我的问题很简单,但我发现很难抓住要点,所以请允许我逐步解释。
假设我有 N 个项目和 N 个对应的索引。
每个项目可以使用相应的索引进行加载。
def load_item(index: int) -> ItemType:
# Mostly just reading, but very slow.
return item
我还有一个函数,它接受两个(已加载的)项目并计算得分。
def calc_score(item_a: ItemType, item_b: ItemType) -> ScoreType:
# Much faster than load function.
return score
请注意,calc_score(a, b) == calc_score(b, a)。
我想做的是计算所有两个项目组合的分数,并找到至少一个组合给出最大分数。
可以按以下方式实施:
def dumb_solution(n: int) -> Tuple[int, int]:
best_score = 0
best_combination = None
for index_a, index_b in itertools.combinations(range(n), 2):
item_a = load_item(index_a)
item_b = load_item(index_b)
score = calc_score(item_a, item_b)
if score > best_score:
best_score = score
best_combination = (index_a, index_b)
return best_combination
然而,这个解决方案调用了
load_item 函数 2*C(N,2) = N*(N-1) 次,这是该函数的瓶颈。通过使用缓存可以解决这个问题。 然而不幸的是,物品太大了,无法将所有物品都保存在内存中。 因此,我们需要使用一个大小有限的缓存。
from functools import lru_cache
@lru_cache(maxsize=M)
def load(index: int) -> ItemType:
# Very slow process.
return item
请注意,
M(缓存大小)远小于N(约为N // 10到N // 2)。问题在于典型的组合序列对于LRU缓存不理想。
例如,当
N=6,M=3时,itertools.combinations生成以下序列,load_item函数的调用次数为17。[
(0, 1), # 1, 2
(0, 2), # -, 3
(0, 3), # -, 4
(0, 4), # -, 5
(0, 5), # -, 6
(1, 2), # 7, 8
(1, 3), # -, 9
(1, 4), # -, 10
(1, 5), # -, 11
(2, 3), # 12, 13
(2, 4), # -, 14
(2, 5), # -, 15
(3, 4), # 16, 17
(3, 5), # -, -
(4, 5), # -, -
]
然而,如果我将上述序列重新排列如下,通话次数将为10。
[
(0, 1), # 1, 2
(0, 2), # -, 3
(1, 2), # -, -
(0, 3), # -, 4
(2, 3), # -, -
(0, 4), # -, 5
(3, 4), # -, -
(0, 5), # -, 6
(4, 5), # -, -
(1, 4), # 7, -
(1, 5), # -, -
(1, 3), # -, 8
(3, 5), # -, -
(2, 5), # 9, -
(2, 4), # -, 10
]
问题:
如何生成一系列的2项组合,以最大化缓存命中率?
我尝试过的方法:
我想出的解决方案是优先考虑已经在缓存中的项目。
from collections import OrderedDict
def prioritizes_item_already_in_cache(n, cache_size):
items = list(itertools.combinations(range(n), 2))
cache = OrderedDict()
reordered = []
def update_cache(x, y):
cache[x] = cache[y] = None
cache.move_to_end(x)
cache.move_to_end(y)
while len(cache) > cache_size:
cache.popitem(last=False)
while items:
# Find a pair where both are cached.
for i, (a, b) in enumerate(items):
if a in cache and b in cache:
reordered.append((a, b))
update_cache(a, b)
del items[i]
break
else:
# Find a pair where one of them is cached.
for i, (a, b) in enumerate(items):
if a in cache or b in cache:
reordered.append((a, b))
update_cache(a, b)
del items[i]
break
else:
