我对以下表达式中的模式匹配有些困惑。我试图在网上查找,但找不到可理解的解决方案:
imgurUrlPattern = re.compile(r'(http://i.imgur.com/(.*))(\?.*)?')
这个括号到底是做什么的?我理解了第一个星号之前的内容,但是我无法弄清楚之后发生了什么。
正则表达式可以表示为图形以理解它们的操作。节点之间的并联连接表示可选,串联连接表示必须,而循环表示重复使用同一节点。
(http://i.imgur.com/(.*))(\?.*)?
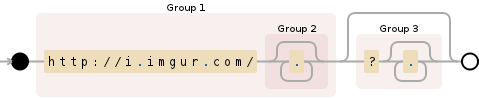
这个正则表达式从一个imgur的URL http://i.imgur.com/(.*)(必须)开始,直到遇到“?”为止(可选)。然后再匹配“?”后面的任意字符。请注意,“?”已经被转义以避免它的正常行为。粉色的高亮显示了捕获组。
(.*)" 表示任意数量的字符重复,"(\?.*)?" 匹配 URL 的查询字符串,例如 (a imgur search of "cat")。http://imgur.com/search?q=cat
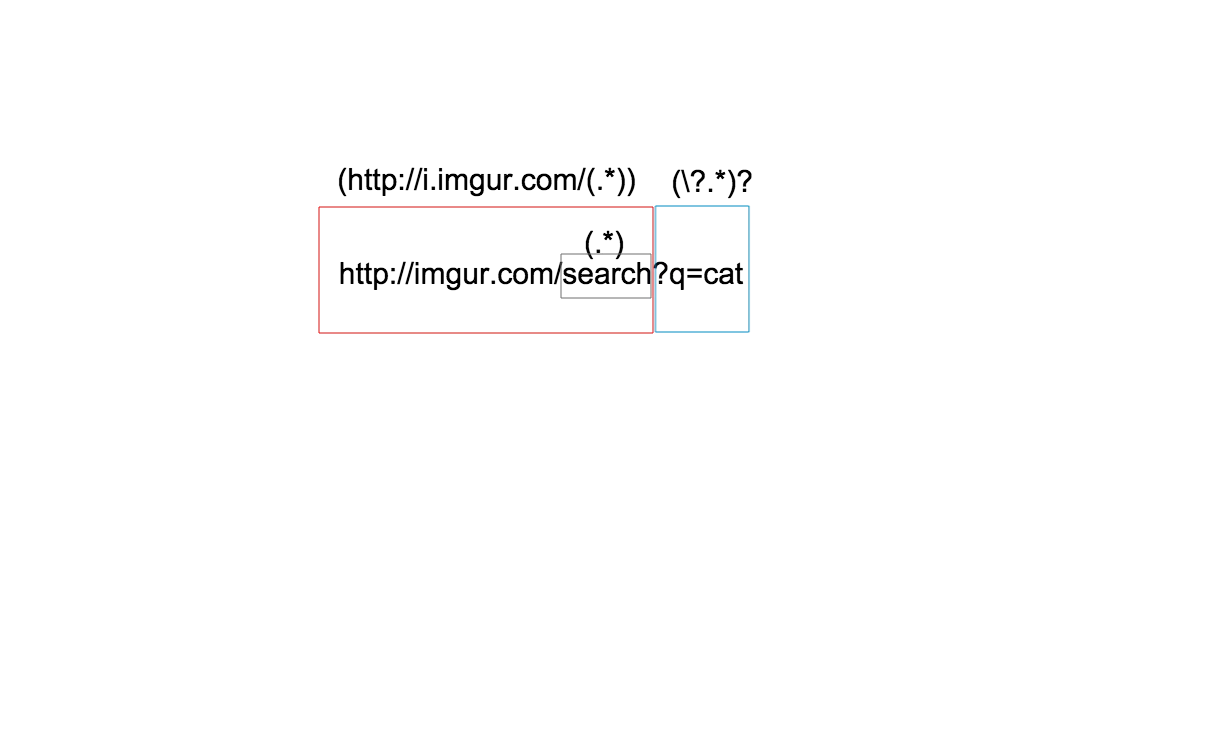
(http://i.imgur.com/(.*))(\?.*)?
第一个捕获组 (http://i.imgur.com/(.*)) 表示字符串应以 http://i.imgur.com/ 开头,后跟任意数量的字符 (.*) (这是一种不好的正则表达式写法,不建议使用)。 (.*) 也是第二个捕获组。
第三个捕获组 (\?.*) 表示该字符串部分必须以 ? 开始,然后包含任意数量的任何字符,如上所述。
最后的 ? 表示最后一个捕获组是可选的。
编辑: 然后可以将这些组用作:
p = re.compile(r'(http://i.imgur.com/(.*))(\?.*)?')
m = p.match('ab')
m.group(0);
m.group(2);
(http://i.imgur.com/([A-z0-9\-]+))(\?[[^/]+*)?
[A-z0-9\-]+限制为字母数字字符
[^/]排除/