有没有通过终端命令查看任何显卡温度的方法。
已尝试使用应用了 sensors-detect 的 sensors 命令。但无法检测到例如 Nvidia 和 ATI 显卡的温度。
有没有通过终端命令查看任何显卡温度的方法。
已尝试使用应用了 sensors-detect 的 sensors 命令。但无法检测到例如 Nvidia 和 ATI 显卡的温度。
user@box:~$ nvidia-smi -q -d temperature
GPU 0:
Product Name : GeForce 210
PCI ID : a6510de
Temperature : 39 C
user@box:~$ nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader
39
是的,有一个命令。
检测传感器
首先,你必须搜索传感器:
sudo apt-get install lm-sensors
sudo sensors-detect
sudo service module-init-tools start
sudo /etc/init.d/module-init-tools start
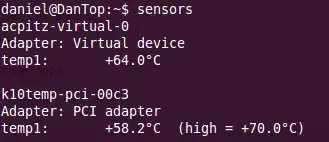
sensors
现在你应该看到类似这样的东西:
sudo apt-get install nvclock
sudo apt-get install libsensors3,然后再次按照我的步骤操作。 - omnidansudo aticonfig --initial,然后运行aticonfig --odgt --odgc来显示GPU温度和负载。 - KrisWebDevapt install lm-sensors,然后执行sensors-detect。 - noobninjasensors-detect还是sensors在我的原始16.04上都不起作用。