# Cannot find item in cache.
a, b = items.pop(0)
reordered.append((a, b))
update_cache(a, b)
return reordered
对于N=100,M=10,这个序列导致了1660次调用,大约是典型序列的1/3。对于N=100,M=50,只有155次调用。所以我认为这是一个有前途的方法。
不幸的是,这个函数对于大的N来说太慢且无用。我无法完成N=1000的计算,但实际数据达到数万。此外,它没有考虑在找不到缓存项时如何选择项目。因此,即使它很快,理论上也很难说它是最佳解决方案(请注意我的问题不是如何使上述函数更快)。
(编辑)这里是包括每个人的答案、测试和基准代码的完整代码。
import functools
import itertools
import math
import time
from collections import Counter, OrderedDict
from itertools import chain, combinations, product
from pathlib import Path
from typing import Callable, Iterable, Tuple
import joblib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from PIL import Image, ImageDraw
ItemType = int
ScoreType = int
def load_item(index: int) -> ItemType:
return int(index)
def calc_score(item_a: ItemType, item_b: ItemType) -> ScoreType:
return abs(item_a - item_b)
class LRUCacheWithCounter:
def __init__(self, maxsize: int):
def wrapped_func(key):
self.load_count += 1
return load_item(key)
self.__cache = functools.lru_cache(maxsize=maxsize)(wrapped_func)
self.load_count = 0
def __call__(self, key: int) -> int:
return self.__cache(key)
def basic_loop(iterator: Iterable[Tuple[int, int]], cached_load: Callable[[int], int]):
best_score = 0
best_combination = None
for i, j in iterator:
a = cached_load(i)
b = cached_load(j)
score = calc_score(a, b)
if score > best_score:
best_score = score
best_combination = (i, j)
return best_score, best_combination
def baseline(n, _):
return itertools.combinations(range(n), 2)
def prioritizes(n, cache_size):
items = list(itertools.combinations(range(n), 2))
cache = OrderedDict()
reordered = []
def update_cache(x, y):
cache[x] = cache[y] = None
cache.move_to_end(x)
cache.move_to_end(y)
while len(cache) > cache_size:
cache.popitem(last=False)
while items:
# Find a pair where both are cached.
for i, (a, b) in enumerate(items):
if a in cache and b in cache:
reordered.append((a, b))
update_cache(a, b)
del items[i]
break
else:
# Find a pair where one of them is cached.
for i, (a, b) in enumerate(items):
if a in cache or b in cache:
reordered.append((a, b))
update_cache(a, b)
del items[i]
break
else:
# Cannot find item in cache.
a, b = items.pop(0)
reordered.append((a, b))
update_cache(a, b)
return reordered
def Matt_solution(n: int, cache_size: int) -> Iterable[Tuple[int, int]]:
dest = []
def findPairs(lo1: int, n1: int, lo2: int, n2: int):
if n1 < 1 or n2 < 1:
return
if n1 == 1:
for i in range(max(lo1 + 1, lo2), lo2 + n2):
dest.append((lo1, i))
elif n2 == 1:
for i in range(lo1, min(lo1 + n1, lo2)):
dest.append((i, lo2))
elif n1 >= n2:
half = n1 // 2
findPairs(lo1, half, lo2, n2)
findPairs(lo1 + half, n1 - half, lo2, n2)
else:
half = n2 // 2
findPairs(lo1, n1, lo2, half)
findPairs(lo1, n1, lo2 + half, n2 - half)
findPairs(0, n, 0, n)
return dest
def Kelly_solution(n: int, cache_size: int) -> Iterable[Tuple[int, int]]:
k = cache_size // 2
r = range(n)
return chain.from_iterable(combinations(r[i : i + k], 2) if i == j else product(r[i : i + k], r[j : j + k]) for i in r[::k] for j in r[i::k])
def Kelly_solution2(n: int, cache_size: int) -> Iterable[Tuple[int, int]]:
k = cache_size - 2
r = range(n)
return chain.from_iterable(combinations(r[i : i + k], 2) if i == j else product(r[i : i + k], r[j : j + k]) for i in r[::k] for j in r[i::k])
def diagonal_block(lower, upper):
for i in range(lower, upper + 1):
for j in range(i + 1, upper + 1):
yield i, j
def strip(i_lower, i_upper, j_lower, j_upper):
for i in range(i_lower, i_upper + 1):
for j in range(j_lower, j_upper + 1):
yield i, j
def btilly_solution(n: int, cache_size: int):
i_lower = 0
i_upper = n - 1
k = cache_size - 2
is_asc = True
while i_lower <= i_upper:
