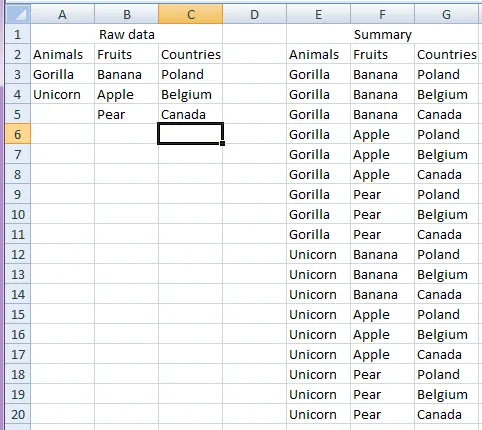
我有3个不同的数据集合(分别在不同的列中)
- A列有5种动物
- B列有1000种水果
- C列有10个国家
基于这3个数据集合,我想要得到5×1000×10共50,000个对应元素,它们将出现在E、F、G列中(即每一个动物与每一种水果和每一个国家都相应对应)。
手动复制并粘贴数值可能会耗费很长时间。是否有VBA代码或通用公式可以自动化执行?
是否有针对无限量数据集的通用公式,类似上面所示的例子?如果有不清楚的地方,请告诉我。
以下是较小的数据示例,以及结果应如何显示:
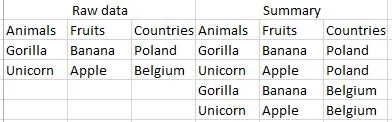
我有3个不同的数据集合(分别在不同的列中)
基于这3个数据集合,我想要得到5×1000×10共50,000个对应元素,它们将出现在E、F、G列中(即每一个动物与每一种水果和每一个国家都相应对应)。
手动复制并粘贴数值可能会耗费很长时间。是否有VBA代码或通用公式可以自动化执行?
是否有针对无限量数据集的通用公式,类似上面所示的例子?如果有不清楚的地方,请告诉我。
以下是较小的数据示例,以及结果应如何显示:
我理解你的意思是要让这个程序适用于任意列数和每列中任意数量的条目。使用一些变量数组可以提供必要的维度,以计算每个值的重复周期。
Option Explicit
Sub main()
Call for_each_in_others(rDATA:=Worksheets("Sheet3").Range("A3"), bHDR:=True)
End Sub
Sub for_each_in_others(rDATA As Range, Optional bHDR As Boolean = False)
Dim v As Long, w As Long
Dim iINCROWS As Long, iMAXROWS As Long, sErrorRng As String
Dim vVALs As Variant, vTMPs As Variant, vCOLs As Variant
On Error GoTo bm_Safe_Exit
appTGGL bTGGL:=False
With rDATA.Parent
With rDATA(1).CurrentRegion
'Debug.Print rDATA(1).Row - .Cells(1).Row
With .Resize(.Rows.Count - (rDATA(1).Row - .Cells(1).Row), .Columns.Count).Offset(2, 0)
sErrorRng = .Address(0, 0)
vTMPs = .Value2
ReDim vCOLs(LBound(vTMPs, 2) To UBound(vTMPs, 2))
iMAXROWS = 1
'On Error GoTo bm_Output_Exceeded
For w = LBound(vTMPs, 2) To UBound(vTMPs, 2)
vCOLs(w) = Application.CountA(.Columns(w))
iMAXROWS = iMAXROWS * vCOLs(w)
Next w
'control excessive or no rows of output
If iMAXROWS > Rows.Count Then
GoTo bm_Output_Exceeded
ElseIf .Columns.Count = 1 Or iMAXROWS = 0 Then
GoTo bm_Nothing_To_Do
End If
On Error GoTo bm_Safe_Exit
ReDim vVALs(LBound(vTMPs, 1) To iMAXROWS, LBound(vTMPs, 2) To UBound(vTMPs, 2))
iINCROWS = 1
For w = LBound(vVALs, 2) To UBound(vVALs, 2)
iINCROWS = iINCROWS * vCOLs(w)
For v = LBound(vVALs, 1) To UBound(vVALs, 1)
vVALs(v, w) = vTMPs((Int(iINCROWS * ((v - 1) / UBound(vVALs, 1))) Mod vCOLs(w)) + 1, w)
Next v
Next w
End With
End With
.Cells(2, UBound(vVALs, 2) + 2).Resize(1, UBound(vVALs, 2) + 2).EntireColumn.Delete
If bHDR Then
rDATA.Cells(1, 1).Offset(-1, 0).Resize(1, UBound(vVALs, 2)).Copy _
Destination:=rDATA.Cells(1, UBound(vVALs, 2) + 2).Offset(-1, 0)
End If
rDATA.Cells(1, UBound(vVALs, 2) + 2).Resize(UBound(vVALs, 1), UBound(vVALs, 2)) = vVALs
End With
GoTo bm_Safe_Exit
bm_Nothing_To_Do:
MsgBox "There is not enough data in " & sErrorRng & " to perform expansion." & Chr(10) & _
