我想解析这个HTML表格的内容:
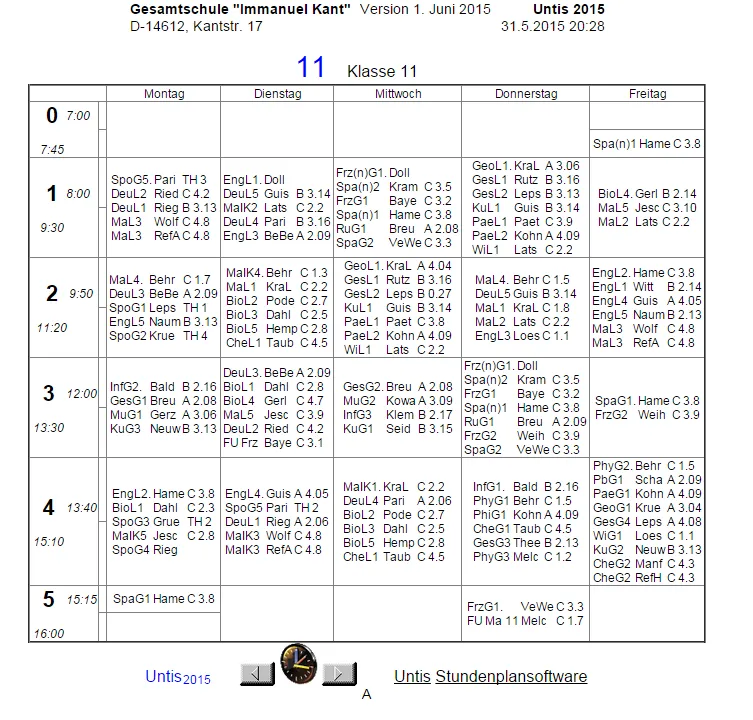
这是完整的带有源代码的网站:
我希望能够解析每个单元格的数据,以“星期一”下的5个单元格为例。我尝试使用JSOUP解析这个网站,但没有成功。我的主要目标是在Android应用程序中将内容显示在列表视图中。现在我尝试在Java控制台中打印内容。两种语言都可以接受 :). 感谢任何帮助。http://www.kantschule-falkensee.de/uploads/dmiadgspahw/klassen/A_Klasse_11.htm
我想解析这个HTML表格的内容:
这是完整的带有源代码的网站:
我希望能够解析每个单元格的数据,以“星期一”下的5个单元格为例。我尝试使用JSOUP解析这个网站,但没有成功。我的主要目标是在Android应用程序中将内容显示在列表视图中。现在我尝试在Java控制台中打印内容。两种语言都可以接受 :). 感谢任何帮助。http://www.kantschule-falkensee.de/uploads/dmiadgspahw/klassen/A_Klasse_11.htm
以下是您需要遵循的步骤:
1)您可以使用以下任何一种Java库进行HTML抓取:
2)使用XPath助手
例如1:在查询中输入"//tr[1]//td[1]",它将返回位于(1,1)位置的所有表元素
例如2:"/html/body[@class='tt']/center/table[1]/tbody/tr[4]/td[3]/table/tbody/tr/td"
将为您提供Montag下的所有15个值。
例如3:"/html/body[@class='tt']/center/table[1]/tbody/tr/td/table/tbody/tr/td"
将给您表格的所有380个条目
或者
使用Jsoup的示例
import org.jsoup.Jsoup;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
org.jsoup.nodes.Document doc = Jsoup.connect("http://www.kantschule-falkensee.de/uploads/dmiadgspahw/klassen/A_Klasse_11.htm").get();
org.jsoup.select.Elements rows = doc.select("tr");
for(org.jsoup.nodes.Element row :rows)
{
org.jsoup.select.Elements columns = row.select("td");
for (org.jsoup.nodes.Element column:columns)
{
System.out.print(column.text());
}
System.out.println();
}
}
}