# Handle a k*k block first. At the end that is likely loaded.
if is_asc:
upper = min(i_lower + k - 1, i_upper)
yield from diagonal_block(i_lower, upper)
j_lower = i_lower
j_upper = upper
i_lower = upper + 1
else:
lower = max(i_lower, i_upper - k + 1)
yield from diagonal_block(lower, i_upper)
j_lower = lower
j_upper = i_upper
i_upper = lower - 1
yield from strip(i_lower, i_upper, j_lower, j_upper)
is_asc = not is_asc
def btilly_solution2(n: int, cache_size: int):
k = cache_size - 2
for top in range(0, n, k):
bottom = top + k
# Diagonal part.
for y in range(top, min(bottom, n)): # Y-axis Top to Bottom
for x in range(y + 1, min(bottom, n)): # X-axis Left to Right
yield y, x
# Strip part.
# Stripping right to left works well when cache_size is very small, but makes little difference when it is not.
for x in range(n - 1, bottom - 1, -1): # X-axis Right to Left
for y in range(top, min(bottom, n)): # Y-axis Top to Bottom
yield y, x
def btilly_solution3(n: int, cache_size: int):
k = cache_size - 2
r = range(n)
for i in r[::k]:
yield from combinations(r[i : i + k], 2)
yield from product(r[i + k :], r[i : i + k])
def btilly_solution4(n: int, cache_size: int):
def parts():
k = cache_size - 2
r = range(n)
for i in r[::k]:
yield combinations(r[i : i + k], 2)
yield product(r[i + k :], r[i : i + k])
return chain.from_iterable(parts())
def plot(df, series, ignore, y, label, title):
df = df[df["name"].isin(series)]
# plt.figure(figsize=(10, 10))
for name, group in df.groupby("name"):
plt.plot(group["n"], group[y], label=name)
y_max = df[~df["name"].isin(ignore)][y].max()
plt.ylim(0, y_max * 1.1)
plt.xlabel("n")
plt.ylabel(label)
plt.title(title)
plt.legend(loc="upper left")
plt.tight_layout()
plt.grid()
plt.show()
def run(func, n, cache_ratio, output_dir: Path):
cache_size = int(n * cache_ratio / 100)
output_path = output_dir / f"{n}_{cache_ratio}_{func.__name__}.csv"
if output_path.exists():
return
started = time.perf_counter()
for a, b in func(n, cache_size):
pass
elapsed_iterate = time.perf_counter() - started
# test_combinations(func(n, cache_size), n)
started = time.perf_counter()
cache = LRUCacheWithCounter(cache_size)
basic_loop(iterator=func(n, cache_size), cached_load=cache)
elapsed_cache = time.perf_counter() - started
output_path.write_text(f"{func.__name__},{n},{cache_ratio},{cache_size},{cache.load_count},{elapsed_iterate},{elapsed_cache}")
def add_lower_bound(df):
def calc_lower_bound(ni, mi):
n = ni
m = n * mi // 100
return m + math.ceil((math.comb(n, 2) - math.comb(m, 2)) / (m - 1))
return pd.concat(
[
df,
pd.DataFrame(
[
{"name": "lower_bound", "n": ni, "m": mi, "count": calc_lower_bound(ni, mi)}
for ni, mi in itertools.product(df["n"].unique(), df["m"].unique())
]
),
]
)
def benchmark(output_dir: Path):
log_dir = output_dir / "log"
log_dir.mkdir(parents=True, exist_ok=True)
candidates = [
baseline,
prioritizes,
Matt_solution,
Kelly_solution,
Kelly_solution2,
btilly_solution,
btilly_solution2,
btilly_solution3,
btilly_solution4,
]
nc = np.linspace(100, 500, num=9).astype(int)