我必须首先安装lm-sensors软件包(sudo apt-get install lm-sensors)。我有一张NVIDIA显卡。nvidia-settings可以正常工作,但我已经安装好了NVIDIA 340.X驱动程序。Psensor图形界面(https://launchpad.net/ubuntu/+source/psensor/1.1.3-2ubuntu5)非常好用。 - Manuel J. Diaznvidia-smi
+------------------------------------------------------+
| NVIDIA-SMI 3.295.71 Driver Version: 295.71 |
|-------------------------------+----------------------+----------------------+
| Nb. Name | Bus Id Disp. | Volatile ECC SB / DB |
| Fan Temp Power Usage /Cap | Memory Usage | GPU Util. Compute M. |
|===============================+======================+======================|
| 0. GeForce GT 520 | 0000:01:00.0 N/A | N/A N/A |
| N/A 52 C N/A N/A / N/A | 17% 169MB / 1023MB | N/A Default |
|-------------------------------+----------------------+----------------------|
| Compute processes: GPU Memory |
| GPU PID Process name Usage |
|=============================================================================|
| 0. Not Supported |
+-----------------------------------------------------------------------------+
watch命令和其他答案中给出的指令(例如@drgrog的)。例如,要每5秒刷新一次温度:watch -n 5 nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader
我最近发现了一个很酷的Gnome 3扩展。所以如果你在使用它,你可以安装这个扩展并在托盘中看到温度:
https://extensions.gnome.org/extension/541/nvidia-gpu-temperature-indicator/
#!/bin/bash
echo ""
echo "GPU Current Temp"
echo "Core 0: +$(( $((`nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader` * 9/5)) + 32))°F"
# nvidia-smi --query --display=TEMPERATURE | grep "GPU Current Temp" --color=none | sed 's/ //g'
echo ""
echo "CPU Current Temp"
sensors coretemp-isa-0000 -f | sed 's/(high.*//g' | tail -n +4 | sed 's/\.[0-9]//g'
coretemp-isa-0000更改为适用于它的标识符。
