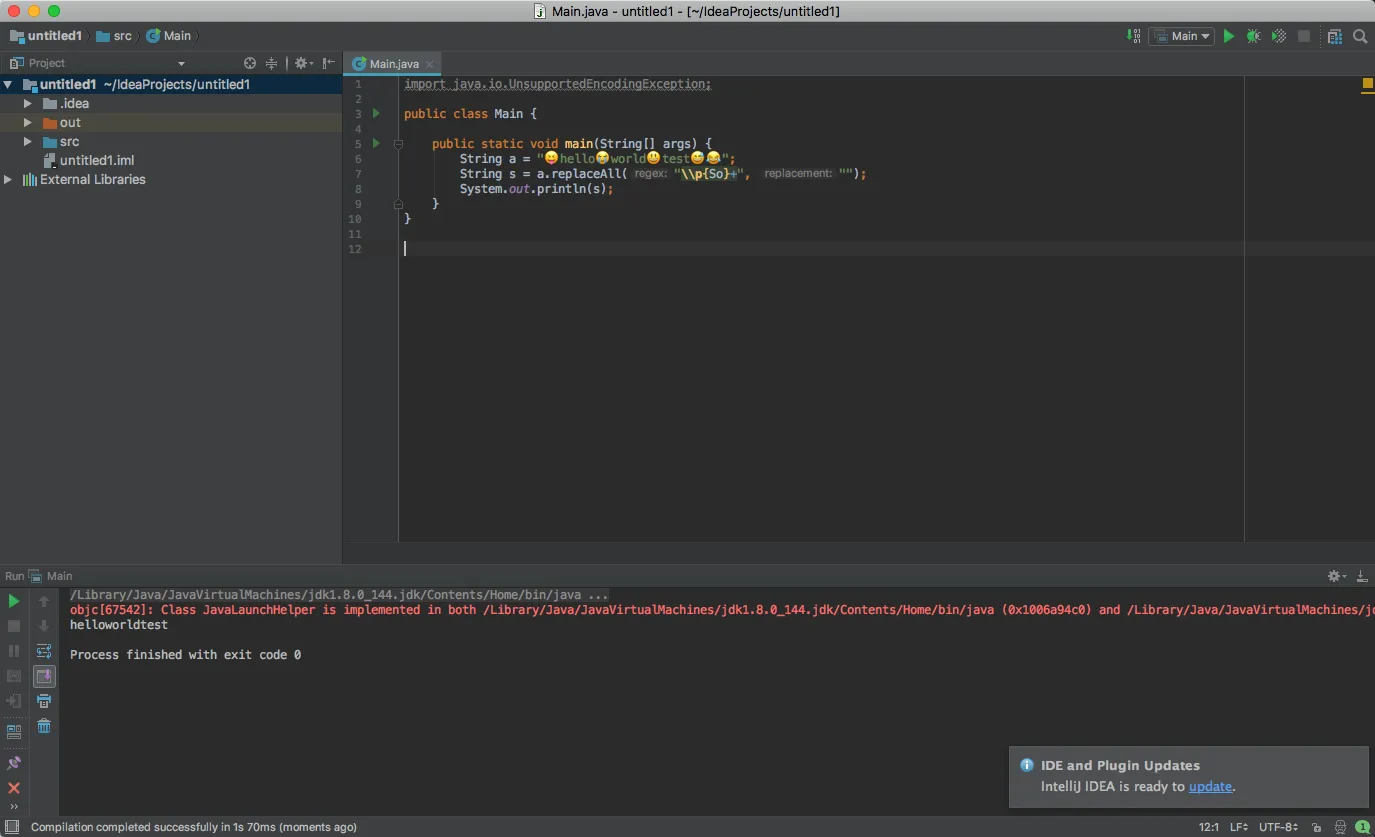
<U+1F606>字符串是特定于less的 - 此外,您的解决方案想法也会捕获几乎任何其他Unicode字符。唯一真正的解决方案是拥有所有与表情符号相对应的Unicode代码点列表。 - Drew McGowen