# nc = np.linspace(500, 10000, num=9).astype(int)[1:]
# nc = np.linspace(10000, 100000, num=9).astype(int).tolist()[1:]
print(nc)
mc = np.linspace(10, 50, num=2).astype(int)
print(mc)
joblib.Parallel(n_jobs=1, verbose=5, batch_size=1)([joblib.delayed(run)(func, ni, mi, log_dir) for ni in nc for mi in mc for func in candidates])
def plot_graphs(output_dir: Path):
log_dir = output_dir / "log"
results = []
for path in log_dir.glob("*.csv"):
results.append(path.read_text().strip())
(output_dir / "stat.csv").write_text("\n".join(results))
df = pd.read_csv(output_dir / "stat.csv", header=None, names=["name", "n", "m", "size", "count", "time", "time_full"])
df = add_lower_bound(df)
df = df.sort_values(["name", "n", "m"])
for m in [10, 50]:
plot(
df[df["m"] == m],
series=[
baseline.__name__,
prioritizes.__name__,
Matt_solution.__name__,
Kelly_solution.__name__,
Kelly_solution2.__name__,
btilly_solution.__name__,
"lower_bound",
],
ignore=[
baseline.__name__,
prioritizes.__name__,
],
y="count",
label="load count",
title=f"cache_size = {m}% of N",
)
plot(
df[df["m"] == 10],
series=[
baseline.__name__,
prioritizes.__name__,
Matt_solution.__name__,
Kelly_solution.__name__,
Kelly_solution2.__name__,
btilly_solution.__name__,
btilly_solution2.__name__,
btilly_solution3.__name__,
btilly_solution4.__name__,
],
ignore=[
prioritizes.__name__,
Matt_solution.__name__,
],
y="time",
label="time (sec)",
title=f"cache_size = {10}% of N",
)
class LRUCacheForTest:
def __init__(self, maxsize: int):
self.cache = OrderedDict()
self.maxsize = maxsize
self.load_count = 0
def __call__(self, key: int) -> int:
if key in self.cache:
value = self.cache[key]
self.cache.move_to_end(key)
else:
if len(self.cache) == self.maxsize:
self.cache.popitem(last=False)
value = load_item(key)
self.cache[key] = value
self.load_count += 1
return value
def hit(self, i, j):
count = int(i in self.cache)
self(i)
count += int(j in self.cache)
self(j)
return count
def visualize():
# Taken from https://dev59.com/-1h2hooBIXSAPYfQKcDO#77024514 and modified.
n, m = 100, 30
func = btilly_solution2
pairs = func(n, m)
cache = LRUCacheForTest(m)
# Create the images, save as animated png.
images = []
s = 5
img = Image.new("RGB", (s * n, s * n), (255, 255, 255))
draw = ImageDraw.Draw(img)
colors = [(255, 0, 0), (255, 255, 0), (0, 255, 0)]
for step, (i, j) in enumerate(pairs):
draw.rectangle((s * j, s * i, s * j + s - 2, s * i + s - 2), colors[cache.hit(i, j)])
if not step % 17:
images.append(img.copy())
images += [img] * 40
images[0].save(f"{func.__name__}_{m}.gif", save_all=True, append_images=images[1:], optimize=False, duration=30, loop=0)
def test_combinations(iterator: Iterable[Tuple[int, int]], n: int):
# Note that this function is not suitable for large N.
expected = set(frozenset(pair) for pair in itertools.combinations(range(n), 2))
items = list(iterator)
actual = set(frozenset(pair) for pair in items)
assert len(actual) == len(items), f"{[item for item, count in Counter(items).items() if count > 1]}"
assert actual == expected, f"dup={actual - expected}, missing={expected - actual}"
def test():
n = 100 # N
cache_size = 30 # M
def run(func):
func(n, cache_size)