GPU Current Temp
Core 0: +120°F
CPU Current Temp
Core 0: +167°F
Core 1: +176°F
Core 2: +156°F
Core 3: +152°F
Core 4: +147°F
Core 5: +143°F
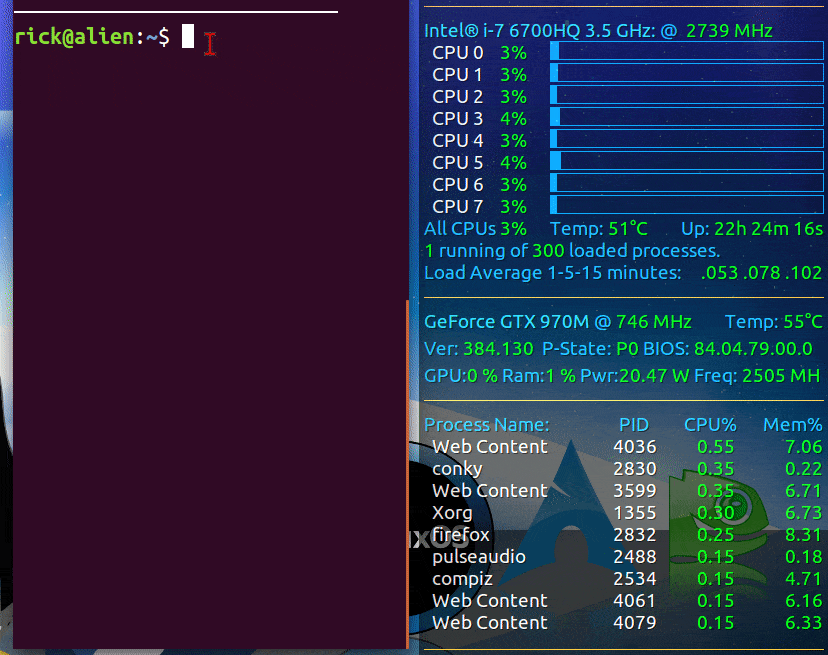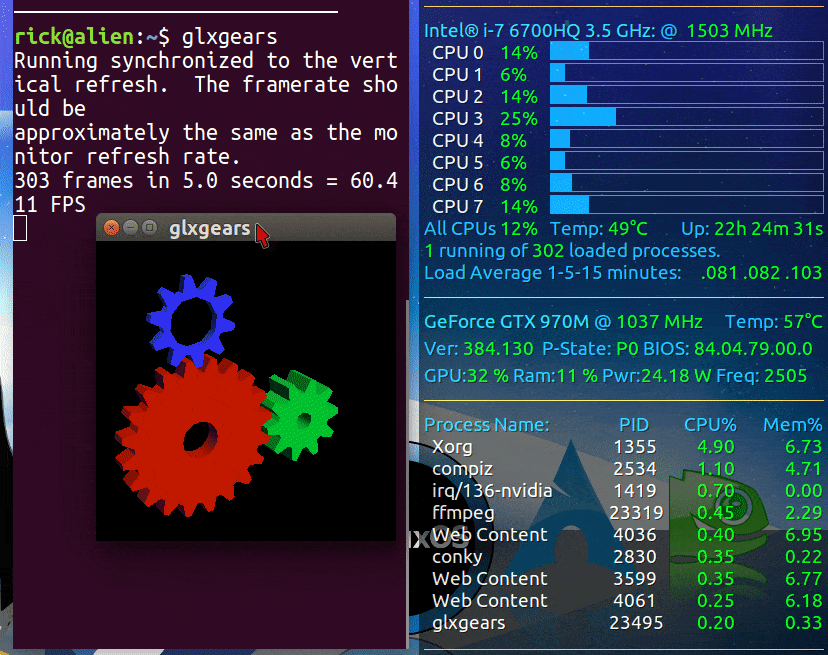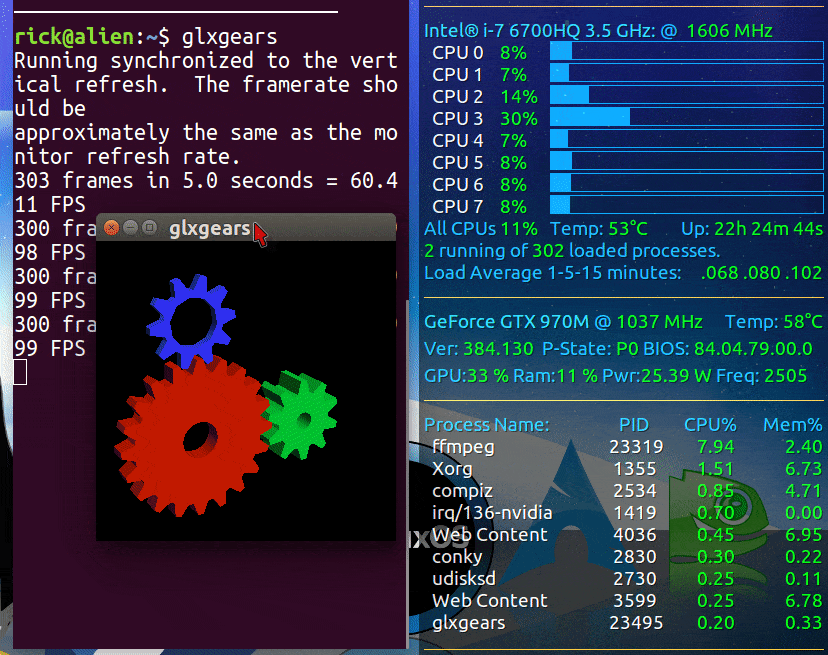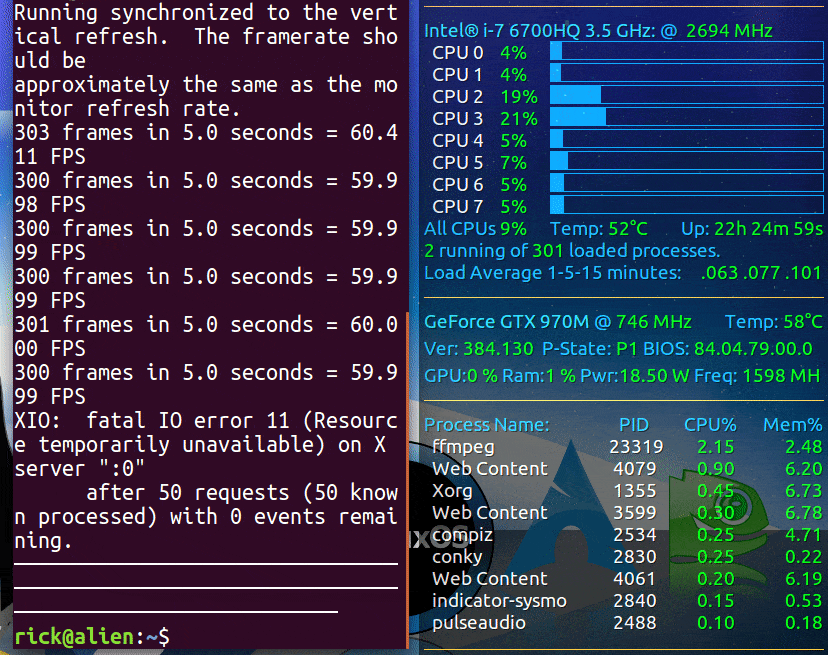
Conky是一款在Linux上广受欢迎的轻量级系统监视器,它对资源消耗很小,但功能强大。您可以使用它来持续显示GPU温度以及其他您想要跟踪的系统元素。
大多数搭载nVidia GPU的笔记本电脑还包含一个用于在电池供电时使用的Intel集成GPU(iGPU)。
我的Conky显示会根据选择的是Intel还是nVidia而改变。
以下是nVidia和Intel的GIF图像,在运行glxgears来测试GPU性能之前和之后。我将尝试找到比glxgears更具挑战性的图形测试。
当使用prime-select nvidia激活时,我的Conky显示如下:
当使用prime-select intel命令时,我的Conky显示如下:
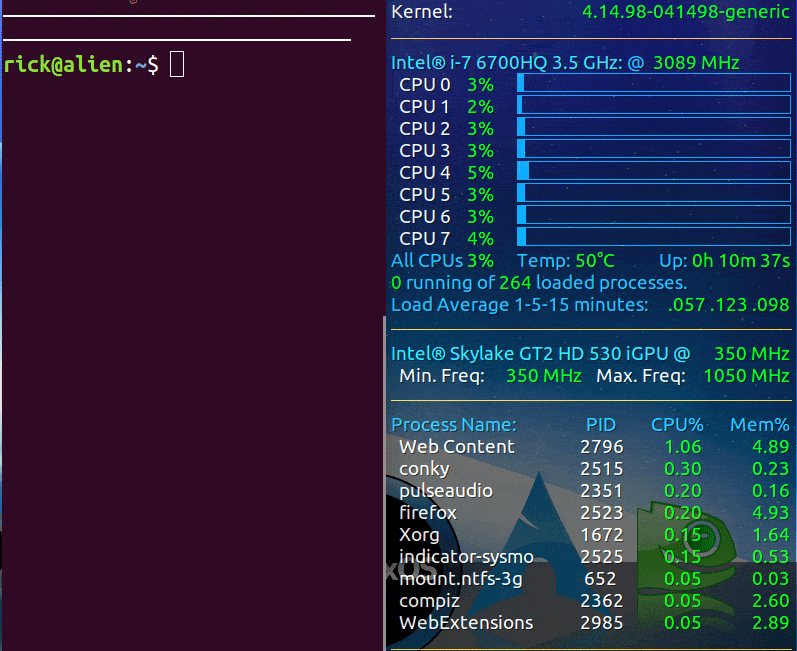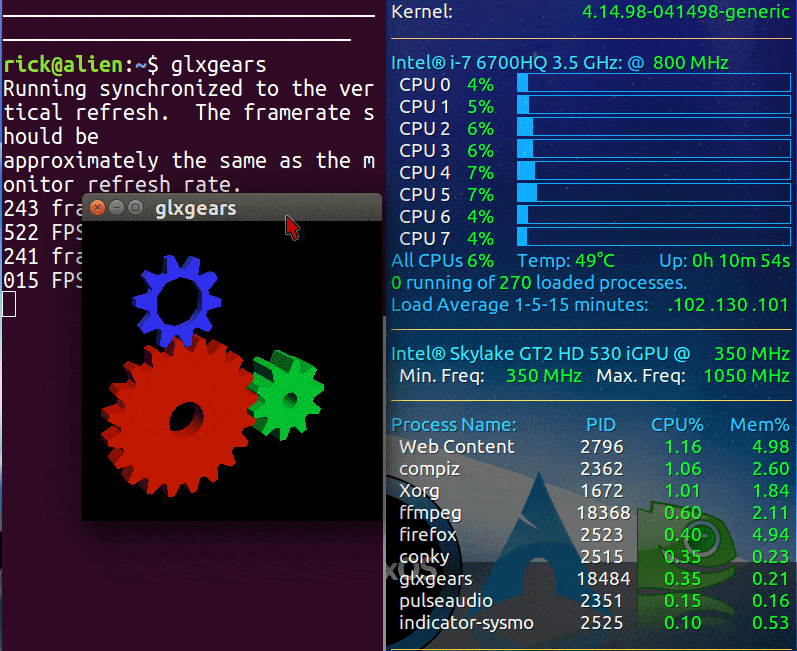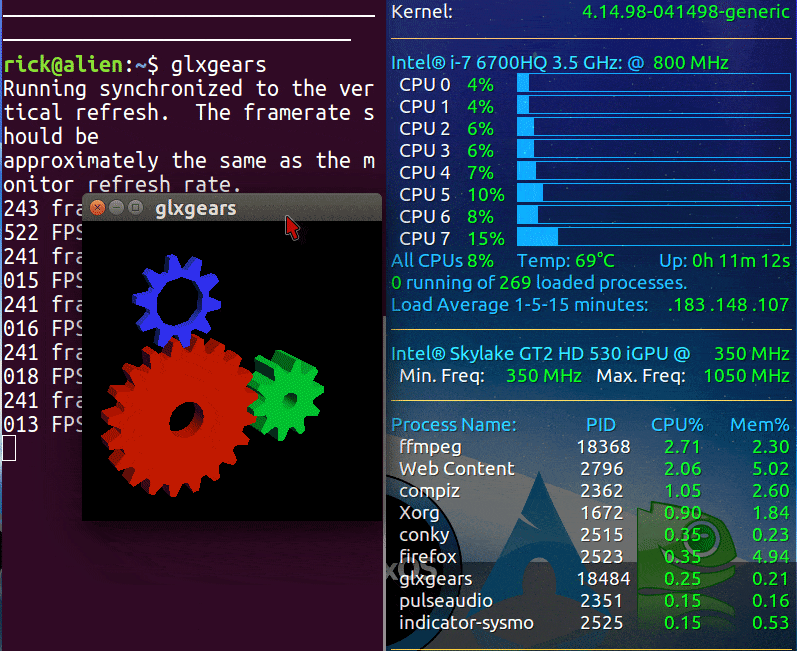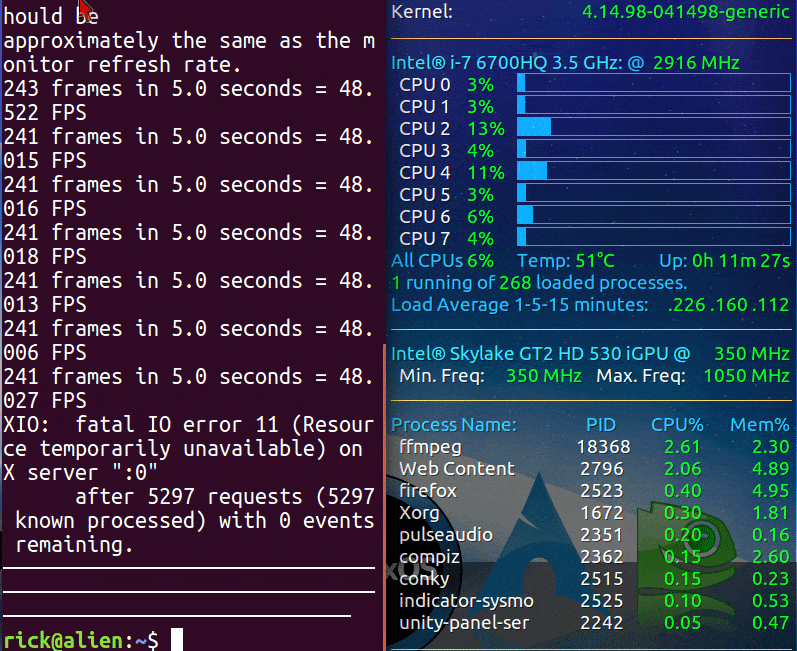
最初,Intel集成GPU(iGPU)的负载较低,CPU温度为49摄氏度。在运行glxgears后,CPU温度上升到73摄氏度!