"This could be due to a single column of values or one or more blank column(s) of values." & _
Chr(10) & Chr(10) & "There is nothing to expand.", vbInformation, _
"Single or No Column of Raw Data"
GoTo bm_Safe_Exit
bm_Output_Exceeded:
MsgBox "The number of expanded values created from " & sErrorRng & _
" (" & Format(iMAXROWS, "\> #, ##0") & " rows × " & UBound(vTMPs, 2) & _
" columns) exceeds the rows available (" & Format(Rows.Count, "#, ##0") & ") on this worksheet.", vbCritical, _
"Too Many Entries"
bm_Safe_Exit:
appTGGL
End Sub
Sub appTGGL(Optional bTGGL As Boolean = True)
Application.EnableEvents = bTGGL
Application.ScreenUpdating = bTGGL
End Sub
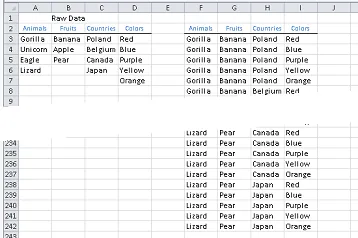
典型的非连接选择SQL语句示例,返回列出表格的所有组合结果的笛卡尔积。
SQL数据库解决方案
只需将动物、水果、国家作为单独的表格导入任何SQL数据库,如MS Access、SQLite、MySQL等,然后列出不包括连接的表格,包括隐式(WHERE)和显式(JOIN)连接:
SELECT Animals.Animal, Fruits.Fruit, Countries.Country
FROM Animals, Countries, Fruits;
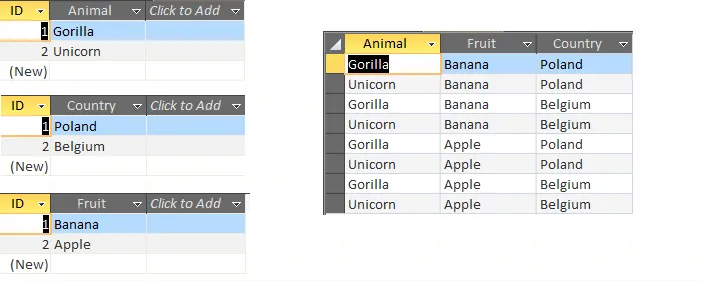
Excel解决方案
与在VBA中运行非连接SQL语句相同的概念,使用ODBC连接到包含动物、国家和水果范围的工作簿。在此示例中,每个数据分组都在其自己的同名工作表中。
Sub CrossJoinQuery()
Dim conn As Object
Dim rst As Object
Dim sConn As String, strSQL As String
Set conn = CreateObject("ADODB.Connection")
Set rst = CreateObject("ADODB.Recordset")
sConn = "Driver={Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)};" _
& "DBQ=C:\Path To\Excel\Workbook.xlsx;"
conn.Open sConn
strSQL = "SELECT * FROM [Animals$A1:A3], [Fruits$A1:A3], [Countries$A1:A3] "
rst.Open strSQL, conn
Range("A1").CopyFromRecordset rst
rst.Close
conn.Close
Set rst = Nothing
Set conn = Nothing
End Sub
我解决这个问题的第一种方法与@Jeeped发布的方法类似:
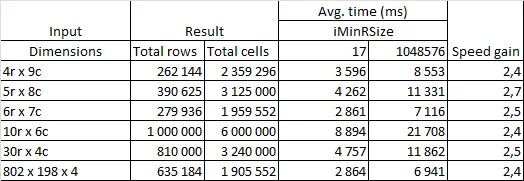
使用MicroTimer,我计算了上述算法的每个部分所需的平均时间。对于更大的输入数据,第3部分需要90%-93%的总执行时间。
下面是我尝试提高写入工作表速度的努力。我定义了一个常量iMinRSize=17。一旦可以用相同的值填充超过iMinRSize连续行,代码就停止填充数组并直接写入工作表范围。
Sub CrossJoin(rSrc As Range, rTrg As Range)
Dim vSrc() As Variant, vTrgPart() As Variant
Dim iLengths() As Long
Dim iCCnt As Integer, iRTrgCnt As Long, iRSrcCnt As Long
Dim i As Integer, j As Long, k As Long, l As Long
Dim iStep As Long
Const iMinRSize As Long = 17
Dim iArrLastC As Integer
On Error GoTo CleanUp
Application.ScreenUpdating = False
Application.EnableEvents = False
vSrc = rSrc.Value2
iCCnt = UBound(vSrc, 2)
iRSrcCnt = UBound(vSrc, 1)
iRTrgCnt = 1
iArrLastC = 1
ReDim iLengths(1 To iCCnt)
For i = 1 To iCCnt
j = iRSrcCnt
While (j > 0) And IsEmpty(vSrc(j, i))
