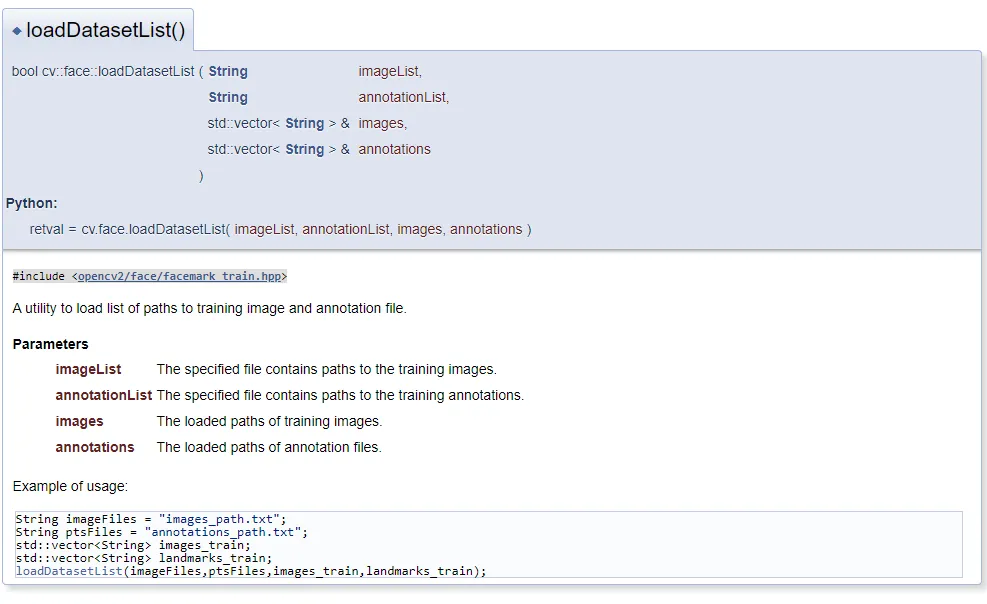
我目前正在尝试使用OpenCV 4.2.2训练一个数据集,我搜索了网络但只找到了两个参数的示例。OpenCV 4.2.2 loadDatasetList需要4个参数,但存在一些缺陷,我尽力克服了这些缺陷,并通过以下代码进行了尝试。我最初尝试了一个数组,但是loadDatasetList抱怨该数组不可迭代,然后我尝试下面的代码,但没有成功。感谢您的时间,希望每个人都安全健康。
之前的错误是传递了一个未经iter()处理的数组。
当前的错误是:
PS E:\MTCNN> python kazemi-train.py Traceback (most recent call last): File "kazemi-train.py", line 35, in status, images_train, landmarks_train = cv2.face.loadDatasetList(args.training_images,args.training_annotations, iter(imageFiles), iter(annotationFiles)) SystemError: returned NULL without setting an error
如果我只使用2个参数,会引发以下错误:
之前的错误是传递了一个未经iter()处理的数组。
当前的错误是:
PS E:\MTCNN> python kazemi-train.py Traceback (most recent call last): File "kazemi-train.py", line 35, in status, images_train, landmarks_train = cv2.face.loadDatasetList(args.training_images,args.training_annotations, iter(imageFiles), iter(annotationFiles)) SystemError: returned NULL without setting an error
import os
import time
import cv2
import numpy as np
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Training of kazemi facial landmark algorithm.')
parser.add_argument('--face_cascade', type=str, help="Path to the cascade model file for the face detector",
default=os.path.join(os.path.dirname(os.path.realpath(__file__)),'models','haarcascade_frontalface_alt2.xml'))
parser.add_argument('--kazemi_model', type=str, help="Path to save the kazemi trained model file",
default=os.path.join(os.path.dirname(os.path.realpath(__file__)),'models','face_landmark_model.dat'))
parser.add_argument('--kazemi_config', type=str, help="Path to the config file for training",
default=os.path.join(os.path.dirname(os.path.realpath(__file__)),'models','config.xml'))
parser.add_argument('--training_images', type=str, help="Path of a text file contains the list of paths to all training images",
default=os.path.join(os.path.dirname(os.path.realpath(__file__)),'train','images_train.txt'))
parser.add_argument('--training_annotations', type=str, help="Path of a text file contains the list of paths to all training annotation files",
default=os.path.join(os.path.dirname(os.path.realpath(__file__)),'train','points_train.txt'))
parser.add_argument('--verbose', action='store_true')
args = parser.parse_args()
start = time.time()
facemark = cv2.face.createFacemarkKazemi()
if args.verbose:
print("Creating the facemark took {} seconds".format(time.time()-start))
start = time.time()
imageFiles = []
annotationFiles = []
for file in os.listdir("./AppendInfo"):
if file.endswith(".jpg"):
imageFiles.append(file)
if file.endswith(".txt"):
annotationFiles.append(file)
status, images_train, landmarks_train = cv2.face.loadDatasetList(args.training_images,args.training_annotations, iter(imageFiles), iter(annotationFiles))
assert(status == True)
if args.verbose:
print("Loading the dataset took {} seconds".format(time.time()-start))
scale = np.array([460.0, 460.0])
facemark.setParams(args.face_cascade,args.kazemi_model,args.kazemi_config,scale)
for i in range(len(images_train)):
start = time.time()
img = cv2.imread(images_train[i])
if args.verbose:
print("Loading the image took {} seconds".format(time.time()-start))
start = time.time()
status, facial_points = cv2.face.loadFacePoints(landmarks_train[i])
assert(status == True)
if args.verbose:
print("Loading the facepoints took {} seconds".format(time.time()-start))
start = time.time()
facemark.addTrainingSample(img,facial_points)
assert(status == True)
if args.verbose:
print("Adding the training sample took {} seconds".format(time.time()-start))
start = time.time()
facemark.training()
if args.verbose:
print("Training took {} seconds".format(time.time()-start))
如果我只使用2个参数,会引发以下错误:
如果我尝试使用3个参数,则会引发以下错误:文件“kazemi-train.py”的第37行,在 status、images_train、landmarks_train = cv2.face.loadDatasetList(args.training_images,args.training_annotations) 中出现 TypeError: loadDatasetList()缺少必要参数'images'(pos 3)
loadDatasetList的文档:Traceback (最新调用的最后一次): File "kazemi-train.py", line 37, in status, images_train, landmarks_train = cv2.face.loadDatasetList(args.training_images,args.training_annotations, iter(imagePaths)) TypeError: loadDatasetList()缺少必要参数'annotations'(pos 4)