# Measure generation performance.
started = time.perf_counter()
for a, b in func(n, cache_size):
pass
elapsed = time.perf_counter() - started
# Test generated combinations.
test_combinations(func(n, cache_size), n)
# Measure cache hit (load count) performance.
cache = LRUCacheWithCounter(cache_size)
_ = basic_loop(iterator=func(n, cache_size), cached_load=cache)
print(f"{func.__name__}: {cache.load_count=}, {elapsed=}")
candidates = [
baseline,
prioritizes,
Matt_solution,
Kelly_solution,
Kelly_solution2,
btilly_solution,
btilly_solution2,
btilly_solution3,
btilly_solution4,
]
for f in candidates:
run(f)
def main():
test()
visualize()
output_dir = Path("./temp2")
benchmark(output_dir)
plot_graphs(output_dir)
if __name__ == "__main__":
main()
我对你不使用上述测试代码或更改
basic_loop或LRUCacheWithCounter的行为没有任何问题。附加说明:
- 不能使用邻居分数来修剪得分计算。 - 不能仅使用部分项目来修剪得分计算。 - 不可能猜测最佳组合将在哪里。 - 使用更快的媒体是一个选择,但我已经达到了我的极限,所以我正在寻找软件解决方案。
感谢您阅读完这篇长篇文章。
编辑:
感谢btilly的回答和Kelly的可视化帮助,我得出结论认为btilly的解决方案是最好的(可能也是最优的)。
以下是一个理论解释(尽管我对数学不太擅长,所以可能有错误)。
让N代表索引的数量,M代表缓存大小,C代表组合的数量(与math.comb相同)。
考虑一种情况,即缓存已满且无法再生成更多的组合而不加载。 如果此时添加一个新的索引,那么只能生成新添加的索引和缓存中剩余索引的组合。 这个模式在每次迭代中都成立。 因此,在缓存已满的情况下,每次加载可以生成的最大组合数为M - 1。
这个逻辑在缓存未满的情况下也成立。 如果当前缓存中有M'个索引,则下一个索引最多可以生成M'个组合。 随后的索引最多可以生成M' + 1个组合,依此类推。 总共,缓存满之前最多可以生成C(M,2)个组合。