j = j - 1
Wend
iLengths(i) = j
iRTrgCnt = iRTrgCnt * iLengths(i)
If (iRTrgCnt < iMinRSize) And (iArrLastC < iCCnt) Then iArrLastC = iArrLastC + 1
Next i
If (iRTrgCnt > 0) And (rTrg.row + iRTrgCnt - 1 <= rTrg.Parent.Rows.Count) Then
ReDim vTrgPart(1 To iRTrgCnt, 1 To iArrLastC)
iStep = 1
For i = 1 To iArrLastC
k = 0
For j = 1 To iRTrgCnt Step iStep
k = k + 1
If k > iLengths(i) Then k = 1
For l = j To j + iStep - 1
vTrgPart(l, i) = vSrc(k, i)
Next l
Next j
iStep = iStep * iLengths(i)
Next i
rTrg.Resize(iRTrgCnt, iArrLastC) = vTrgPart
For i = iArrLastC + 1 To iCCnt
k = 0
For j = 1 To iRTrgCnt Step iStep
k = k + 1
If k > iLengths(i) Then k = 1
rTrg.Resize(iStep).Offset(j - 1, i - 1).Value2 = vSrc(k, i)
Next j
iStep = iStep * iLengths(i)
Next i
End If
CleanUp:
Application.ScreenUpdating = True
Application.EnableEvents = False
End Sub
Sub test()
CrossJoin Range("a2:f10"), Range("k2")
End Sub
iMinRSize设置为Rows.Count,所有数据都会被写入数组。以下是我的样本测试结果:
 如果输入的列中具有最大行数的列首先出现,代码的运行效果最佳,但将代码修改为排列列并以正确的顺序处理也不是什么大问题。
如果输入的列中具有最大行数的列首先出现,代码的运行效果最佳,但将代码修改为排列列并以正确的顺序处理也不是什么大问题。=CEILING(ROWS($1:1)/(ROWS(Fruits)*ROWS(Countries)),1)
将生成一个从1开始的数字序列,该序列的重复次数为水果 * 国家的数量 -- 这给出了每个动物所需要的行数。
=MOD(CEILING(ROWS($1:1)/ROWS(Countries),1)-1,ROWS(Fruits))+1
=MOD(ROWS($1:1)-1,ROWS(Countries))+1))
生成一个重复序列1..n,其中n是国家的数量。
将这些放入公式中(进行一些错误检查)
D3: =IFERROR(INDEX(Animals,CEILING(ROWS($1:1)/(ROWS(Fruits)*ROWS(Countries)),1)),"")
E3: =IF(E3="","",INDEX(Fruits,MOD(CEILING(ROWS($1:1)/ROWS(Countries),1)-1,ROWS(Fruits))+1))
F3: =IF(E3="","",INDEX(Countries,MOD(ROWS($1:1)-1,ROWS(Countries))+1))
1;但是通过从 ROW()-1 开始,只有在公式的第一行位于第二行时才会返回 1。如果用户决定移动它 -- 插入更多标题行;或者将结果放在工作表上的其他位置,ROW()-1 将不得不手动更改以进行补偿。 - Ron Rosenfeld实际上,我想修改我的旧答案。但是,我的新答案与旧答案完全不同。因为旧答案针对特定列,而这个答案针对通用列。回答旧问题后,提问者提出了他想在通用列中完成的新要求。对于固定列,我们可以考虑固定循环,对于无限列,我们需要从另一种方式考虑。所以,我也这样做了。SO用户也可以看到代码差异,我认为这对初学者会有帮助。
这段新代码并不像旧代码那么简单。如果您想清楚地了解代码,请逐行调试代码。
不要担心代码。我已经逐步测试过它。它对我来说完美运行。如果对您没有用,请让我知道。唯一的问题是,这段代码可能会导致空行(没有数据)出错。因为目前我还没有添加检查。
这是我对您的问题的通用方法:
Public Sub matchingCell()
Dim startRawColumn, endRawColumn, startResultColumn, endResultColumn, startRow As Integer
Dim index, row, column, containerIndex, tempIndex As Integer
Dim columnCount, totalCount, timesCount, matchingCount, tempCount As Integer
Dim isExist As Boolean
Dim arrayContainer() As Variant
'Actually, even it is for universal, we need to know start column and end column of raw data.