以下是与上述相关的Conky代码:
#------------+
# Temperature|
#------------+
#${color1}All CPUs ${color green}${cpu}% ${goto 131}${color1}Temp: ${color green}${execpi .001 cat /sys/class/thermal/thermal_zone7/temp | cut -c1-2}°C ${alignr}${color1}Up: ${color green}$uptime
# Next line is for kernel >= 4.13.0-36-generic
${color1}All CPUs ${color green}${cpu}% ${goto 131}${color1}Temp: ${color green}${hwmon 1 temp 1}°C ${alignr}${color1}Up: ${color green}$uptime
# Next line is for temperature with Kerenel 4.4
#${color1}All CPUs ${color green}${cpu}% ${goto 131}${color1}Temp: ${color green}${hwmon 0 temp 1}°C ${alignr}${color1}Up: ${color green}$uptime
${color green}$running_processes ${color1}running of ${color green}$processes ${color1}loaded processes.
${color1}Load Average 1-5-15 minutes: ${alignr}${color green}${execpi .001 (awk '{printf "%s/", $1}' /proc/loadavg; grep -c processor /proc/cpuinfo;) | bc -l | cut -c1-4} ${execpi .001 (awk '{printf "%s/", $2}' /proc/loadavg; grep -c processor /proc/cpuinfo;) | bc -l | cut -c1-4} ${execpi .001 (awk '{printf "%s/", $3}' /proc/loadavg; grep -c processor /proc/cpuinfo;) | bc -l | cut -c1-4}
#------------+
# Intel iGPU |
#------------+
${color orange}${hr 1}${if_match "intel" == "${execpi 99999 prime-select query}"}
${color2}${voffset 5}Intel® Skylake GT2 HD 530 iGPU @${alignr}${color green}${execpi .001 (cat /sys/class/drm/card1/gt_cur_freq_mhz)} MHz
${color}${goto 13}Min. Freq:${goto 120}${color green}${execpi .001 (cat /sys/class/drm/card1/gt_min_freq_mhz)} MHz${color}${goto 210}Max. Freq:${alignr}${color green}${execpi .001 (cat /sys/class/drm/card1/gt_max_freq_mhz)} MHz
${color orange}${hr 1}${else}
#------------+
# Nvidia GPU |
#------------+
${color2}${voffset 5}${execpi .001 (nvidia-smi --query-gpu=gpu_name --format=csv,noheader)} ${color1}@ ${color green}${execpi .001 (nvidia-smi --query-gpu=clocks.sm --format=csv,noheader)} ${alignr}${color1}Temp: ${color green}${execpi .001 (nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader)}°C
${color1}${voffset 5}Ver: ${color green}${execpi .001 (nvidia-smi --query-gpu=driver_version --format=csv,noheader)} ${color1} P-State: ${color green}${execpi .001 (nvidia-smi --query-gpu=pstate --format=csv,noheader)} ${alignr}${color1}BIOS: ${color green}${execpi .001 (nvidia-smi --query-gpu=vbios_version --format=csv,noheader)}
${color1}${voffset 5}GPU:${color green}${execpi .001 (nvidia-smi --query-gpu=utilization.gpu --format=csv,noheader)} ${color1}Ram:${color green}${execpi .001 (nvidia-smi --query-gpu=utilization.memory --format=csv,noheader)} ${color1}Pwr:${color green}${execpi .001 (nvidia-smi --query-gpu=power.draw --format=csv,noheader)} ${alignr}${color1}Freq: ${color green}${execpi .001 (nvidia-smi --query-gpu=clocks.mem --format=csv,noheader)}
${color orange}${hr 1}${endif}
$HOME/.conkyrc中。我觉得这可能已经过时了。 - morhook
nvidia-settings -q gpucoretemp是另一种方法。 - Mateen Ulhaqnvidia-smi命令在核心被释放之前挂起时,您该如何处理?这样就打破了“熔毁警报”的目的?我只能使用市场上的温度传感器了吗?2080Ti GPU显然无法在100%使用率下读取自己的温度,并且不知道何时启动自己的风扇,也不会因为>135摄氏度的熔化温度而停止。看起来是时候解包他们的专有C二进制文件,并像暴雪游戏开发者那样操作了。干得好,NVIDIA,愤怒的噪音。 - Eric Leschinski