因此,要生成
C(N,2) 个组合,至少需要 M 个负载来填充缓存,在缓存填满后,至少需要 (C(N,2) - C(M,2)) / (M - 1) 个负载。从上面可以看出,这个问题的负载计数复杂度为
Ω(N^2 / M)。
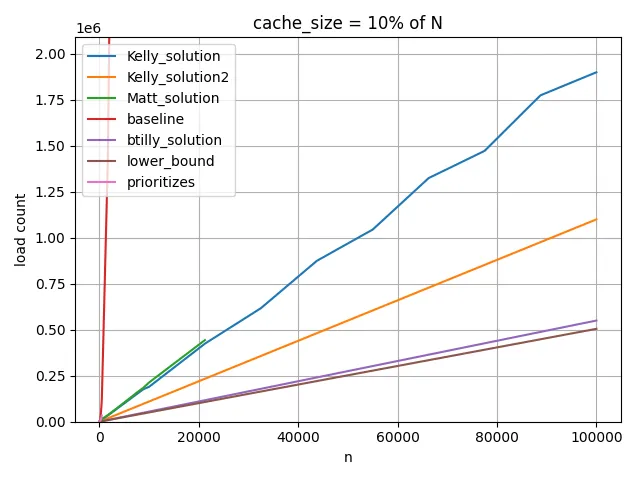
我已经在下面的图表中将这个公式作为一个下界进行了绘制。 请注意,它只是一个下界,并不能保证实际达到。
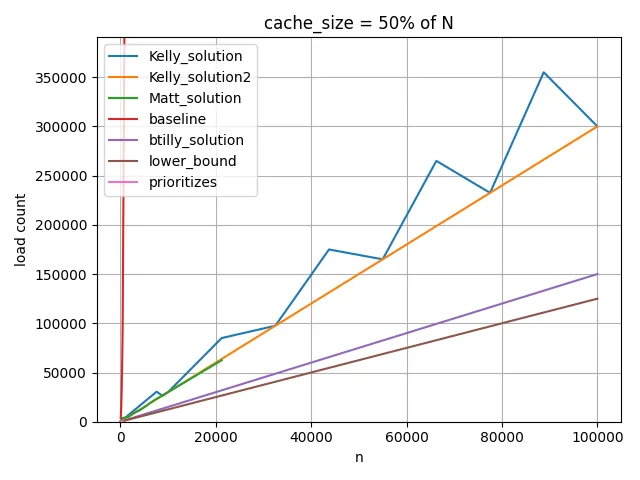
顺便提一下,Kelly的解决方案需要配置k以最大化其性能。 对于M = N的50%,大约是M * 2/3。 对于M = N的30%,大约是M * 5/6。 虽然我无法计算出具体数值。 作为一般配置,在下面的图表中的Kelly_solution2中,我使用k = M - 2(这不是最好的,但相对不错)。
对于M = N的10%:
M = 50% of N 的情况:
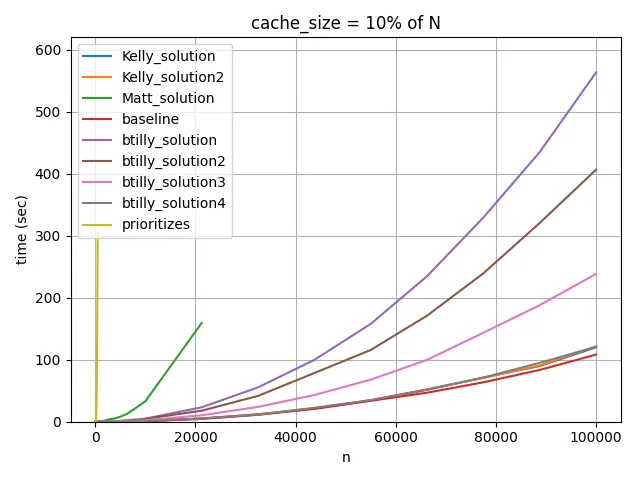
这里有一个动画,可视化了btilly_solution2的缓存命中率,由Kelly代码的修改版本组成。 每个像素代表一个组合,红色代表两个索引都加载的组合,黄色代表一个索引加载的组合,绿色代表两个索引都未加载的组合。

就这些。感谢所有参与的人。







calc_score的其他信息吗?你说calc_score(a, b) == calc_score(b, a),这非常好。也许calc_score还有其他很酷的特性。它能代表类似地理接近性吗?比如,如果(a, b)得分高,而(b, c)得分低,那么(a, c)的得分也会低吗?或者代表地理距离,如果(a, b)得分低,而(b, c)得分也低,那么(a, c)的得分也会低吗?也许满足三角不等式calc_score(a, b) + calc_score(b, c) >= calc_score(a, c)或者calc_score(a, c) >= abs(calc_score(a, b) - calc_score(b, c))? - Steffor index_a, index_b in ...:,也就是说,你没有保留对每个配对的引用。但是你的基准测试中的for _ in func(n, cache_size):却保留了引用,这会阻碍优化,使得某些解决方案看起来更慢。你可以使用deque(func(n, cache_size), 0)来替代你的循环,这样可以再次进行优化,并且比Python级别的循环开销更小。顺便问一下,我很好奇你是如何将我们的解决方案改成生成器的。这可能导致它们变慢。也许你的编辑最好作为一个答案,包含经过测试的代码。 - Kelly Bundyfor a, b in func(...)应该是最接近我的实际代码的写法,我将使用它重新运行基准测试。不过,我相信执行速度上的差异主要是由其他原因引起的,所以我认为整体情况不会有太大变化。 - ken