'And also start row. And start column for write result.
'I set them for my test data.
'You need to modify them(startRawColumn, endRawColumn, startRow, startResultColumn).
'Set the start column and end column for raw data
startRawColumn = 1
endRawColumn = 3
'Set the start row for read data and write data
startRow = 2
'Set the start column for result data
startResultColumn = 4
'Get no of raw data column
columnCount = endRawColumn - startRawColumn
'Set container index
containerIndex = 0
'Re-create array container for count of column
ReDim arrayContainer(0 To columnCount)
With Sheets("sheetname")
'Getting data from sheet
'Loop all column for getting data of each column
For column = startRawColumn To endRawColumn Step 1
'Create tempArray for column
Dim tempArray() As Variant
'Reset startRow
row = startRow
'Reset index
index = 0
'Here is one things. I looped until to blank.
'If you want anymore, you can modify the looping type.
'Don't do any changes to main body of looping.
'Loop until the cell is blank
Do While .Cells(row, column) <> ""
'Reset isExist flag
isExist = False
'Remove checking for no data
If index > 0 Then
'Loop previous data for duplicate checking
For tempIndex = 0 To index - 1 Step 1
'If found, set true to isExist and stop loop
If tempArray(tempIndex) = .Cells(row, column) Then
isExist = True
Exit For
End If
Next tempIndex
End If
'If there is no duplicate data, store data
If Not isExist Then
'Reset tempArray
ReDim Preserve tempArray(index)
tempArray(index) = .Cells(row, column)
'Increase index
index = index + 1
End If
'Increase row
row = row + 1
Loop
'Store column with data
arrayContainer(containerIndex) = tempArray
'Increase container index
containerIndex = containerIndex + 1
Next column
'Now, we got all data column including data which has no duplicate
'Show result data on sheet
'Getting the result row count
totalCount = 1
'Get result row count
For tempIndex = 0 To UBound(arrayContainer) Step 1
totalCount = totalCount * (UBound(arrayContainer(tempIndex)) + 1)
Next tempIndex
'Reset timesCount
timesCount = 1
'Get the last column for result
endResultColumn = startResultColumn + columnCount
'Loop array container
For containerIndex = UBound(arrayContainer) To 0 Step -1
'Getting the counts for looping
If containerIndex = UBound(arrayContainer) Then
duplicateCount = 1
timesCount = totalCount / (UBound(arrayContainer(containerIndex)) + 1)
Else
duplicateCount = duplicateCount * (UBound(arrayContainer(containerIndex + 1)) + 1)
timesCount = timesCount / (UBound(arrayContainer(containerIndex)) + 1)
End If
'Reset the start row
row = startRow
'Loop timesCount
For countIndex = 1 To timesCount Step 1
'Loop data array
For index = 0 To UBound(arrayContainer(containerIndex)) Step 1
'Loop duplicateCount
For tempIndex = 1 To duplicateCount Step 1
'Write data to cell
.Cells(row, endResultColumn) = arrayContainer(containerIndex)(index)
'Increase row
row = row + 1
Next tempIndex
Next index
Next countIndex
'Increase result column index
endResultColumn = endResultColumn - 1
Next containerIndex
End With
End Sub
Option Explicit,所以我不得不声明 Dim duplicateCount As Long, countIndex As Long。我也得到了一个两列输出,但这可能是我的样本数据;我稍后会更深入地研究这个问题。 - user4039065Option Explicit的习惯。所以,我忘记了声明。使用Option Explicit是一个非常好的习惯。我添加了一些声明。并且我修改了循环开始点来获取总行数,因为我在反复测试时发现了一个错误。感谢您的建议。 - R.KatnaanColumnProducts Range("A:C"), Range("E1")
'the following function takes a collection of arrays of strings
'and returns a variant array of tab-delimited strings which
'comprise the (tab-delimited) cartesian products of
'the arrays in the collection
Function CartesianProduct(ByVal Arrays As Collection) As Variant
Dim i As Long, j As Long, k As Long, m As Long, n As Long
Dim head As Variant
Dim tail As Variant
Dim product As Variant
If Arrays.Count = 1 Then
CartesianProduct = Arrays.Item(1)
Exit Function
Else
head = Arrays.Item(1)
Arrays.Remove 1
tail = CartesianProduct(Arrays)
m = UBound(head)
n = UBound(tail)
ReDim product(1 To m * n)
k = 1
For i = 1 To m
For j = 1 To n
product(k) = head(i) & vbTab & tail(j)
k = k + 1
Next j
Next i
CartesianProduct = product
End If
End Function
Sub ColumnProducts(data As Range, output As Range)
Dim Arrays As New Collection
Dim strings As Variant, product As Variant
Dim i As Long, j As Long, n As Long, numRows As Long
Dim col As Range, cell As Range
Dim outRange As Range
numRows = Range("A:A").Rows.Count
For Each col In data.Columns
n = col.EntireColumn.Cells(numRows).End(xlUp).Row
i = col.Cells(1).Row
ReDim strings(1 To n - i + 1)
For j = 1 To n - i + 1
strings(j) = col.Cells(i + j - 1)
Next j
Arrays.Add strings
Next col
product = CartesianProduct(Arrays)
n = UBound(product)
Set outRange = Range(output, output.Offset(n - 1))
outRange.Value = Application.WorksheetFunction.Transpose(product)
outRange.TextToColumns Destination:=output, DataType:=xlDelimited, Tab:=True
End Sub
.Transpose操作类型不匹配。转置具有远远低于现代工作表限制的限制(请参见此处)。 - user4039065好的,所以您只需要一个所有可能组合的列表。这是我会做的:
Public Sub matchingCell()
Dim animalRow, fruitRow, countryRow, checkRow, resultRow As Long
Dim isExist As Boolean
'Set the start row
animalRow = 2
resultRow = 2
'Work with data sheet
With Sheets("sheetname")
'Loop until animals column is blank
Do While .Range("A" & animalRow) <> ""
'Set the start row
fruitRow = 2
'Loop until fruits column is blank
Do While .Range("B" & fruitRow) <> ""
'Set the start row
countryRow = 2
'Loop until country column is blank
Do While .Range("C" & countryRow) <> ""
'Set the start row
checkRow = 2
'Reset flag
isExist = False
'Checking for duplicate row
'Loop all result row until D is blank
Do While .Range("D" & checkRow) <> ""
'If duplicate row found
If .Range("D" & checkRow) = .Range("A" & animalRow) And _
.Range("E" & checkRow) = .Range("B" & fruitRow) And _
.Range("F" & checkRow) = .Range("C" & countryRow) Then
'Set true for exist flag
isExist = True
End If
checkRow = checkRow + 1
Loop
'If duplicate row not found
If Not isExist Then
.Range("D" & resultRow) = .Range("A" & animalRow)
.Range("E" & resultRow) = .Range("B" & fruitRow)
.Range("F" & resultRow) = .Range("C" & countryRow)
'Increase resultRow
resultRow = resultRow + 1
End If
'Increase countryRow
countryRow = countryRow + 1
Loop
'Increase fruitRow
fruitRow = fruitRow + 1
Loop
'Increase fruitRow
animalRow = animalRow + 1
Loop
End With
End Sub
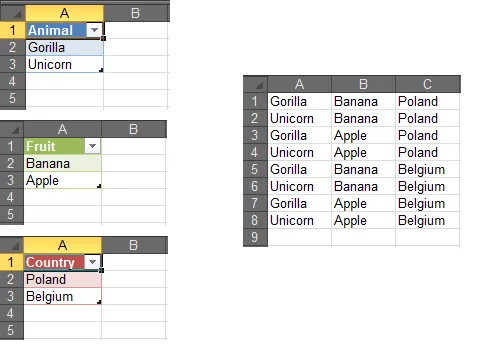
首先,您需要按照以下方式放置数据:如何放置您的数据
您将添加一个新列,在其中将频率相加。使用简单的递归公式。(例如:f3+f4)
为了将其带到Excel的现代版本和新功能Xlookup,我提出以下公式: =XLOOKUP(ROWS(K$2[a]:K2),$I$3:$I$8[b],$H$3:$H$8[c],"所有频率均满足",1,1
其中:
[a]是要显示数据的列。锁定数字很重要
[b]是添加在一起的频率
[c]是要在该频率下显示的元素
它是如何工作的?:
ROWS(K$2[a]:K2):将确定您列中的位置。在第一个单元格中,它将认为自己处于第一个位置。下一个单元格,它将是第二个,依此类推。
XLOOKUP部分:一旦我们有了位置,我们就会比较在ROWS()中找到的位置是否小于或等于第一个频率(为什么我们使用第一个1)。
如果是,它将显示与该频率相关联的元素。{kind=link}